 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrosstalk-Resilient Beamforming for Movable Antenna Enabled Integrated Sensing and Communication
Sep 03, 2025



This paper investigates a movable antenna (MA) enabled integrated sensing and communication (ISAC) system under the influence of antenna crosstalk. First, it generalizes the antenna crosstalk model from the conventional fixed-position antenna (FPA) system to the MA scenario. Then, a Cramer-Rao bound (CRB) minimization problem driven by joint beamforming and antenna position design is presented. Specifically, to address this highly non-convex flexible beamforming problem, we deploy a deep reinforcement learning (DRL) approach to train a flexible beamforming agent. To ensure stability during training, a Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm is adopted to balance exploration with reward maximization for efficient and reliable learning. Numerical results demonstrate that the proposed crosstalk-resilient (CR) algorithm enhances the overall ISAC performance compared to other benchmark schemes.
RecWizard: A Toolkit for Conversational Recommendation with Modular, Portable Models and Interactive User Interface
Feb 23, 2024
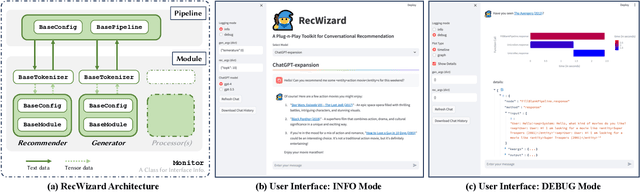


We present a new Python toolkit called RecWizard for Conversational Recommender Systems (CRS). RecWizard offers support for development of models and interactive user interface, drawing from the best practices of the Huggingface ecosystems. CRS with RecWizard are modular, portable, interactive and Large Language Models (LLMs)-friendly, to streamline the learning process and reduce the additional effort for CRS research. For more comprehensive information about RecWizard, please check our GitHub https://github.com/McAuley-Lab/RecWizard.
LVCHAT: Facilitating Long Video Comprehension
Feb 19, 2024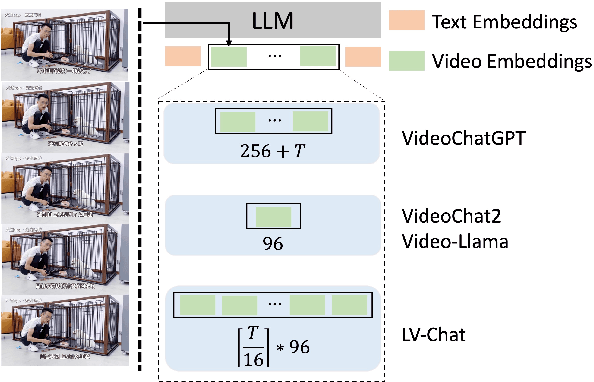
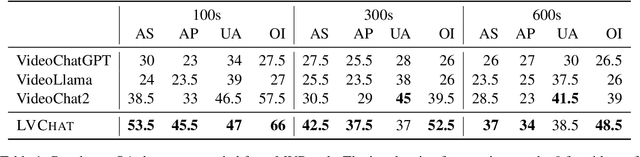
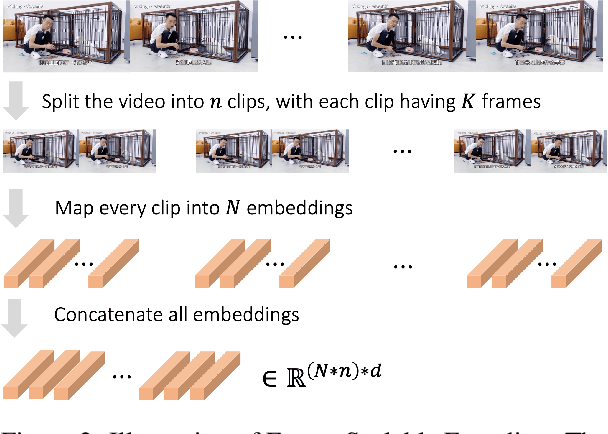

Enabling large language models (LLMs) to read videos is vital for multimodal LLMs. Existing works show promise on short videos whereas long video (longer than e.g.~1 minute) comprehension remains challenging. The major problem lies in the over-compression of videos, i.e., the encoded video representations are not enough to represent the whole video. To address this issue, we propose Long Video Chat (LVChat), where Frame-Scalable Encoding (FSE) is introduced to dynamically adjust the number of embeddings in alignment with the duration of the video to ensure long videos are not overly compressed into a few embeddings. To deal with long videos whose length is beyond videos seen during training, we propose Interleaved Frame Encoding (IFE), repeating positional embedding and interleaving multiple groups of videos to enable long video input, avoiding performance degradation due to overly long videos. Experimental results show that LVChat significantly outperforms existing methods by up to 27\% in accuracy on long-video QA datasets and long-video captioning benchmarks. Our code is published at https://github.com/wangyu-ustc/LVChat.
BEVFusion4D: Learning LiDAR-Camera Fusion Under Bird's-Eye-View via Cross-Modality Guidance and Temporal Aggregation
Mar 30, 2023



