 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogic Programming on Knowledge Graph Networks And its Application in Medical Domain
Jan 21, 2026The rash development of knowledge graph research has brought big driving force to its application in many areas, including the medicine and healthcare domain. However, we have found that the application of some major information processing techniques on knowledge graph still lags behind. This defect includes the failure to make sufficient use of advanced logic reasoning, advanced artificial intelligence techniques, special-purpose programming languages, modern probabilistic and statistic theories et al. on knowledge graphs development and application. In particular, the multiple knowledge graphs cooperation and competition techniques have not got enough attention from researchers. This paper develops a systematic theory, technique and application of the concept 'knowledge graph network' and its application in medical and healthcare domain. Our research covers its definition, development, reasoning, computing and application under different conditions such as unsharp, uncertain, multi-modal, vectorized, distributed, federated. Almost in each case we provide (real data) examples and experiment results. Finally, a conclusion of innovation is provided.
BigCarl: Mining frequent subnets from a single large Petri net
Mar 21, 2021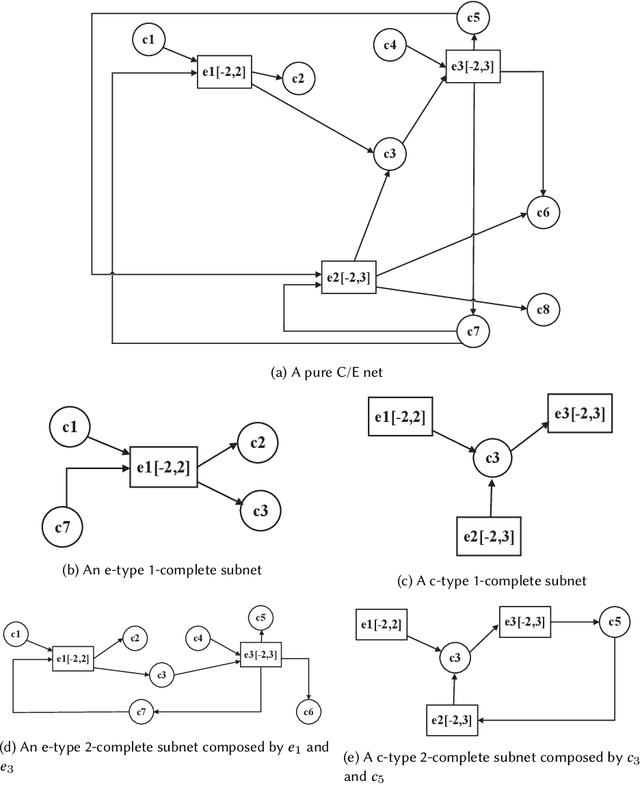

