 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaFlowTSE: One-Step Generative Target Speaker Extraction via Conditional AlphaFlow
Mar 11, 2026In target speaker extraction (TSE), we aim to recover target speech from a multi-talker mixture using a short enrollment utterance as reference. Recent studies on diffusion and flow-matching generators have improved target-speech fidelity. However, multi-step sampling increases latency, and one-step solutions often rely on a mixture-dependent time coordinate that can be unreliable for real-world conversations. We present AlphaFlowTSE, a one-step conditional generative model trained with a Jacobian-vector product (JVP)-free AlphaFlow objective. AlphaFlowTSE learns mean-velocity transport along a mixture-to-target trajectory starting from the observed mixture, eliminating auxiliary mixing-ratio prediction, and stabilizes training by combining flow matching with an interval-consistency teacher-student target. Experiments on Libri2Mix and REAL-T confirm that AlphaFlowTSE improves target-speaker similarity and real-mixture generalization for downstream automatic speech recognition (ASR).
Wasserstein Proximal Policy Gradient
Mar 03, 2026We study policy gradient methods for continuous-action, entropy-regularized reinforcement learning through the lens of Wasserstein geometry. Starting from a Wasserstein proximal update, we derive Wasserstein Proximal Policy Gradient (WPPG) via an operator-splitting scheme that alternates an optimal transport update with a heat step implemented by Gaussian convolution. This formulation avoids evaluating the policy's log density or its gradient, making the method directly applicable to expressive implicit stochastic policies specified as pushforward maps. We establish a global linear convergence rate for WPPG, covering both exact policy evaluation and actor-critic implementations with controlled approximation error. Empirically, WPPG is simple to implement and attains competitive performance on standard continuous-control benchmarks.
DeepHalo: A Neural Choice Model with Controllable Context Effects
Jan 08, 2026Modeling human decision-making is central to applications such as recommendation, preference learning, and human-AI alignment. While many classic models assume context-independent choice behavior, a large body of behavioral research shows that preferences are often influenced by the composition of the choice set itself -- a phenomenon known as the context effect or Halo effect. These effects can manifest as pairwise (first-order) or even higher-order interactions among the available alternatives. Recent models that attempt to capture such effects either focus on the featureless setting or, in the feature-based setting, rely on restrictive interaction structures or entangle interactions across all orders, which limits interpretability. In this work, we propose DeepHalo, a neural modeling framework that incorporates features while enabling explicit control over interaction order and principled interpretation of context effects. Our model enables systematic identification of interaction effects by order and serves as a universal approximator of context-dependent choice functions when specialized to a featureless setting. Experiments on synthetic and real-world datasets demonstrate strong predictive performance while providing greater transparency into the drivers of choice.
Relative Localization System Design for SnailBot: A Modular Self-reconfigurable Robot
Dec 24, 2025This paper presents the design and implementation of a relative localization system for SnailBot, a modular self reconfigurable robot. The system integrates ArUco marker recognition, optical flow analysis, and IMU data processing into a unified fusion framework, enabling robust and accurate relative positioning for collaborative robotic tasks. Experimental validation demonstrates the effectiveness of the system in realtime operation, with a rule based fusion strategy ensuring reliability across dynamic scenarios. The results highlight the potential for scalable deployment in modular robotic systems.
CAD-Coder:Text-Guided CAD Files Code Generation
May 13, 2025



Computer-aided design (CAD) is a way to digitally create 2D drawings and 3D models of real-world products. Traditional CAD typically relies on hand-drawing by experts or modifications of existing library files, which doesn't allow for rapid personalization. With the emergence of generative artificial intelligence, convenient and efficient personalized CAD generation has become possible. However, existing generative methods typically produce outputs that lack interactive editability and geometric annotations, limiting their practical applications in manufacturing. To enable interactive generative CAD, we propose CAD-Coder, a framework that transforms natural language instructions into CAD script codes, which can be executed in Python environments to generate human-editable CAD files (.Dxf). To facilitate the generation of editable CAD sketches with annotation information, we construct a comprehensive dataset comprising 29,130 Dxf files with their corresponding script codes, where each sketch preserves both editability and geometric annotations. We evaluate CAD-Coder on various 2D/3D CAD generation tasks against existing methods, demonstrating superior interactive capabilities while uniquely providing editable sketches with geometric annotations.
