 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Model-Agnostic Similarity and Confidence in Face Verification
Nov 24, 2022



Recently, face recognition systems have demonstrated remarkable performances and thus gained a vital role in our daily life. They already surpass human face verification accountability in many scenarios. However, they lack explanations for their predictions. Compared to human operators, typical face recognition network system generate only binary decisions without further explanation and insights into those decisions. This work focuses on explanations for face recognition systems, vital for developers and operators. First, we introduce a confidence score for those systems based on facial feature distances between two input images and the distribution of distances across a dataset. Secondly, we establish a novel visualization approach to obtain more meaningful predictions from a face recognition system, which maps the distance deviation based on a systematic occlusion of images. The result is blended with the original images and highlights similar and dissimilar facial regions. Lastly, we calculate confidence scores and explanation maps for several state-of-the-art face verification datasets and release the results on a web platform. We optimize the platform for a user-friendly interaction and hope to further improve the understanding of machine learning decisions. The source code is available on GitHub, and the web platform is publicly available at http://explainable-face-verification.ey.r.appspot.com.
Synthehicle: Multi-Vehicle Multi-Camera Tracking in Virtual Cities
Aug 30, 2022
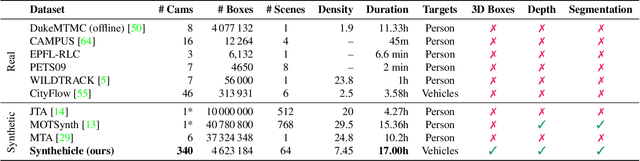

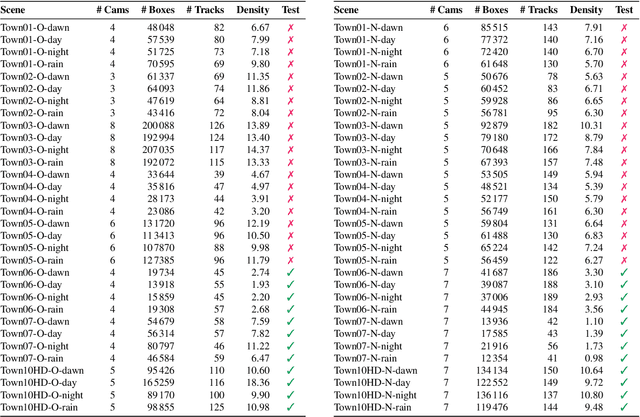
Smart City applications such as intelligent traffic routing or accident prevention rely on computer vision methods for exact vehicle localization and tracking. Due to the scarcity of accurately labeled data, detecting and tracking vehicles in 3D from multiple cameras proves challenging to explore. We present a massive synthetic dataset for multiple vehicle tracking and segmentation in multiple overlapping and non-overlapping camera views. Unlike existing datasets, which only provide tracking ground truth for 2D bounding boxes, our dataset additionally contains perfect labels for 3D bounding boxes in camera- and world coordinates, depth estimation, and instance, semantic and panoptic segmentation. The dataset consists of 17 hours of labeled video material, recorded from 340 cameras in 64 diverse day, rain, dawn, and night scenes, making it the most extensive dataset for multi-target multi-camera tracking so far. We provide baselines for detection, vehicle re-identification, and single- and multi-camera tracking. Code and data are publicly available.
