 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEVFusion4D: Learning LiDAR-Camera Fusion Under Bird's-Eye-View via Cross-Modality Guidance and Temporal Aggregation
Mar 30, 2023



Integrating LiDAR and Camera information into Bird's-Eye-View (BEV) has become an essential topic for 3D object detection in autonomous driving. Existing methods mostly adopt an independent dual-branch framework to generate LiDAR and camera BEV, then perform an adaptive modality fusion. Since point clouds provide more accurate localization and geometry information, they could serve as a reliable spatial prior to acquiring relevant semantic information from the images. Therefore, we design a LiDAR-Guided View Transformer (LGVT) to effectively obtain the camera representation in BEV space and thus benefit the whole dual-branch fusion system. LGVT takes camera BEV as the primitive semantic query, repeatedly leveraging the spatial cue of LiDAR BEV for extracting image features across multiple camera views. Moreover, we extend our framework into the temporal domain with our proposed Temporal Deformable Alignment (TDA) module, which aims to aggregate BEV features from multiple historical frames. Including these two modules, our framework dubbed BEVFusion4D achieves state-of-the-art results in 3D object detection, with 72.0% mAP and 73.5% NDS on the nuScenes validation set, and 73.3% mAP and 74.7% NDS on nuScenes test set, respectively.
RGB Stream Is Enough for Temporal Action Detection
Jul 09, 2021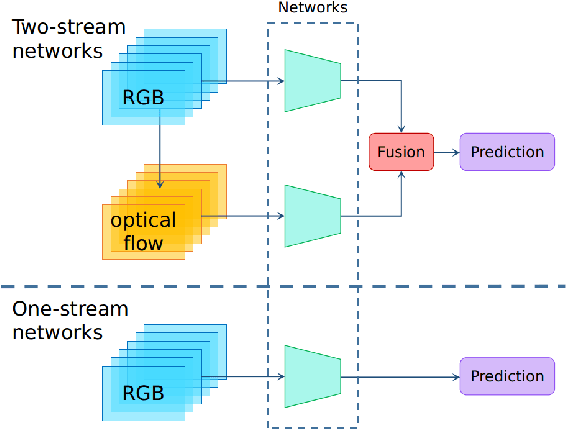
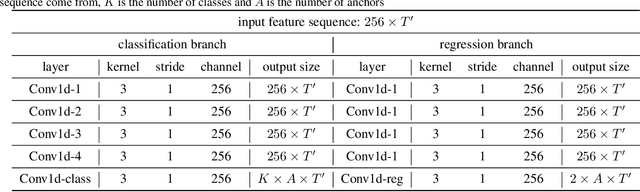
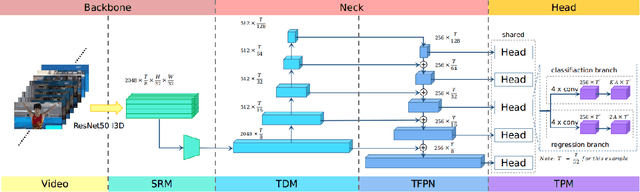
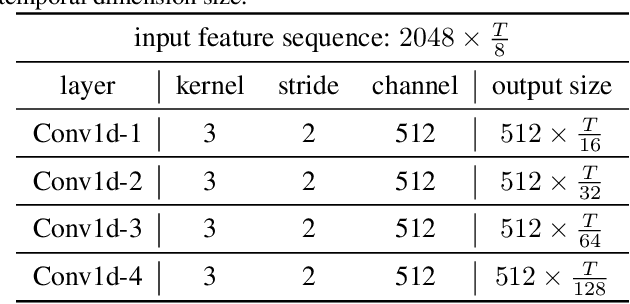
State-of-the-art temporal action detectors to date are based on two-stream input including RGB frames and optical flow. Although combining RGB frames and optical flow boosts performance significantly, optical flow is a hand-designed representation which not only requires heavy computation, but also makes it methodologically unsatisfactory that two-stream methods are often not learned end-to-end jointly with the flow. In this paper, we argue that optical flow is dispensable in high-accuracy temporal action detection and image level data augmentation (ILDA) is the key solution to avoid performance degradation when optical flow is removed. To evaluate the effectiveness of ILDA, we design a simple yet efficient one-stage temporal action detector based on single RGB stream named DaoTAD. Our results show that when trained with ILDA, DaoTAD has comparable accuracy with all existing state-of-the-art two-stream detectors while surpassing the inference speed of previous methods by a large margin and the inference speed is astounding 6668 fps on GeForce GTX 1080 Ti. Code is available at \url{https://github.com/Media-Smart/vedatad}.