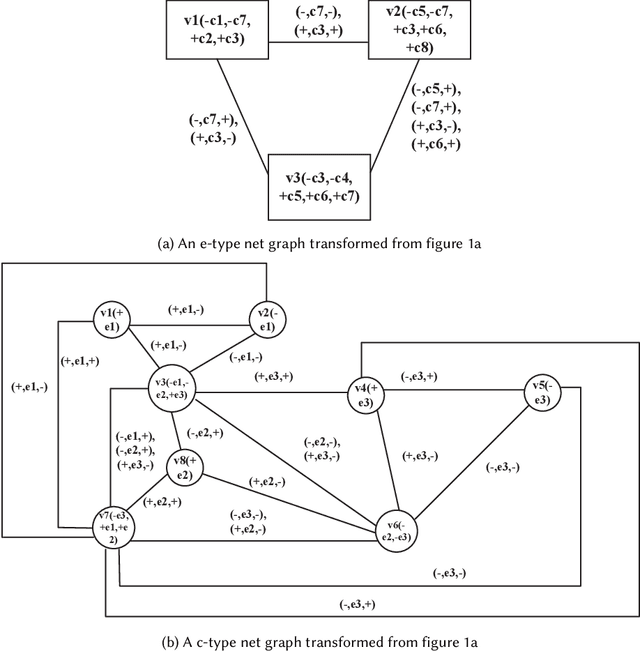
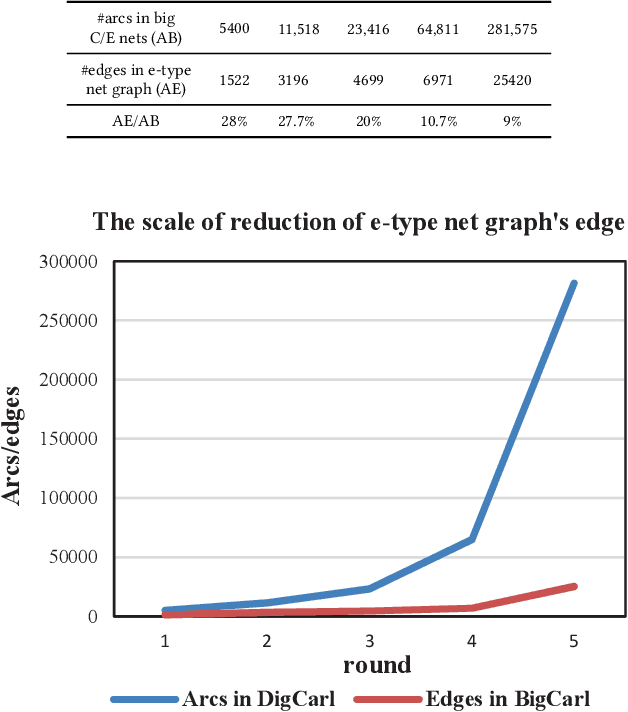
While there have been lots of work studying frequent subgraph mining, very rare publications have discussed frequent subnet mining from more complicated data structures such as Petri nets. This paper studies frequent subnets mining from a single large Petri net. We follow the idea of transforming a Petri net in net graph form and to mine frequent sub-net graphs to avoid high complexity. Technically, we take a minimal traversal approach to produce a canonical label of the big net graph. We adapted the maximal independent embedding set approach to the net graph representation and proposed an incremental pattern growth (independent embedding set reduction) way for discovering frequent sub-net graphs from the single large net graph, which are finally transformed back to frequent subnets. Extensive performance studies made on a single large Petri net, which contains 10K events, 40K conditions and 30 K arcs, showed that our approach is correct and the complexity is reasonable.
PSpan:Mining Frequent Subnets of Petri Nets
Jan 28, 2021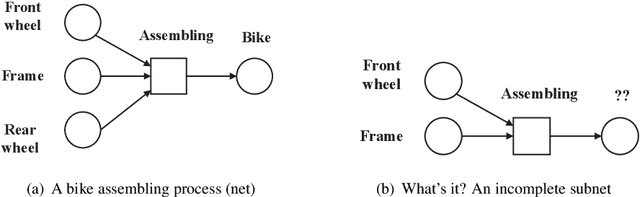

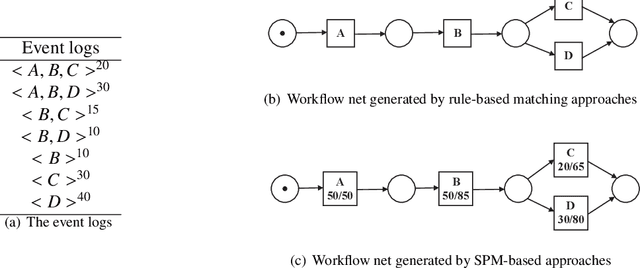
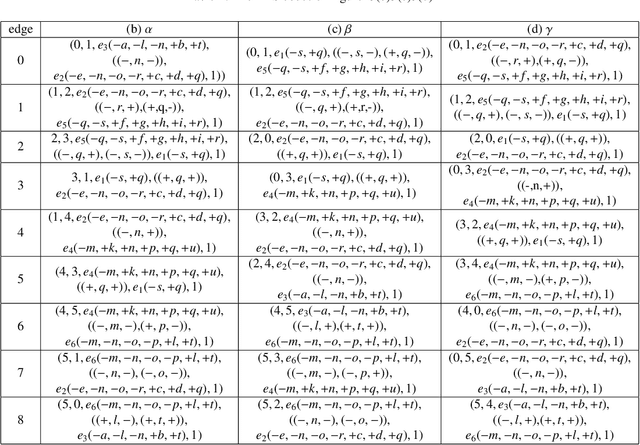
This paper proposes for the first time an algorithm PSpan for mining frequent complete subnets from a set of Petri nets. We introduced the concept of complete subnets and the net graph representation. PSpan transforms Petri nets in net graphs and performs sub-net graph mining on them, then transforms the results back to frequent subnets. PSpan follows the pattern growth approach and has similar complexity like gSpan in graph mining. Experiments have been done to confirm PSpan's reliability and complexity. Besides C/E nets, it applies also to a set of other Petri net subclasses.
On Semi-Supervised Multiple Representation Behavior Learning
Oct 21, 2019