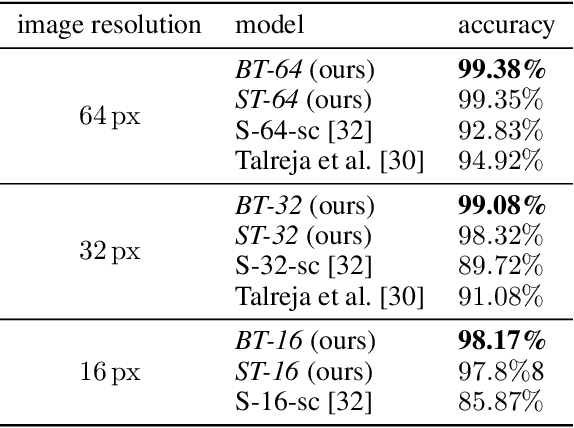
Octuplet Loss: Make Face Recognition Robust to Image Resolution
Jul 14, 2022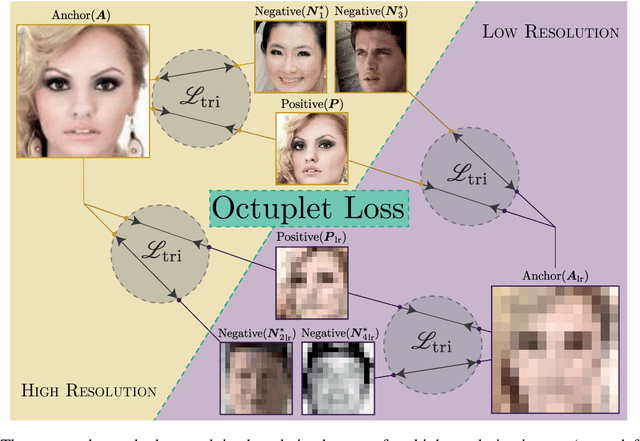
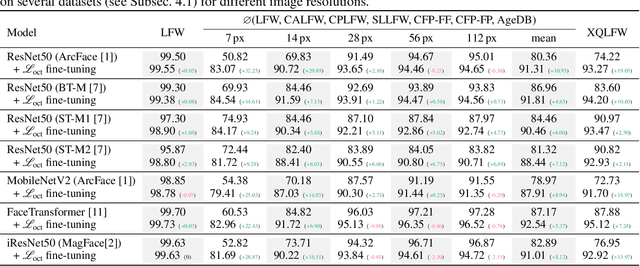
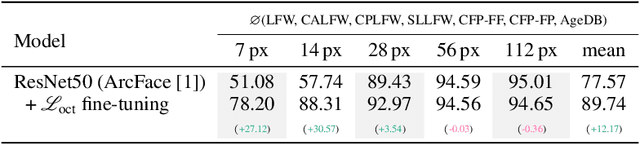
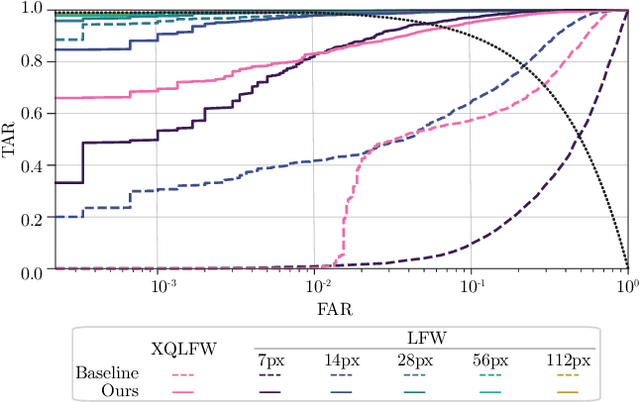
Image resolution, or in general, image quality, plays an essential role in the performance of today's face recognition systems. To address this problem, we propose a novel combination of the popular triplet loss to improve robustness against image resolution via fine-tuning of existing face recognition models. With octuplet loss, we leverage the relationship between high-resolution images and their synthetically down-sampled variants jointly with their identity labels. Fine-tuning several state-of-the-art approaches with our method proves that we can significantly boost performance for cross-resolution (high-to-low resolution) face verification on various datasets without meaningfully exacerbating the performance on high-to-high resolution images. Our method applied on the FaceTransformer network achieves 95.12% face verification accuracy on the challenging XQLFW dataset while reaching 99.73% on the LFW database. Moreover, the low-to-low face verification accuracy benefits from our method. We release our code to allow seamless integration of the octuplet loss into existing frameworks.
Face Morphing: Fooling a Face Recognition System Is Simple!