An Enhanced Prohibited Items Recognition Model
Feb 24, 2021
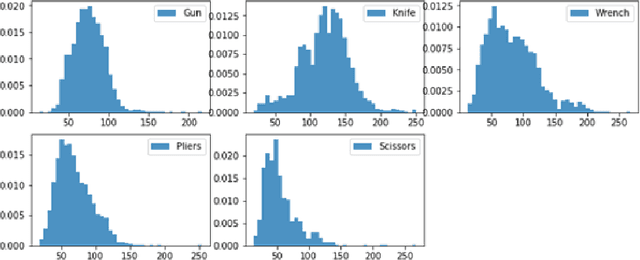


We proposed a new modeling method to promote the performance of prohibited items recognition via X-ray image. We analyzed the characteristics of prohibited items and X-ray images. We found the fact that the scales of some items are too small to be recognized which encumber the model performance. Then we adopted a set of data augmentation and modified the model to adapt the field of prohibited items recognition. The Convolutional Block Attention Module(CBAM) and rescoring mechanism has been assembled into the model. By the modification, our model achieved a mAP of 89.9% on SIXray10, mAP of 74.8%.
CSTR: A Classification Perspective on Scene Text Recognition
Feb 22, 2021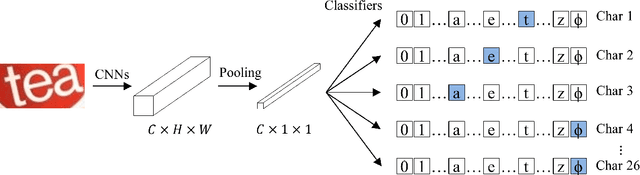
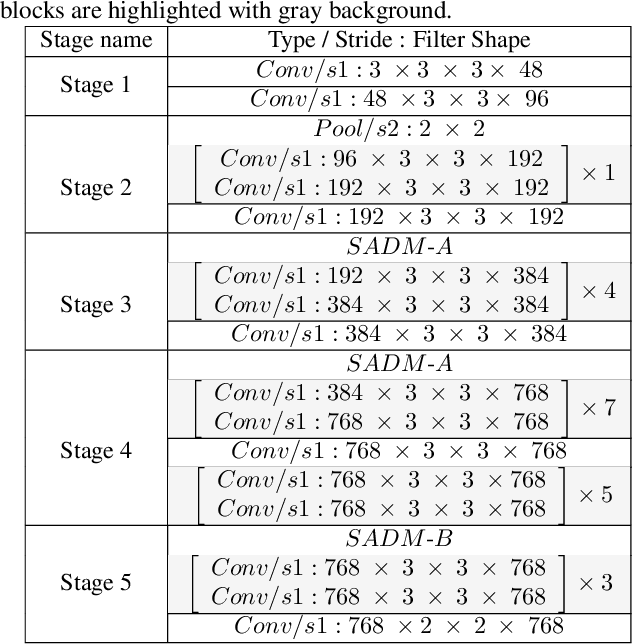
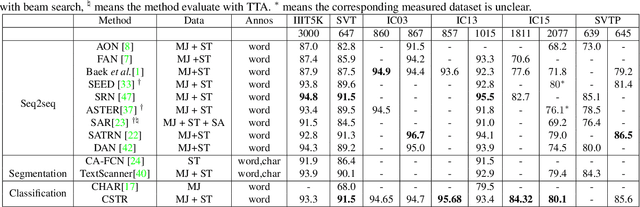
The prevalent perspectives of scene text recognition are from sequence to sequence (seq2seq) and segmentation. In this paper, we propose a new perspective on scene text recognition, in which we model the scene text recognition as an image classification problem. Based on the image classification perspective, a scene text recognition model is proposed, which is named as CSTR. The CSTR model consists of a series of convolutional layers and a global average pooling layer at the end, followed by independent multi-class classification heads, each of which predicts the corresponding character of the word sequence in input image. The CSTR model is easy to train using parallel cross entropy losses. CSTR is as simple as image classification models like ResNet \cite{he2016deep} which makes it easy to implement, and the fully convolutional neural network architecture makes it efficient to train and deploy. We demonstrate the effectiveness of the classification perspective on scene text recognition with thorough experiments. Futhermore, CSTR achieves nearly state-of-the-art performance on six public benchmarks including regular text, irregular text. The code will be available at https://github.com/Media-Smart/vedastr.