We propose a novel paradigm of semi-supervised learning (SSL)--the semi-supervised multiple representation behavior learning (SSMRBL). SSMRBL aims to tackle the difficulty of learning a grammar for natural language parsing where the data are natural language texts and the 'labels' for marking data are parsing trees and/or grammar rule pieces. We call such 'labels' as compound structured labels which require a hard work for training. SSMRBL is an incremental learning process that can learn more than one representation, which is an appropriate solution for dealing with the scarce of labeled training data in the age of big data and with the heavy workload of learning compound structured labels. We also present a typical example of SSMRBL, regarding behavior learning in form of a grammatical approach towards domain-based multiple text summarization (DBMTS). DBMTS works under the framework of rhetorical structure theory (RST). SSMRBL includes two representations: text embedding (for representing information contained in the texts) and grammar model (for representing parsing as a behavior). The first representation was learned as embedded digital vectors called impacts in a low dimensional space. The grammar model was learned in an iterative way. Then an automatic domain-oriented multi-text summarization approach was proposed based on the two representations discussed above. Experimental results on large-scale Chinese dataset SogouCA indicate that the proposed method brings a good performance even if only few labeled texts are used for training with respect to our defined automated metrics.
Knowledge-guided Unsupervised Rhetorical Parsing for Text Summarization
Oct 14, 2019

Automatic text summarization (ATS) has recently achieved impressive performance thanks to recent advances in deep learning and the availability of large-scale corpora. To make the summarization results more faithful, this paper presents an unsupervised approach that combines rhetorical structure theory, deep neural model and domain knowledge concern for ATS. This architecture mainly contains three components: domain knowledge base construction based on representation learning, attentional encoder-decoder model for rhetorical parsing and subroutine-based model for text summarization. Domain knowledge can be effectively used for unsupervised rhetorical parsing thus rhetorical structure trees for each document can be derived. In the unsupervised rhetorical parsing module, the idea of translation was adopted to alleviate the problem of data scarcity. The subroutine-based summarization model purely depends on the derived rhetorical structure trees and can generate content-balanced results. To evaluate the summary results without golden standard, we proposed an unsupervised evaluation metric, whose hyper-parameters were tuned by supervised learning. Experimental results show that, on a large-scale Chinese dataset, our proposed approach can obtain comparable performances compared with existing methods.
Attributed Rhetorical Structure Grammar for Domain Text Summarization
Sep 03, 2019


This paper presents a new approach of automatic text summarization which combines domain oriented text analysis (DoTA) and rhetorical structure theory (RST) in a grammar form: the attributed rhetorical structure grammar (ARSG), where the non-terminal symbols are domain keywords, called domain relations, while the rhetorical relations serve as attributes. We developed machine learning algorithms for learning such a grammar from a corpus of sample domain texts, as well as parsing algorithms for the learned grammar, together with adjustable text summarization algorithms for generating domain specific summaries. Our practical experiments have shown that with support of domain knowledge the drawback of missing very large training data set can be effectively compensated. We have also shown that the knowledge based approach may be made more powerful by introducing grammar parsing and RST as inference engine. For checking the feasibility of model transfer, we introduced a technique for mapping a grammar from one domain to others with acceptable cost. We have also made a comprehensive comparison of our approach with some others.
Locality preserving projection on SPD matrix Lie group: algorithm and analysis
Nov 16, 2017