Integrating LiDAR and Camera information into Bird's-Eye-View (BEV) has become an essential topic for 3D object detection in autonomous driving. Existing methods mostly adopt an independent dual-branch framework to generate LiDAR and camera BEV, then perform an adaptive modality fusion. Since point clouds provide more accurate localization and geometry information, they could serve as a reliable spatial prior to acquiring relevant semantic information from the images. Therefore, we design a LiDAR-Guided View Transformer (LGVT) to effectively obtain the camera representation in BEV space and thus benefit the whole dual-branch fusion system. LGVT takes camera BEV as the primitive semantic query, repeatedly leveraging the spatial cue of LiDAR BEV for extracting image features across multiple camera views. Moreover, we extend our framework into the temporal domain with our proposed Temporal Deformable Alignment (TDA) module, which aims to aggregate BEV features from multiple historical frames. Including these two modules, our framework dubbed BEVFusion4D achieves state-of-the-art results in 3D object detection, with 72.0% mAP and 73.5% NDS on the nuScenes validation set, and 73.3% mAP and 74.7% NDS on nuScenes test set, respectively.
Preliminary Analysis of Channel Capacity in Air to ground LoS MIMO Communication Based on A Cloud Modeling Method
Oct 19, 2022

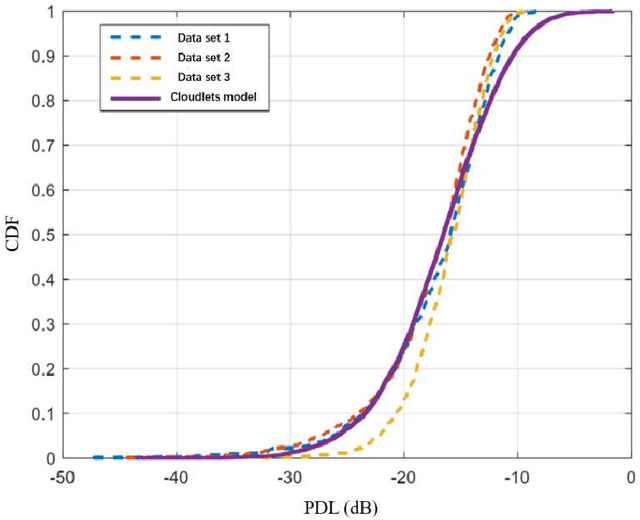

Since the orthogonality of the line-of-sight multiple input multiple output (LoS MIMO) channel is only available within the Rayleigh distance, coverage of communication systems is restricted due to the finite implementation spacing of antennas. However, media with different permittivity in the transmission path are likely to loosen the requirement for antenna spacing. Such a conclusion could be enlightening in an air-to-ground LoS MIMO scenario considering the existence of clouds in the troposphere. To analyze the random phase variations in the presence of a single-layer cloud, we propose and modify a new cloud modeling method fit for LoS MIMO scene based on real-measurement data. Then, the preliminary analysis of channel capacity is conducted based on the simulation result.
Attention-based Partial Face Recognition
Jun 14, 2021

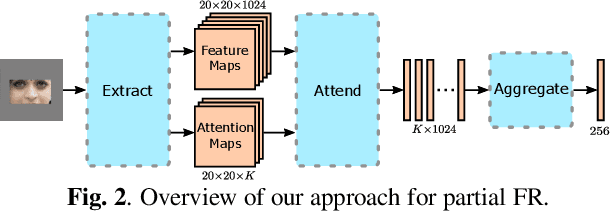
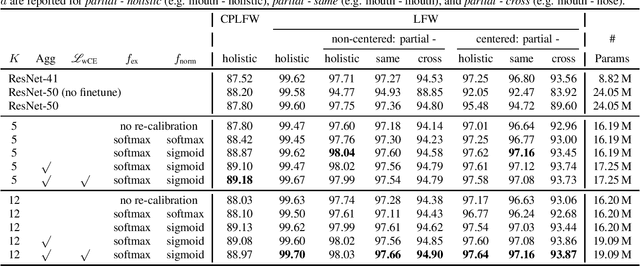
Photos of faces captured in unconstrained environments, such as large crowds, still constitute challenges for current face recognition approaches as often faces are occluded by objects or people in the foreground. However, few studies have addressed the task of recognizing partial faces. In this paper, we propose a novel approach to partial face recognition capable of recognizing faces with different occluded areas. We achieve this by combining attentional pooling of a ResNet's intermediate feature maps with a separate aggregation module. We further adapt common losses to partial faces in order to ensure that the attention maps are diverse and handle occluded parts. Our thorough analysis demonstrates that we outperform all baselines under multiple benchmark protocols, including naturally and synthetically occluded partial faces. This suggests that our method successfully focuses on the relevant parts of the occluded face.