May 27, 2022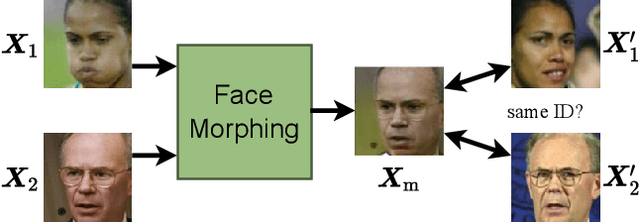
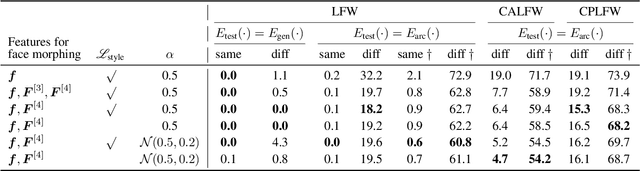
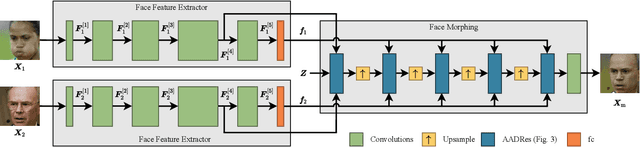
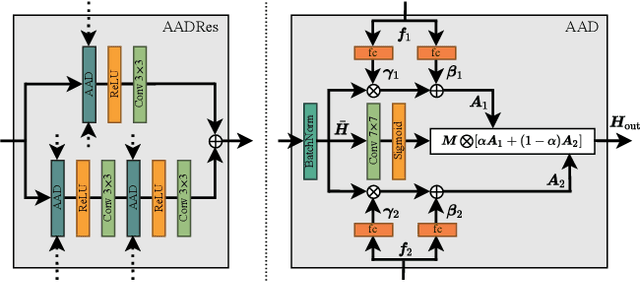
State-of-the-art face recognition (FR) approaches have shown remarkable results in predicting whether two faces belong to the same identity, yielding accuracies between 92% and 100% depending on the difficulty of the protocol. However, the accuracy drops substantially when exposed to morphed faces, specifically generated to look similar to two identities. To generate morphed faces, we integrate a simple pretrained FR model into a generative adversarial network (GAN) and modify several loss functions for face morphing. In contrast to previous works, our approach and analyses are not limited to pairs of frontal faces with the same ethnicity and gender. Our qualitative and quantitative results affirm that our approach achieves a seamless change between two faces even in unconstrained scenarios. Despite using features from a simpler FR model for face morphing, we demonstrate that even recent FR systems struggle to distinguish the morphed face from both identities obtaining an accuracy of only 55-70%. Besides, we provide further insights into how knowing the FR system makes it particularly vulnerable to face morphing attacks.
Towards a Deeper Understanding of Skeleton-based Gait Recognition
Apr 16, 2022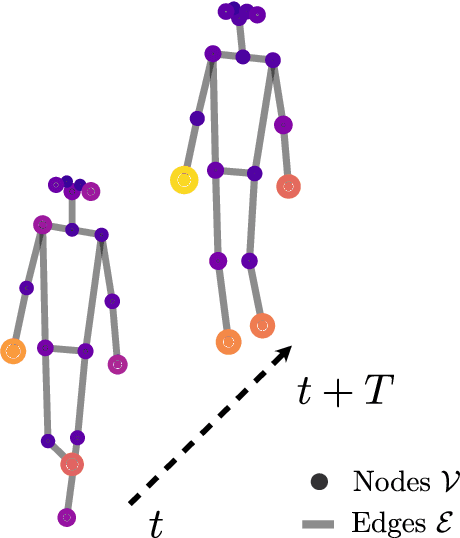
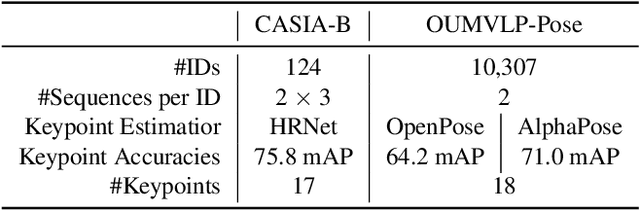
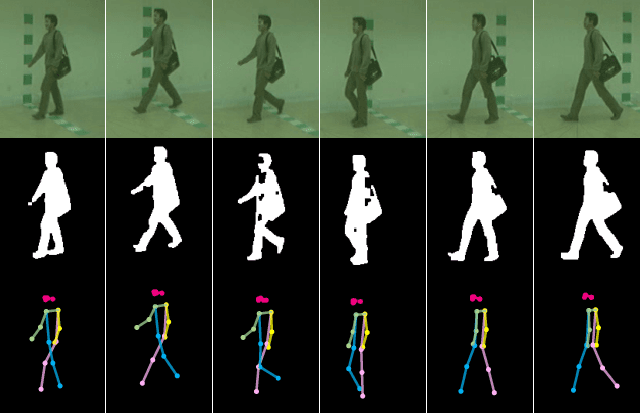
Gait recognition is a promising biometric with unique properties for identifying individuals from a long distance by their walking patterns. In recent years, most gait recognition methods used the person's silhouette to extract the gait features. However, silhouette images can lose fine-grained spatial information, suffer from (self) occlusion, and be challenging to obtain in real-world scenarios. Furthermore, these silhouettes also contain other visual clues that are not actual gait features and can be used for identification, but also to fool the system. Model-based methods do not suffer from these problems and are able to represent the temporal motion of body joints, which are actual gait features. The advances in human pose estimation started a new era for model-based gait recognition with skeleton-based gait