Ultra Light OCR Competition Technical Report
Oct 25, 2021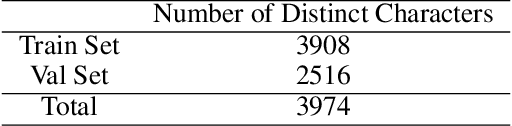
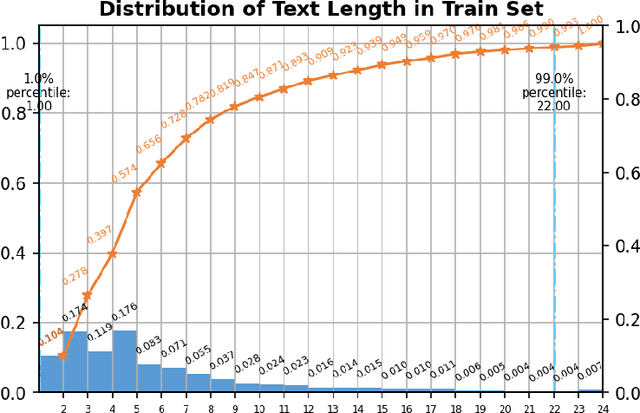

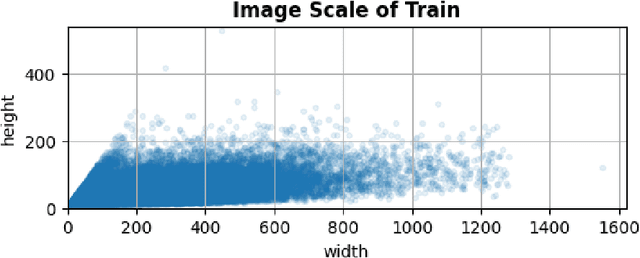
Ultra Light OCR Competition is a Chinese scene text recognition competition jointly organized by CSIG (China Society of Image and Graphics) and Baidu, Inc. In addition to focusing on common problems in Chinese scene text recognition, such as long text length and massive characters, we need to balance the trade-off of model scale and accuracy since the model size limitation in the competition is 10M. From experiments in aspects of data, model, training, etc, we proposed a general and effective method for Chinese scene text recognition, which got us second place among over 100 teams with accuracy 0.817 in TestB dataset. The code is available at https://aistudio.baidu.com/aistudio/projectdetail/2159102.
