 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaRC: Sparse Radar-Camera Fusion for 3D Object Detection
Nov 29, 2024In this work, we present SpaRC, a novel Sparse fusion transformer for 3D perception that integrates multi-view image semantics with Radar and Camera point features. The fusion of radar and camera modalities has emerged as an efficient perception paradigm for autonomous driving systems. While conventional approaches utilize dense Bird's Eye View (BEV)-based architectures for depth estimation, contemporary query-based transformers excel in camera-only detection through object-centric methodology. However, these query-based approaches exhibit limitations in false positive detections and localization precision due to implicit depth modeling. We address these challenges through three key contributions: (1) sparse frustum fusion (SFF) for cross-modal feature alignment, (2) range-adaptive radar aggregation (RAR) for precise object localization, and (3) local self-attention (LSA) for focused query aggregation. In contrast to existing methods requiring computationally intensive BEV-grid rendering, SpaRC operates directly on encoded point features, yielding substantial improvements in efficiency and accuracy. Empirical evaluations on the nuScenes and TruckScenes benchmarks demonstrate that SpaRC significantly outperforms existing dense BEV-based and sparse query-based detectors. Our method achieves state-of-the-art performance metrics of 67.1 NDS and 63.1 AMOTA. The code and pretrained models are available at https://github.com/phi-wol/sparc.
Spatial-Temporal Multi-Cuts for Online Multiple-Camera Vehicle Tracking
Oct 03, 2024Accurate online multiple-camera vehicle tracking is essential for intelligent transportation systems, autonomous driving, and smart city applications. Like single-camera multiple-object tracking, it is commonly formulated as a graph problem of tracking-by-detection. Within this framework, existing online methods usually consist of two-stage procedures that cluster temporally first, then spatially, or vice versa. This is computationally expensive and prone to error accumulation. We introduce a graph representation that allows spatial-temporal clustering in a single, combined step: New detections are spatially and temporally connected with existing clusters. By keeping sparse appearance and positional cues of all detections in a cluster, our method can compare clusters based on the strongest available evidence. The final tracks are obtained online using a simple multicut assignment procedure. Our method does not require any training on the target scene, pre-extraction of single-camera tracks, or additional annotations. Notably, we outperform the online state-of-the-art on the CityFlow dataset in terms of IDF1 by more than 14%, and on the Synthehicle dataset by more than 25%, respectively. The code is publicly available.
Lifting Multi-View Detection and Tracking to the Bird's Eye View
Mar 19, 2024Taking advantage of multi-view aggregation presents a promising solution to tackle challenges such as occlusion and missed detection in multi-object tracking and detection. Recent advancements in multi-view detection and 3D object recognition have significantly improved performance by strategically projecting all views onto the ground plane and conducting detection analysis from a Bird's Eye View. In this paper, we compare modern lifting methods, both parameter-free and parameterized, to multi-view aggregation. Additionally, we present an architecture that aggregates the features of multiple times steps to learn robust detection and combines appearance- and motion-based cues for tracking. Most current tracking approaches either focus on pedestrians or vehicles. In our work, we combine both branches and add new challenges to multi-view detection with cross-scene setups. Our method generalizes to three public datasets across two domains: (1) pedestrian: Wildtrack and MultiviewX, and (2) roadside perception: Synthehicle, achieving state-of-the-art performance in detection and tracking. https://github.com/tteepe/TrackTacular
Unleashing HyDRa: Hybrid Fusion, Depth Consistency and Radar for Unified 3D Perception
Mar 12, 2024



Low-cost, vision-centric 3D perception systems for autonomous driving have made significant progress in recent years, narrowing the gap to expensive LiDAR-based methods. The primary challenge in becoming a fully reliable alternative lies in robust depth prediction capabilities, as camera-based systems struggle with long detection ranges and adverse lighting and weather conditions. In this work, we introduce HyDRa, a novel camera-radar fusion architecture for diverse 3D perception tasks. Building upon the principles of dense BEV (Bird's Eye View)-based architectures, HyDRa introduces a hybrid fusion approach to combine the strengths of complementary camera and radar features in two distinct representation spaces. Our Height Association Transformer module leverages radar features already in the perspective view to produce more robust and accurate depth predictions. In the BEV, we refine the initial sparse representation by a Radar-weighted Depth Consistency. HyDRa achieves a new state-of-the-art for camera-radar fusion of 64.2 NDS (+1.8) and 58.4 AMOTA (+1.5) on the public nuScenes dataset. Moreover, our new semantically rich and spatially accurate BEV features can be directly converted into a powerful occupancy representation, beating all previous camera-based methods on the Occ3D benchmark by an impressive 3.7 mIoU.