recognition. In this work, we propose an approach based on Graph Convolutional Networks (GCNs) that combines higher-order inputs, and residual networks to an efficient architecture for gait recognition. Extensive experiments on the two popular gait datasets, CASIA-B and OUMVLP-Pose, show a massive improvement (3x) of the state-of-the-art (SotA) on the largest gait dataset OUMVLP-Pose and strong temporal modeling capabilities. Finally, we visualize our method to understand skeleton-based gait recognition better and to show that we model real gait features.
Cross-Quality LFW: A Database for Analyzing Cross-Resolution Image Face Recognition in Unconstrained Environments
Aug 26, 2021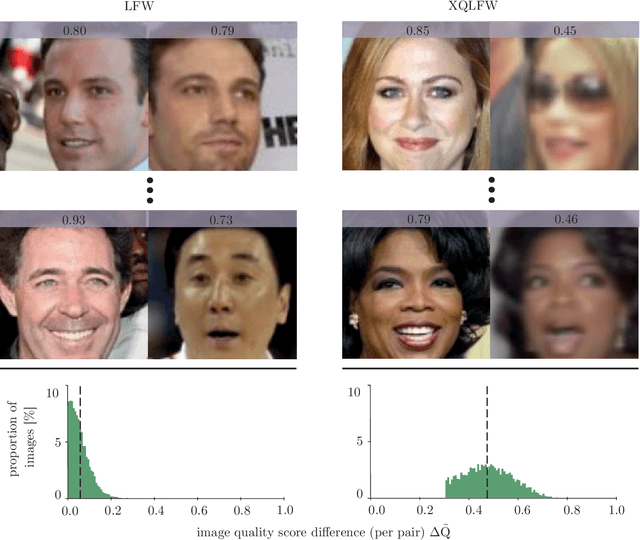

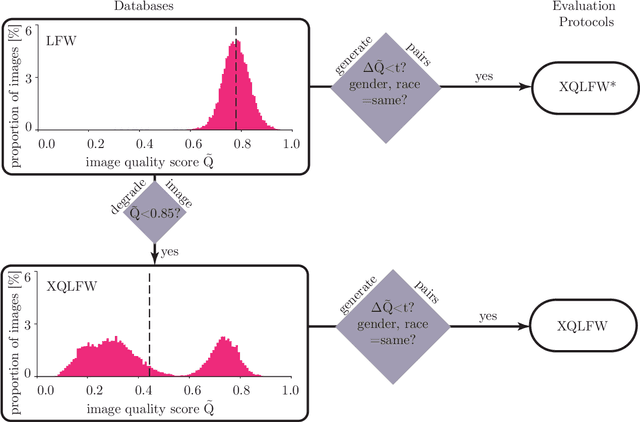
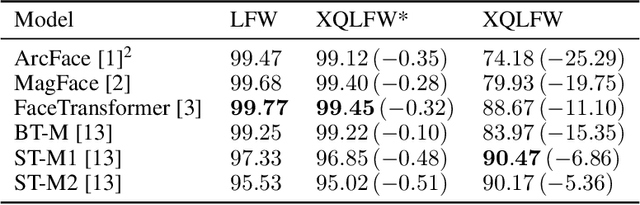
Real-world face recognition applications often deal with suboptimal image quality or resolution due to different capturing conditions such as various subject-to-camera distances, poor camera settings, or motion blur. This characteristic has an unignorable effect on performance. Recent cross-resolution face recognition approaches used simple, arbitrary, and unrealistic down- and up-scaling techniques to measure robustness against real-world edge-cases in image quality. Thus, we propose a new standardized benchmark dataset and evaluation protocol derived from the famous Labeled Faces in the Wild (LFW). In contrast to previous derivatives, which focus on pose, age, similarity, and adversarial attacks, our Cross-Quality Labeled Faces in the Wild (XQLFW) maximizes the quality difference. It contains only more realistic synthetically degraded images when necessary. Our proposed dataset is then used to further investigate the influence of image quality on several state-of-the-art approaches. With XQLFW, we show that these models perform differently in cross-quality cases, and hence, the generalizing capability is not accurately predicted by their performance on LFW. Additionally, we report baseline accuracy with recent deep learning models explicitly trained for cross-resolution applications and evaluate the susceptibility to image quality. To encourage further research in cross-resolution face recognition and incite the assessment of image quality robustness, we publish the database and code for evaluation.
