 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoryArena: Benchmarking Agent Memory in Interdependent Multi-Session Agentic Tasks
Feb 18, 2026Existing evaluations of agents with memory typically assess memorization and action in isolation. One class of benchmarks evaluates memorization by testing recall of past conversations or text but fails to capture how memory is used to guide future decisions. Another class focuses on agents acting in single-session tasks without the need for long-term memory. However, in realistic settings, memorization and action are tightly coupled: agents acquire memory while interacting with the environment, and subsequently rely on that memory to solve future tasks. To capture this setting, we introduce MemoryArena, a unified evaluation gym for benchmarking agent memory in multi-session Memory-Agent-Environment loops. The benchmark consists of human-crafted agentic tasks with explicitly interdependent subtasks, where agents must learn from earlier actions and feedback by distilling experiences into memory, and subsequently use that memory to guide later actions to solve the overall task. MemoryArena supports evaluation across web navigation, preference-constrained planning, progressive information search, and sequential formal reasoning, and reveals that agents with near-saturated performance on existing long-context memory benchmarks like LoCoMo perform poorly in our agentic setting, exposing a gap in current evaluations for agents with memory.
SPARC: Separating Perception And Reasoning Circuits for Test-time Scaling of VLMs
Feb 06, 2026Despite recent successes, test-time scaling - i.e., dynamically expanding the token budget during inference as needed - remains brittle for vision-language models (VLMs): unstructured chains-of-thought about images entangle perception and reasoning, leading to long, disorganized contexts where small perceptual mistakes may cascade into completely wrong answers. Moreover, expensive reinforcement learning with hand-crafted rewards is required to achieve good performance. Here, we introduce SPARC (Separating Perception And Reasoning Circuits), a modular framework that explicitly decouples visual perception from reasoning. Inspired by sequential sensory-to-cognitive processing in the brain, SPARC implements a two-stage pipeline where the model first performs explicit visual search to localize question-relevant regions, then conditions its reasoning on those regions to produce the final answer. This separation enables independent test-time scaling with asymmetric compute allocation (e.g., prioritizing perceptual processing under distribution shift), supports selective optimization (e.g., improving the perceptual stage alone when it is the bottleneck for end-to-end performance), and accommodates compressed contexts by running global search at lower image resolutions and allocating high-resolution processing only to selected regions, thereby reducing total visual tokens count and compute. Across challenging visual reasoning benchmarks, SPARC outperforms monolithic baselines and strong visual-grounding approaches. For instance, SPARC improves the accuracy of Qwen3VL-4B on the $V^*$ VQA benchmark by 6.7 percentage points, and it surpasses "thinking with images" by 4.6 points on a challenging OOD task despite requiring a 200$\times$ lower token budget.
BOAD: Discovering Hierarchical Software Engineering Agents via Bandit Optimization
Dec 29, 2025Large language models (LLMs) have shown strong reasoning and coding capabilities, yet they struggle to generalize to real-world software engineering (SWE) problems that are long-horizon and out of distribution. Existing systems often rely on a single agent to handle the entire workflow-interpreting issues, navigating large codebases, and implementing fixes-within one reasoning chain. Such monolithic designs force the model to retain irrelevant context, leading to spurious correlations and poor generalization. Motivated by how human engineers decompose complex problems, we propose structuring SWE agents as orchestrators coordinating specialized sub-agents for sub-tasks such as localization, editing, and validation. The challenge lies in discovering effective hierarchies automatically: as the number of sub-agents grows, the search space becomes combinatorial, and it is difficult to attribute credit to individual sub-agents within a team. We address these challenges by formulating hierarchy discovery as a multi-armed bandit (MAB) problem, where each arm represents a candidate sub-agent and the reward measures its helpfulness when collaborating with others. This framework, termed Bandit Optimization for Agent Design (BOAD), enables efficient exploration of sub-agent designs under limited evaluation budgets. On SWE-bench-Verified, BOAD outperforms single-agent and manually designed multi-agent systems. On SWE-bench-Live, featuring more recent and out-of-distribution issues, our 36B system ranks second on the leaderboard at the time of evaluation, surpassing larger models such as GPT-4 and Claude. These results demonstrate that automatically discovered hierarchical multi-agent systems significantly improve generalization on challenging long-horizon SWE tasks. Code is available at https://github.com/iamxjy/BOAD-SWE-Agent.