EarlyBird: Early-Fusion for Multi-View Tracking in the Bird's Eye View
Oct 20, 2023Multi-view aggregation promises to overcome the occlusion and missed detection challenge in multi-object detection and tracking. Recent approaches in multi-view detection and 3D object detection made a huge performance leap by projecting all views to the ground plane and performing the detection in the Bird's Eye View (BEV). In this paper, we investigate if tracking in the BEV can also bring the next performance breakthrough in Multi-Target Multi-Camera (MTMC) tracking. Most current approaches in multi-view tracking perform the detection and tracking task in each view and use graph-based approaches to perform the association of the pedestrian across each view. This spatial association is already solved by detecting each pedestrian once in the BEV, leaving only the problem of temporal association. For the temporal association, we show how to learn strong Re-Identification (re-ID) features for each detection. The results show that early-fusion in the BEV achieves high accuracy for both detection and tracking. EarlyBird outperforms the state-of-the-art methods and improves the current state-of-the-art on Wildtrack by +4.6 MOTA and +5.6 IDF1.
Do We Still Need Non-Maximum Suppression? Accurate Confidence Estimates and Implicit Duplication Modeling with IoU-Aware Calibration
Sep 06, 2023Object detectors are at the heart of many semi- and fully autonomous decision systems and are poised to become even more indispensable. They are, however, still lacking in accessibility and can sometimes produce unreliable predictions. Especially concerning in this regard are the -- essentially hand-crafted -- non-maximum suppression algorithms that lead to an obfuscated prediction process and biased confidence estimates. We show that we can eliminate classic NMS-style post-processing by using IoU-aware calibration. IoU-aware calibration is a conditional Beta calibration; this makes it parallelizable with no hyper-parameters. Instead of arbitrary cutoffs or discounts, it implicitly accounts for the likelihood of each detection being a duplicate and adjusts the confidence score accordingly, resulting in empirically based precision estimates for each detection. Our extensive experiments on diverse detection architectures show that the proposed IoU-aware calibration can successfully model duplicate detections and improve calibration. Compared to the standard sequential NMS and calibration approach, our joint modeling can deliver performance gains over the best NMS-based alternative while producing consistently better-calibrated confidence predictions with less complexity. The \hyperlink{https://github.com/Blueblue4/IoU-AwareCalibration}{code} for all our experiments is publicly available.
Explainable Model-Agnostic Similarity and Confidence in Face Verification
Nov 24, 2022



Recently, face recognition systems have demonstrated remarkable performances and thus gained a vital role in our daily life. They already surpass human face verification accountability in many scenarios. However, they lack explanations for their predictions. Compared to human operators, typical face recognition network system generate only binary decisions without further explanation and insights into those decisions. This work focuses on explanations for face recognition systems, vital for developers and operators. First, we introduce a confidence score for those systems based on facial feature distances between two input images and the distribution of distances across a dataset. Secondly, we establish a novel visualization approach to obtain more meaningful predictions from a face recognition system, which maps the distance deviation based on a systematic occlusion of images. The result is blended with the original images and highlights similar and dissimilar facial regions. Lastly, we calculate confidence scores and explanation maps for several state-of-the-art face verification datasets and release the results on a web platform. We optimize the platform for a user-friendly interaction and hope to further improve the understanding of machine learning decisions. The source code is available on GitHub, and the web platform is publicly available at http://explainable-face-verification.ey.r.appspot.com.