Image Resolution Susceptibility of Face Recognition Models
Jul 08, 2021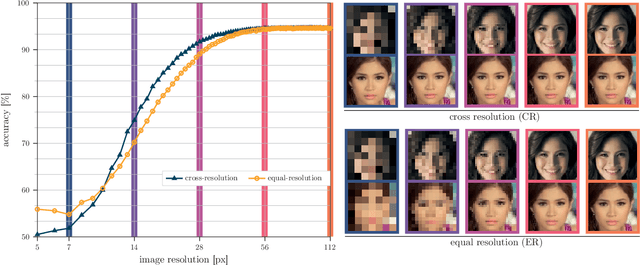
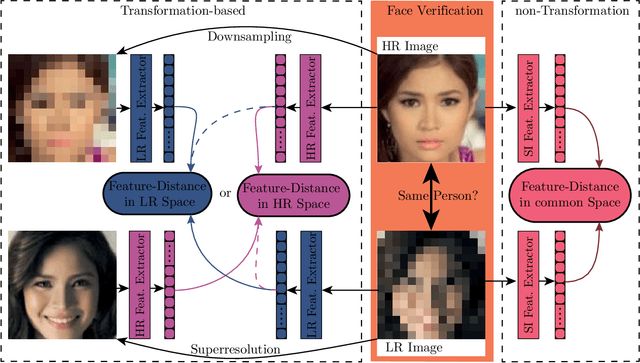
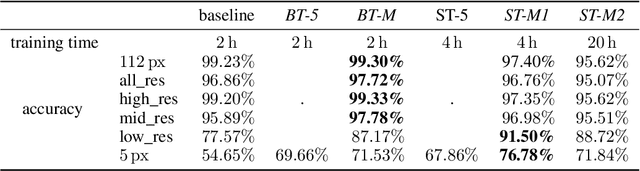
Face recognition approaches often rely on equal image resolution for verification faces on two images. However, in practical applications, those image resolutions are usually not in the same range due to different image capture mechanisms or sources. In this work, we first analyze the impact of image resolutions on the face verification performance with a state-of-the-art face recognition model. For images, synthetically reduced to $5\, \times 5\, \mathrm{px}$ resolution, the verification performance drops from $99.23\%$ increasingly down to almost $55\%$. Especially, for cross-resolution image pairs (one high- and one low-resolution image), the verification accuracy decreases even further. We investigate this behavior more in-depth by looking at the feature distances for every 2-image test pair. To tackle this problem, we propose the following two methods: 1) Train a state-of-the-art face-recognition model straightforward with $50\%$ low-resolution images directly within each batch. \\ 2) Train a siamese-network structure and adding a cosine distance feature loss between high- and low-resolution features. Both methods show an improvement for cross-resolution scenarios and can increase the accuracy at very low resolution to approximately $70\%$. However, a disadvantage is that a specific model needs to be trained for every resolution-pair ...