LinEasyBO: Scalable Bayesian Optimization Approach for Analog Circuit Synthesis via One-Dimensional Subspaces
Sep 01, 2021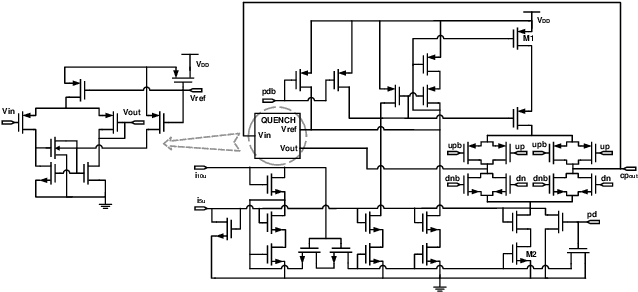
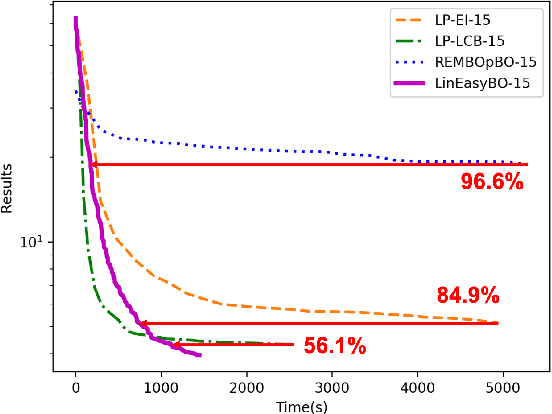
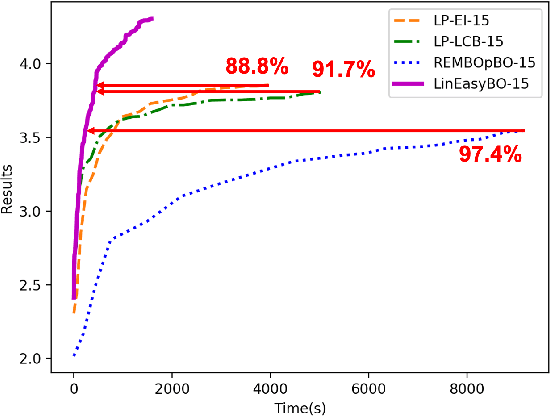
A large body of literature has proved that the Bayesian optimization framework is especially efficient and effective in analog circuit synthesis. However, most of the previous research works only focus on designing informative surrogate models or efficient acquisition functions. Even if searching for the global optimum over the acquisition function surface is itself a difficult task, it has been largely ignored. In this paper, we propose a fast and robust Bayesian optimization approach via one-dimensional subspaces for analog circuit synthesis. By solely focusing on optimizing one-dimension subspaces at each iteration, we greatly reduce the computational overhead of the Bayesian optimization framework while safely maximizing the acquisition function. By combining the benefits of different dimension selection strategies, we adaptively balancing between searching globally and locally. By leveraging the batch Bayesian optimization framework, we further accelerate the optimization procedure by making full use of the hardware resources. Experimental results quantitatively show that our proposed algorithm can accelerate the optimization procedure by up to 9x and 38x compared to LP-EI and REMBOpBO respectively when the batch size is 15.
An Efficient Batch Constrained Bayesian Optimization Approach for Analog Circuit Synthesis via Multi-objective Acquisition Ensemble
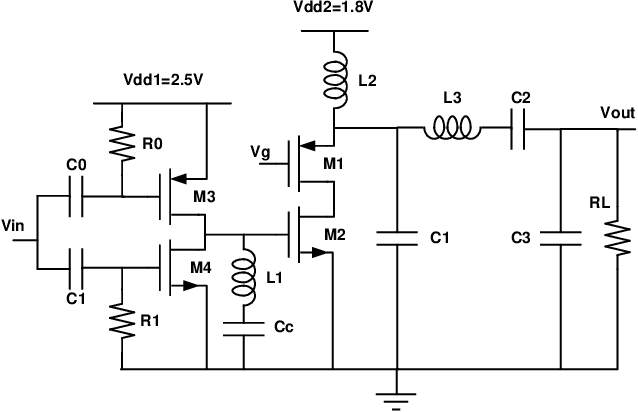
Jun 28, 2021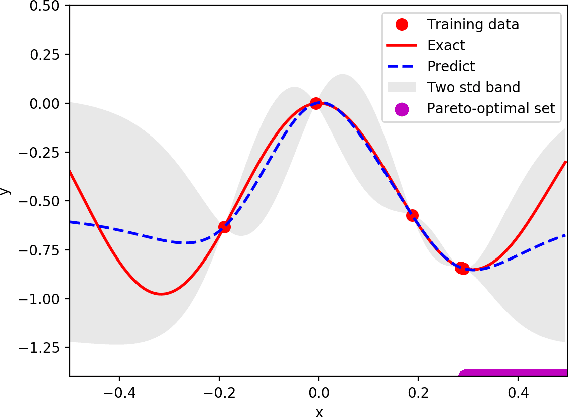
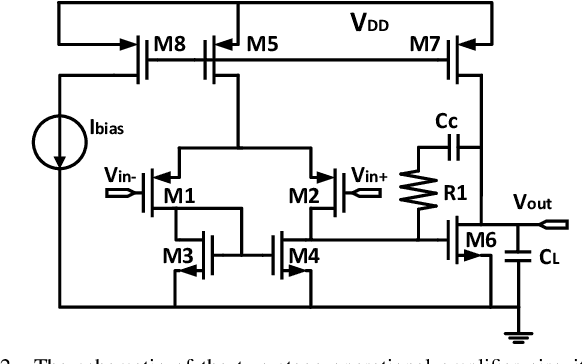
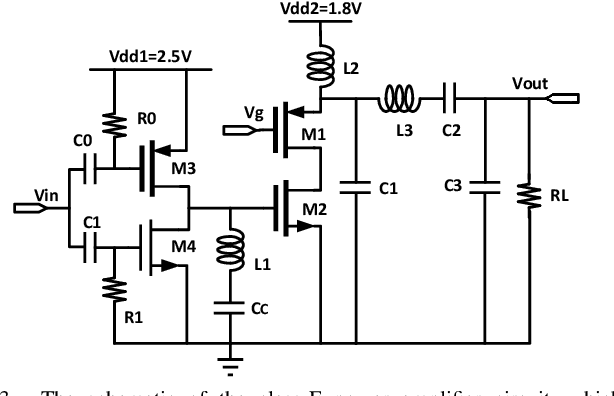
