 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVCHAT: Facilitating Long Video Comprehension
Paper and Code
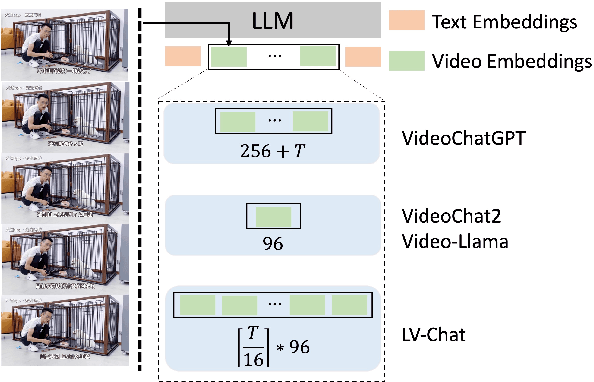
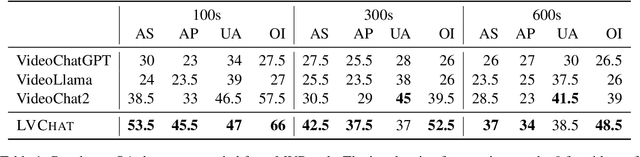
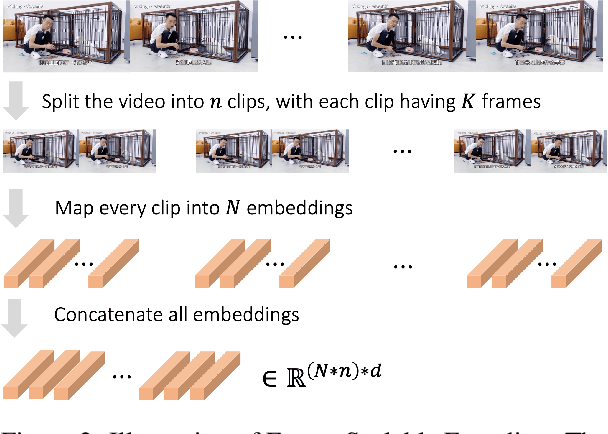

Enabling large language models (LLMs) to read videos is vital for multimodal LLMs. Existing works show promise on short videos whereas long video (longer than e.g.~1 minute) comprehension remains challenging. The major problem lies in the over-compression of videos, i.e., the encoded video representations are not enough to represent the whole video. To address this issue, we propose Long Video Chat (LVChat), where Frame-Scalable Encoding (FSE) is introduced to dynamically adjust the number of embeddings in alignment with the duration of the video to ensure long videos are not overly compressed into a few embeddings. To deal with long videos whose length is beyond videos seen during training, we propose Interleaved Frame Encoding (IFE), repeating positional embedding and interleaving multiple groups of videos to enable long video input, avoiding performance degradation due to overly long videos. Experimental results show that LVChat significantly outperforms existing methods by up to 27\% in accuracy on long-video QA datasets and long-video captioning benchmarks. Our code is published at https://github.com/wangyu-ustc/LVChat.