Attention-based Partial Face Recognition
Jun 14, 2021

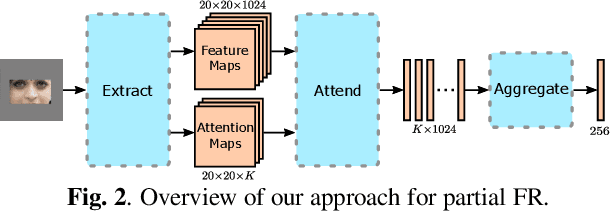
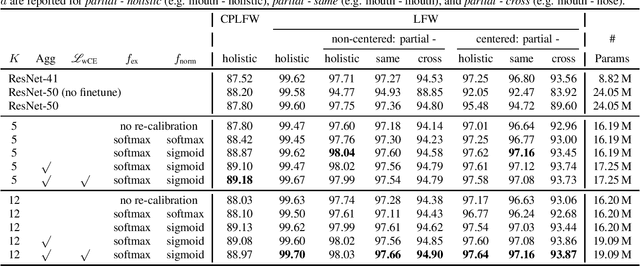
Photos of faces captured in unconstrained environments, such as large crowds, still constitute challenges for current face recognition approaches as often faces are occluded by objects or people in the foreground. However, few studies have addressed the task of recognizing partial faces. In this paper, we propose a novel approach to partial face recognition capable of recognizing faces with different occluded areas. We achieve this by combining attentional pooling of a ResNet's intermediate feature maps with a separate aggregation module. We further adapt common losses to partial faces in order to ensure that the attention maps are diverse and handle occluded parts. Our thorough analysis demonstrates that we outperform all baselines under multiple benchmark protocols, including naturally and synthetically occluded partial faces. This suggests that our method successfully focuses on the relevant parts of the occluded face.
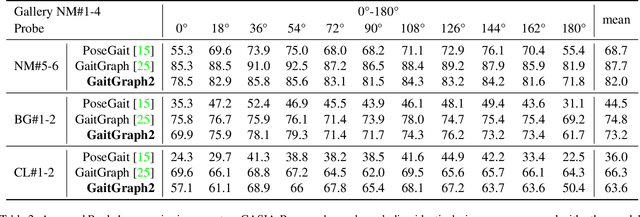
GaitGraph: Graph Convolutional Network for Skeleton-Based Gait Recognition
Jan 27, 2021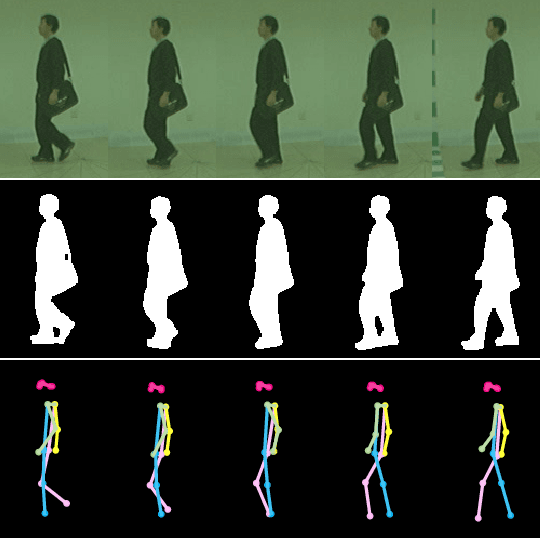
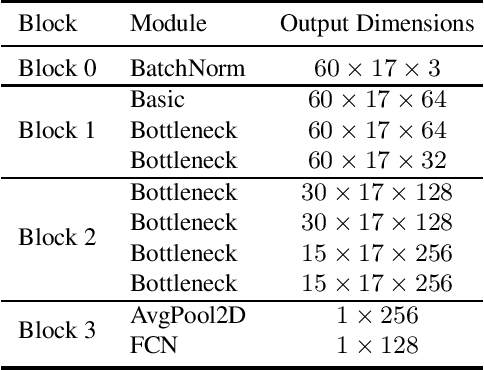
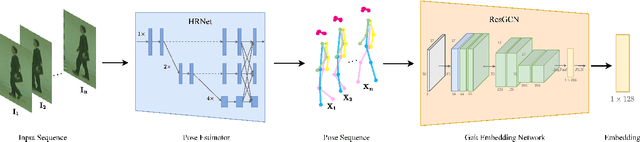
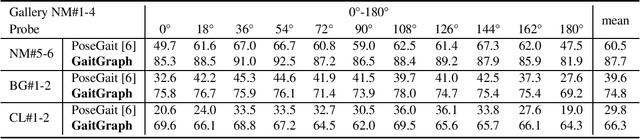
Gait recognition is a promising video-based biometric for identifying individual walking patterns from a long distance. At present, most gait recognition methods use silhouette images to represent a person in each frame. However, silhouette images can lose fine-grained spatial information, and most papers do not regard how to obtain these silhouettes in complex scenes. Furthermore, silhouette images contain not only gait features but also other visual clues that can be recognized. Hence these approaches can not be considered as strict gait recognition. We leverage recent advances in human pose estimation to estimate robust skeleton poses directly from RGB images to bring back model-based gait recognition with a cleaner representation of gait. Thus, we propose GaitGraph that combines skeleton poses with Graph Convolutional Network (GCN) to obtain a modern model-based approach for gait recognition. The main advantages are a cleaner, more elegant extraction of the gait features and the ability to incorporate powerful spatio-temporal modeling using GCN. Experiments on the popular CASIA-B gait dataset show that our method archives state-of-the-art performance in model-based gait recognition. The code and models are publicly available.