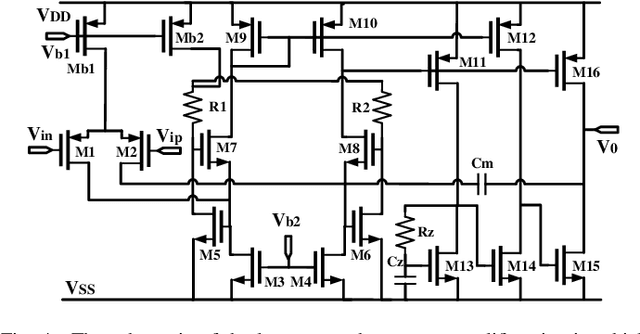
Bayesian optimization is a promising methodology for analog circuit synthesis. However, the sequential nature of the Bayesian optimization framework significantly limits its ability to fully utilize real-world computational resources. In this paper, we propose an efficient parallelizable Bayesian optimization algorithm via Multi-objective ACquisition function Ensemble (MACE) to further accelerate the optimization procedure. By sampling query points from the Pareto front of the probability of improvement (PI), expected improvement (EI) and lower confidence bound (LCB), we combine the benefits of state-of-the-art acquisition functions to achieve a delicate tradeoff between exploration and exploitation for the unconstrained optimization problem. Based on this batch design, we further adjust the algorithm for the constrained optimization problem. By dividing the optimization procedure into two stages and first focusing on finding an initial feasible point, we manage to gain more information about the valid region and can better avoid sampling around the infeasible area. After achieving the first feasible point, we favor the feasible region by adopting a specially designed penalization term to the acquisition function ensemble. The experimental results quantitatively demonstrate that our proposed algorithm can reduce the overall simulation time by up to 74 times compared to differential evolution (DE) for the unconstrained optimization problem when the batch size is 15. For the constrained optimization problem, our proposed algorithm can speed up the optimization process by up to 15 times compared to the weighted expected improvement based Bayesian optimization (WEIBO) approach, when the batch size is 15.