Synthehicle: Multi-Vehicle Multi-Camera Tracking in Virtual Cities
Aug 30, 2022
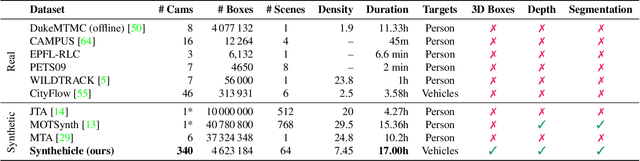

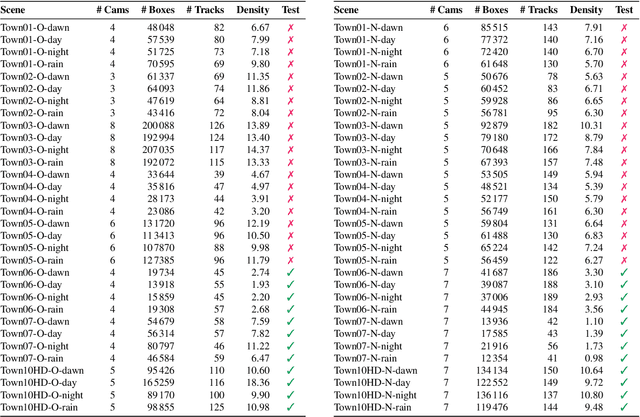
Smart City applications such as intelligent traffic routing or accident prevention rely on computer vision methods for exact vehicle localization and tracking. Due to the scarcity of accurately labeled data, detecting and tracking vehicles in 3D from multiple cameras proves challenging to explore. We present a massive synthetic dataset for multiple vehicle tracking and segmentation in multiple overlapping and non-overlapping camera views. Unlike existing datasets, which only provide tracking ground truth for 2D bounding boxes, our dataset additionally contains perfect labels for 3D bounding boxes in camera- and world coordinates, depth estimation, and instance, semantic and panoptic segmentation. The dataset consists of 17 hours of labeled video material, recorded from 340 cameras in 64 diverse day, rain, dawn, and night scenes, making it the most extensive dataset for multi-target multi-camera tracking so far. We provide baselines for detection, vehicle re-identification, and single- and multi-camera tracking. Code and data are publicly available.
Face Morphing: Fooling a Face Recognition System Is Simple!
May 27, 2022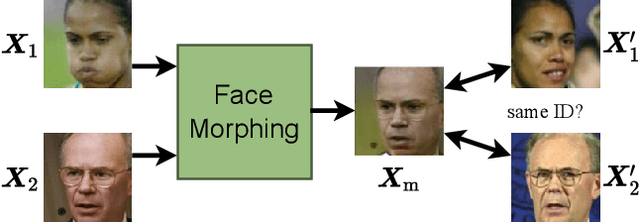
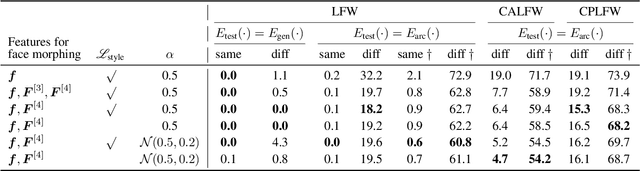
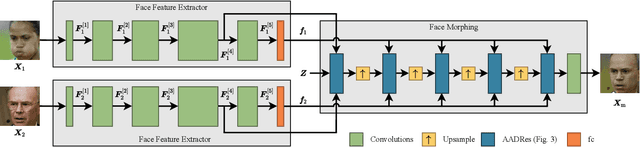
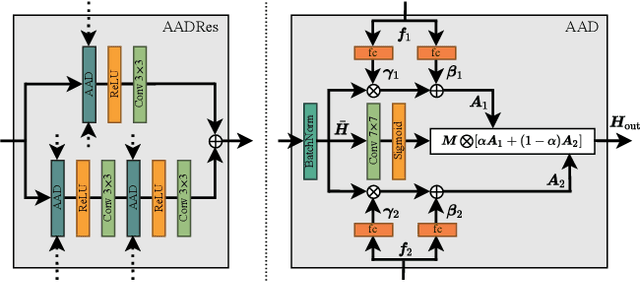
State-of-the-art face recognition (FR) approaches have shown remarkable results in predicting whether two faces belong to the same identity, yielding accuracies between 92% and 100% depending on the difficulty of the protocol. However, the accuracy drops substantially when exposed to morphed faces, specifically generated to look similar to two identities. To generate morphed faces, we integrate a simple pretrained FR model into a generative adversarial network (GAN) and modify several loss functions for face morphing. In contrast to previous works, our approach and analyses are not limited to pairs of frontal faces with the same ethnicity and gender. Our qualitative and quantitative results affirm that our approach achieves a seamless change between two faces even in unconstrained scenarios. Despite using features from a simpler FR model for face morphing, we demonstrate that even recent FR systems struggle to distinguish the morphed face from both identities obtaining an accuracy of only 55-70%. Besides, we provide further insights into how knowing the FR system makes it particularly vulnerable to face morphing attacks.