WildFeedback: Aligning LLMs With In-situ User Interactions And Feedback
Aug 28, 2024



As large language models (LLMs) continue to advance, aligning these models with human preferences has emerged as a critical challenge. Traditional alignment methods, relying on human or LLM annotated datasets, are limited by their resource-intensive nature, inherent subjectivity, and the risk of feedback loops that amplify model biases. To overcome these limitations, we introduce WildFeedback, a novel framework that leverages real-time, in-situ user interactions to create preference datasets that more accurately reflect authentic human values. WildFeedback operates through a three-step process: feedback signal identification, preference data construction, and user-guided evaluation. We applied this framework to a large corpus of user-LLM conversations, resulting in a rich preference dataset that reflects genuine user preferences. This dataset captures the nuances of user preferences by identifying and classifying feedback signals within natural conversations, thereby enabling the construction of more representative and context-sensitive alignment data. Our extensive experiments demonstrate that LLMs fine-tuned on WildFeedback exhibit significantly improved alignment with user preferences, as evidenced by both traditional benchmarks and our proposed user-guided evaluation. By incorporating real-time feedback from actual users, WildFeedback addresses the scalability, subjectivity, and bias challenges that plague existing approaches, marking a significant step toward developing LLMs that are more responsive to the diverse and evolving needs of their users. In summary, WildFeedback offers a robust, scalable solution for aligning LLMs with true human values, setting a new standard for the development and evaluation of user-centric language models.
Large Scale Knowledge Washing
May 28, 2024Large language models show impressive abilities in memorizing world knowledge, which leads to concerns regarding memorization of private information, toxic or sensitive knowledge, and copyrighted content. We introduce the problem of Large Scale Knowledge Washing, focusing on unlearning an extensive amount of factual knowledge. Previous unlearning methods usually define the reverse loss and update the model via backpropagation, which may affect the model's fluency and reasoning ability or even destroy the model due to extensive training with the reverse loss. Existing works introduce additional data from downstream tasks to prevent the model from losing capabilities, which requires downstream task awareness. Controlling the tradeoff of unlearning and maintaining existing capabilities is also challenging. To this end, we propose LAW (Large Scale Washing) to update the MLP layers in decoder-only large language models to perform knowledge washing, as inspired by model editing methods and based on the hypothesis that knowledge and reasoning are disentanglable. We derive a new objective with the knowledge to be unlearned to update the weights of certain MLP layers. Experimental results demonstrate the effectiveness of LAW in forgetting target knowledge while maintaining reasoning ability. The code will be open-sourced at https://github.com/wangyu-ustc/LargeScaleWashing.
Cognitive Bias in High-Stakes Decision-Making with LLMs
Feb 25, 2024



Large language models (LLMs) offer significant potential as tools to support an expanding range of decision-making tasks. However, given their training on human (created) data, LLMs can inherit both societal biases against protected groups, as well as be subject to cognitive bias. Such human-like bias can impede fair and explainable decisions made with LLM assistance. Our work introduces BiasBuster, a framework designed to uncover, evaluate, and mitigate cognitive bias in LLMs, particularly in high-stakes decision-making tasks. Inspired by prior research in psychology and cognitive sciences, we develop a dataset containing 16,800 prompts to evaluate different cognitive biases (e.g., prompt-induced, sequential, inherent). We test various bias mitigation strategies, amidst proposing a novel method using LLMs to debias their own prompts. Our analysis provides a comprehensive picture on the presence and effects of cognitive bias across different commercial and open-source models. We demonstrate that our self-help debiasing effectively mitigate cognitive bias without having to manually craft examples for each bias type.