BigCarl: Mining frequent subnets from a single large Petri net
Mar 21, 2021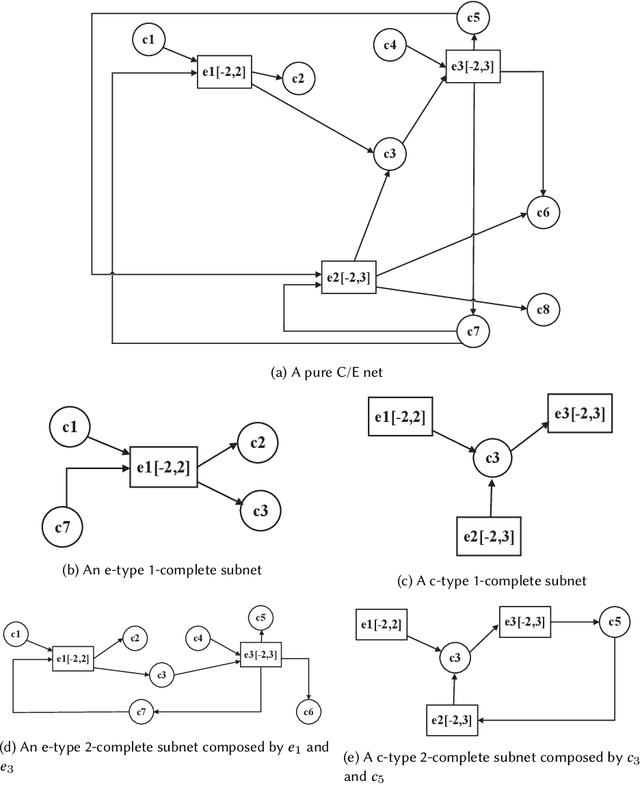

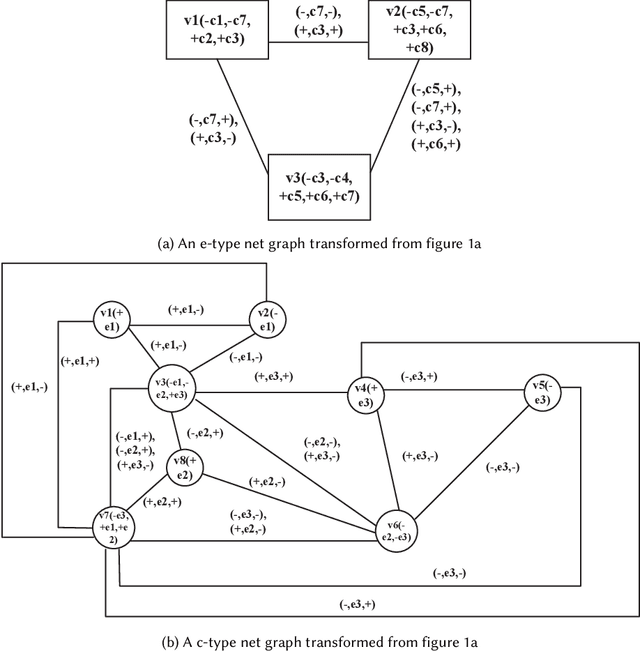
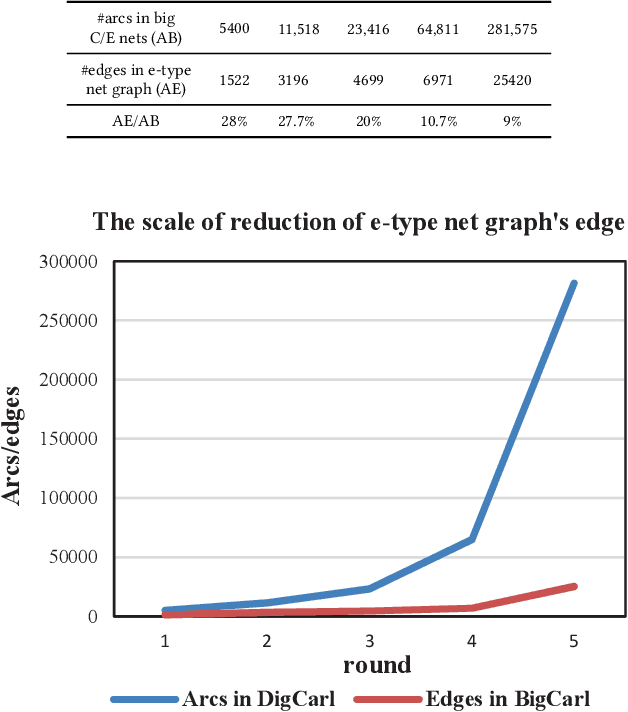
While there have been lots of work studying frequent subgraph mining, very rare publications have discussed frequent subnet mining from more complicated data structures such as Petri nets. This paper studies frequent subnets mining from a single large Petri net. We follow the idea of transforming a Petri net in net graph form and to mine frequent sub-net graphs to avoid high complexity. Technically, we take a minimal traversal approach to produce a canonical label of the big net graph. We adapted the maximal independent embedding set approach to the net graph representation and proposed an incremental pattern growth (independent embedding set reduction) way for discovering frequent sub-net graphs from the single large net graph, which are finally transformed back