TinaFace: Strong but Simple Baseline for Face Detection
Dec 02, 2020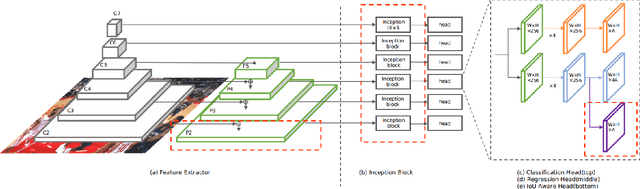
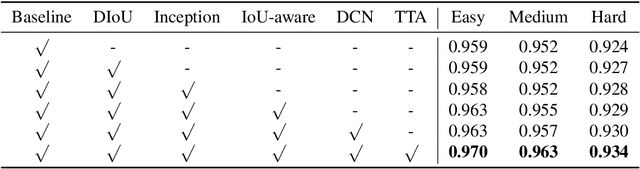
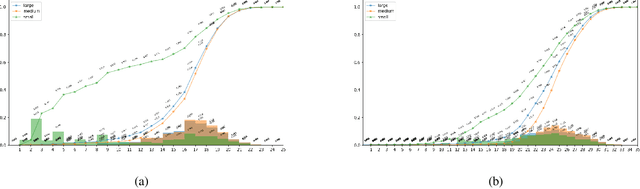
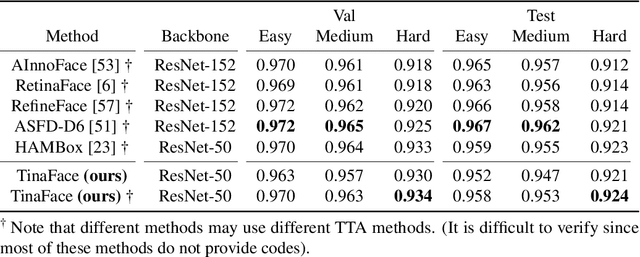
Face detection has received intensive attention in recent years. Many works present lots of special methods for face detection from different perspectives like model architecture, data augmentation, label assignment and etc., which make the overall algorithm and system become more and more complex. In this paper, we point out that \textbf{there is no gap between face detection and generic object detection}. Then we provide a strong but simple baseline method to deal with face detection named TinaFace. We use ResNet-50 \cite{he2016deep} as backbone, and all modules and techniques in TinaFace are constructed on existing modules, easily implemented and based on generic object detection. On the hard test set of the most popular and challenging face detection benchmark WIDER FACE \cite{yang2016wider}, with single-model and single-scale, our TinaFace achieves 92.1\% average precision (AP), which exceeds most of the recent face detectors with larger backbone. And after using test time augmentation (TTA), our TinaFace outperforms the current state-of-the-art method and achieves 92.4\% AP. The code will be available at \url{https://github.com/Media-Smart/vedadet}.
A Solution to Product detection in Densely Packed Scenes
Jul 23, 2020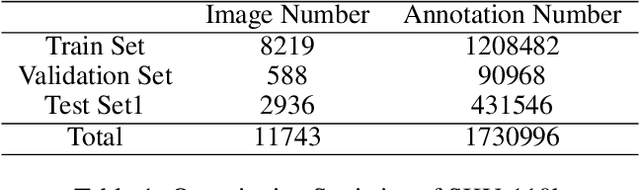
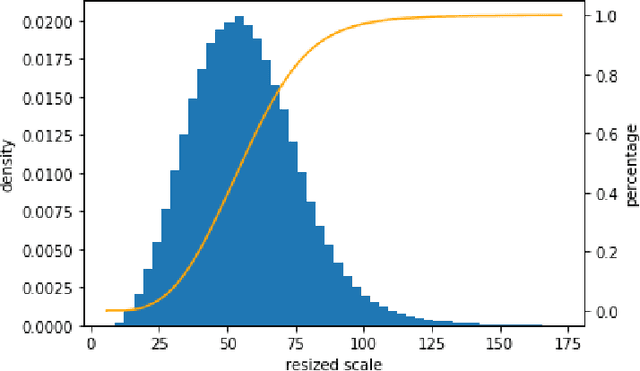


This work is a solution to densely packed scenes dataset SKU-110k. Our work is modified from cascade R-CNN. To solve the problem, we proposed a random crop strategy to ensure both the sampling rate and input scale is relatively sufficient as a contrast to the regular random crop. And we adopted some of trick and optimized the hyper-parameters. To grasp the essential feature of the densely packed scenes, we analysis the stages of a detector and investigate the bottleneck which limits the performance. As a result, our method obtains 58.7 mAP on test set of SKU-110k.