Lightweight Multi-Branch Network for Person Re-Identification
Jan 26, 2021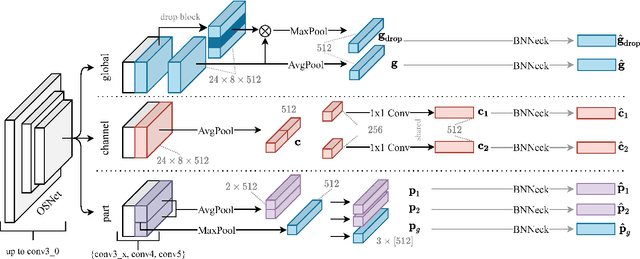
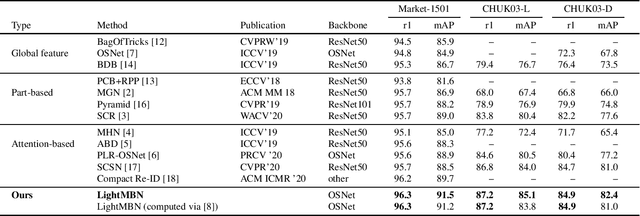
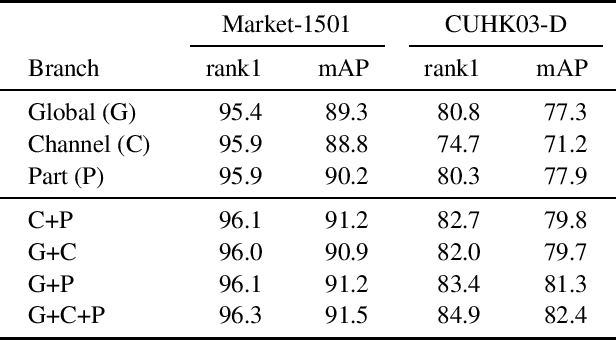
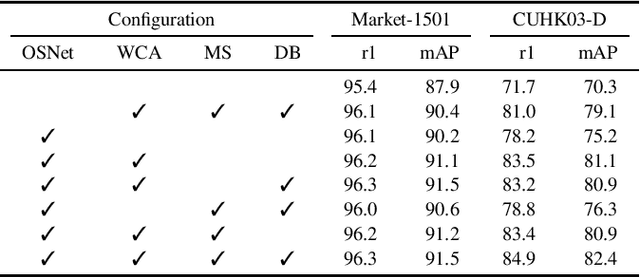
Person Re-Identification aims to retrieve person identities from images captured by multiple cameras or the same cameras in different time instances and locations. Because of its importance in many vision applications from surveillance to human-machine interaction, person re-identification methods need to be reliable and fast. While more and more deep architectures are proposed for increasing performance, those methods also increase overall model complexity. This paper proposes a lightweight network that combines global, part-based, and channel features in a unified multi-branch architecture that builds on the resource-efficient OSNet backbone. Using a well-founded combination of training techniques and design choices, our final model achieves state-of-the-art results on CUHK03 labeled, CUHK03 detected, and Market-1501 with 85.1% mAP / 87.2% rank1, 82.4% mAP / 84.9% rank1, and 91.5% mAP / 96.3% rank1, respectively.