Towards a Deeper Understanding of Skeleton-based Gait Recognition
Apr 16, 2022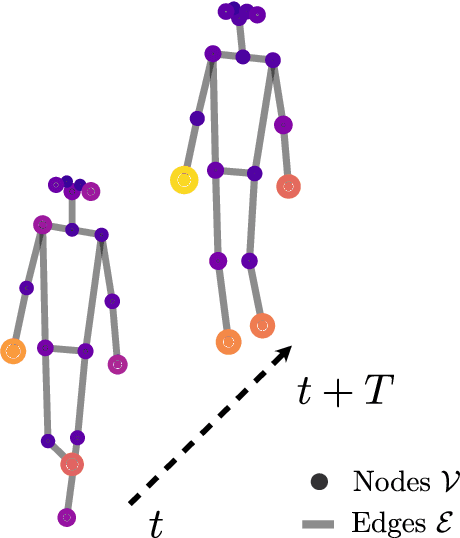
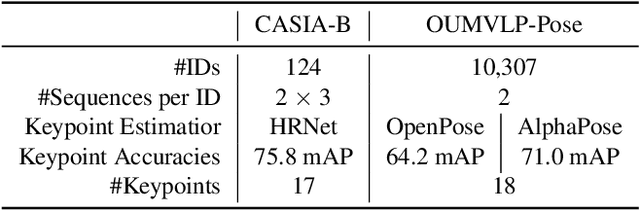
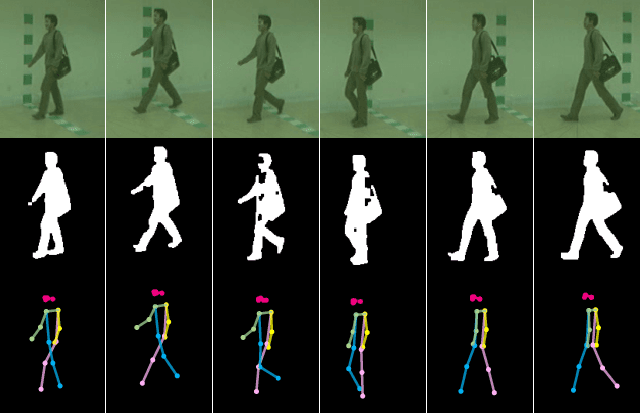
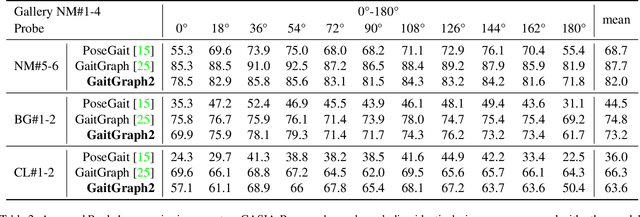
Gait recognition is a promising biometric with unique properties for identifying individuals from a long distance by their walking patterns. In recent years, most gait recognition methods used the person's silhouette to extract the gait features. However, silhouette images can lose fine-grained spatial information, suffer from (self) occlusion, and be challenging to obtain in real-world scenarios. Furthermore, these silhouettes also contain other visual clues that are not actual gait features and can be used for identification, but also to fool the system. Model-based methods do not suffer from these problems and are able to represent the temporal motion of body joints, which are actual gait features. The advances in human pose estimation started a new era for model-based gait recognition with skeleton-based gait recognition. In this work, we propose an approach based on Graph Convolutional Networks (GCNs) that combines higher-order inputs, and residual networks to an efficient architecture for gait recognition. Extensive experiments on the two popular gait datasets, CASIA-B and OUMVLP-Pose, show a massive improvement (3x) of the state-of-the-art (SotA) on the largest gait dataset OUMVLP-Pose and strong temporal modeling capabilities. Finally, we visualize our method to understand skeleton-based gait recognition better and to show that we model real gait features.