CAMELoT: Towards Large Language Models with Training-Free Consolidated Associative Memory
Feb 21, 2024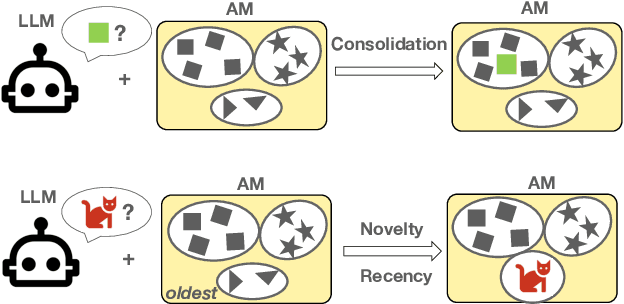
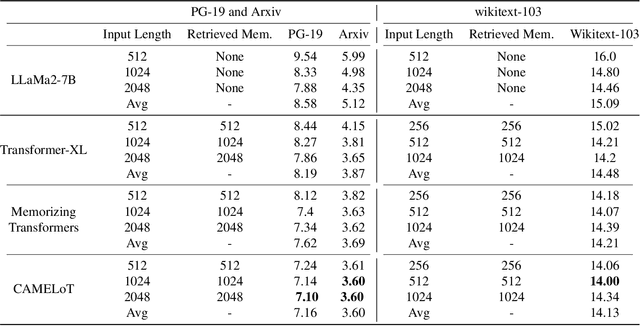
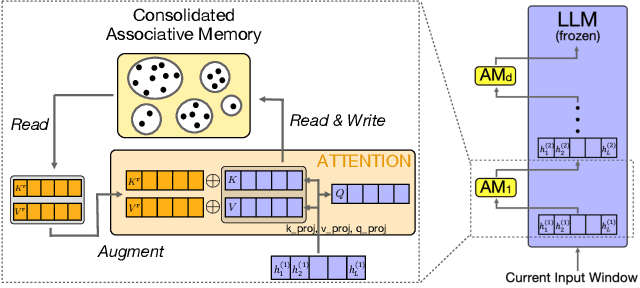

Large Language Models (LLMs) struggle to handle long input sequences due to high memory and runtime costs. Memory-augmented models have emerged as a promising solution to this problem, but current methods are hindered by limited memory capacity and require costly re-training to integrate with a new LLM. In this work, we introduce an associative memory module which can be coupled to any pre-trained (frozen) attention-based LLM without re-training, enabling it to handle arbitrarily long input sequences. Unlike previous methods, our associative memory module consolidates representations of individual tokens into a non-parametric distribution model, dynamically managed by properly balancing the novelty and recency of the incoming data. By retrieving information from this consolidated associative memory, the base LLM can achieve significant (up to 29.7% on Arxiv) perplexity reduction in long-context modeling compared to other baselines evaluated on standard benchmarks. This architecture, which we call CAMELoT (Consolidated Associative Memory Enhanced Long Transformer), demonstrates superior performance even with a tiny context window of 128 tokens, and also enables improved in-context learning with a much larger set of demonstrations.
LVCHAT: Facilitating Long Video Comprehension
Feb 19, 2024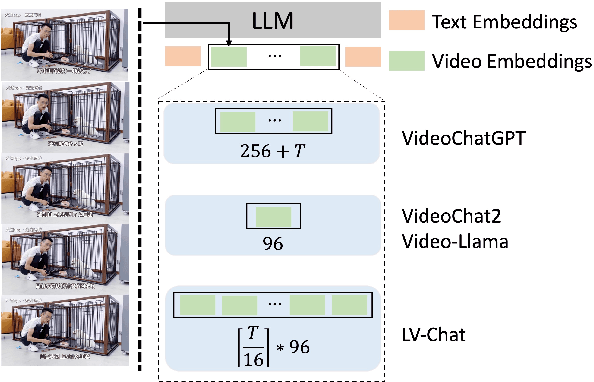
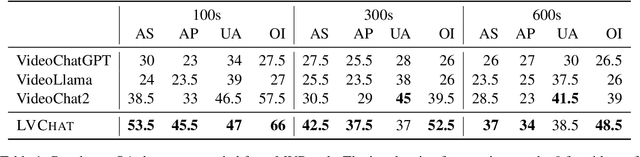
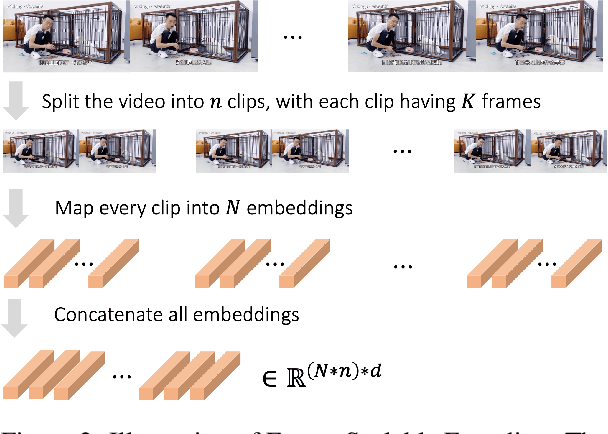

Enabling large language models (LLMs) to read videos is vital for multimodal LLMs. Existing works show promise on short videos whereas long video (longer than e.g.~1 minute) comprehension remains challenging. The major problem lies in the over-compression of videos, i.e., the encoded video representations are not enough to represent the whole video. To address this issue, we propose Long Video Chat (LVChat), where Frame-Scalable Encoding (FSE) is introduced to dynamically adjust the number of embeddings in alignment with the duration of the video to ensure long videos are not overly compressed into a few embeddings. To deal with long videos whose length is beyond videos seen during training, we propose Interleaved Frame Encoding (IFE), repeating positional embedding and interleaving multiple groups of videos to enable long video input, avoiding performance degradation due to overly long videos. Experimental results show that LVChat significantly outperforms existing methods by up to 27\% in accuracy on long-video QA datasets and long-video captioning benchmarks. Our code is published at https://github.com/wangyu-ustc/LVChat.