to frequent subnets. Extensive performance studies made on a single large Petri net, which contains 10K events, 40K conditions and 30 K arcs, showed that our approach is correct and the complexity is reasonable.
PSpan:Mining Frequent Subnets of Petri Nets
Jan 28, 2021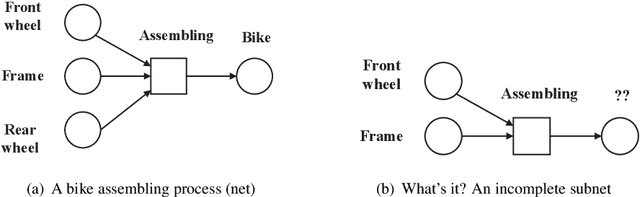

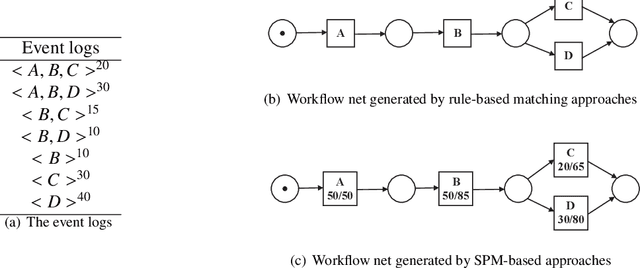
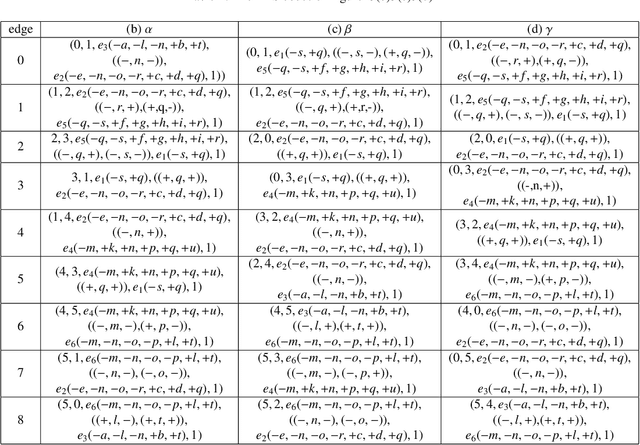
This paper proposes for the first time an algorithm PSpan for mining frequent complete subnets from a set of Petri nets. We introduced the concept of complete subnets and the net graph representation. PSpan transforms Petri nets in net graphs and performs sub-net graph mining on them, then transforms the results back to frequent subnets. PSpan follows the pattern growth approach and has similar complexity like gSpan in graph mining. Experiments have been done to confirm PSpan's reliability and complexity. Besides C/E nets, it applies also to a set of other Petri net subclasses.