InfoRank: Unbiased Learning-to-Rank via Conditional Mutual Information Minimization
Jan 23, 2024



Ranking items regarding individual user interests is a core technique of multiple downstream tasks such as recommender systems. Learning such a personalized ranker typically relies on the implicit feedback from users' past click-through behaviors. However, collected feedback is biased toward previously highly-ranked items and directly learning from it would result in a "rich-get-richer" phenomenon. In this paper, we propose a simple yet sufficient unbiased learning-to-rank paradigm named InfoRank that aims to simultaneously address both position and popularity biases. We begin by consolidating the impacts of those biases into a single observation factor, thereby providing a unified approach to addressing bias-related issues. Subsequently, we minimize the mutual information between the observation estimation and the relevance estimation conditioned on the input features. By doing so, our relevance estimation can be proved to be free of bias. To implement InfoRank, we first incorporate an attention mechanism to capture latent correlations within user-item features, thereby generating estimations of observation and relevance. We then introduce a regularization term, grounded in conditional mutual information, to promote conditional independence between relevance estimation and observation estimation. Experimental evaluations conducted across three extensive recommendation and search datasets reveal that InfoRank learns more precise and unbiased ranking strategies.
Deciphering Compatibility Relationships with Textual Descriptions via Extraction and Explanation
Dec 17, 2023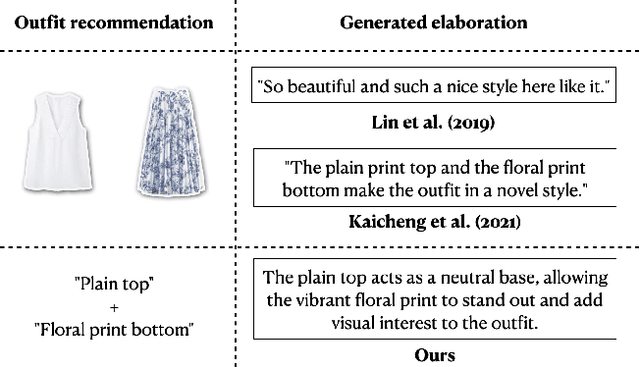
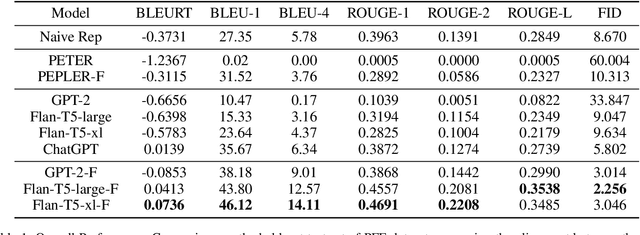
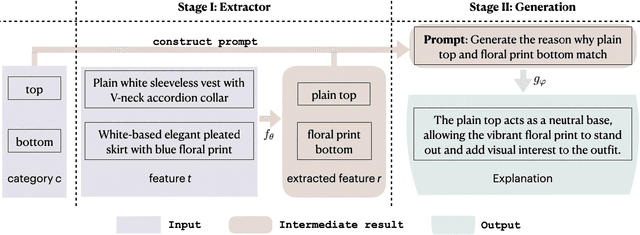

Understanding and accurately explaining compatibility relationships between fashion items is a challenging problem in the burgeoning domain of AI-driven outfit recommendations. Present models, while making strides in this area, still occasionally fall short, offering explanations that can be elementary and repetitive. This work aims to address these shortcomings by introducing the Pair Fashion Explanation (PFE) dataset, a unique resource that has been curated to illuminate these compatibility relationships. Furthermore, we propose an innovative two-stage pipeline model that leverages this dataset. This fine-tuning allows the model to generate explanations that convey the compatibility relationships between items. Our experiments showcase the model's potential in crafting descriptions that are knowledgeable, aligned with ground-truth matching correlations, and that produce understandable and informative descriptions, as assessed by both automatic metrics and human evaluation. Our code and data are released at https://github.com/wangyu-ustc/PairFashionExplanation