Symmetric positive definite (SPD) matrices used as feature descriptors in image recognition are usually high dimensional. Traditional manifold learning is only applicable for reducing the dimension of high-dimensional vector-form data. For high-dimensional SPD matrices, directly using manifold learning algorithms to reduce the dimension of matrix-form data is impossible. The SPD matrix must first be transformed into a long vector, and then the dimension of this vector must be reduced. However, this approach breaks the spatial structure of the SPD matrix space. To overcome this limitation, we propose a new dimension reduction algorithm on SPD matrix space to transform high-dimensional SPD matrices into low-dimensional SPD matrices. Our work is based on the fact that the set of all SPD matrices with the same size has a Lie group structure, and we aim to transform the manifold learning to the SPD matrix Lie group. We use the basic idea of the manifold learning algorithm called locality preserving projection (LPP) to construct the corresponding Laplacian matrix on the SPD matrix Lie group. Thus, we call our approach Lie-LPP to emphasize its Lie group character. We present a detailed algorithm analysis and show through experiments that Lie-LPP achieves effective results on human action recognition and human face recognition.
Applying Ricci Flow to High Dimensional Manifold Learning
Nov 16, 2017



Traditional manifold learning algorithms often bear an assumption that the local neighborhood of any point on embedded manifold is roughly equal to the tangent space at that point without considering the curvature. The curvature indifferent way of manifold processing often makes traditional dimension reduction poorly neighborhood preserving. To overcome this drawback we propose a new algorithm called RF-ML to perform an operation on the manifold with help of Ricci flow before reducing the dimension of manifold.
Knowware: the third star after Hardware and Software
Nov 27, 2007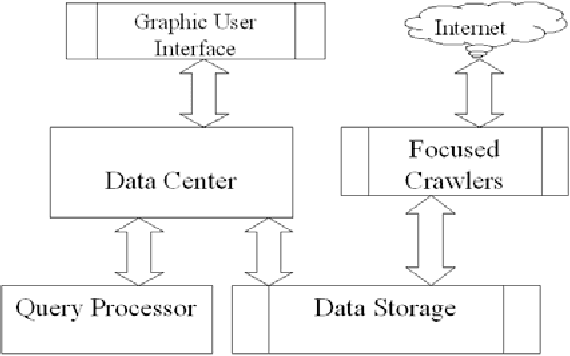
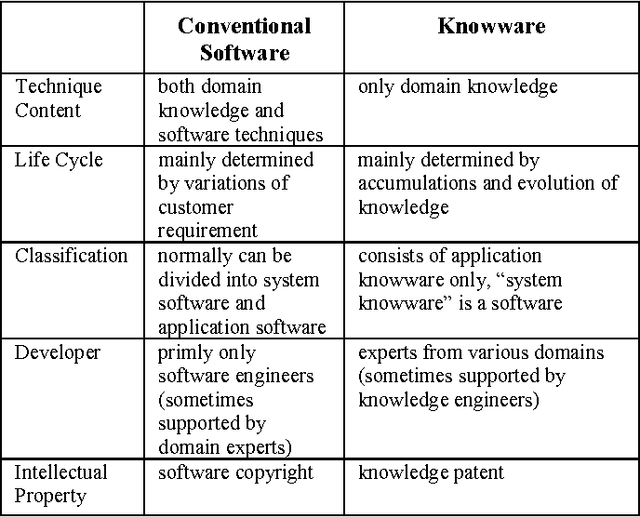


This book proposes to separate knowledge from software and to make it a commodity that is called knowware. The architecture, representation and function of Knowware are discussed. The principles of knowware engineering and its three life cycle models: furnace model, crystallization model and spiral model are proposed and analyzed. Techniques of software/knowware co-engineering are introduced. A software component whose knowledge is replaced by knowware is called mixware. An object and component oriented development schema of mixware is introduced. In particular, the tower model and ladder model for mixware development are proposed and discussed. Finally, knowledge service and knowware based Web service are introduced and compared with Web service. In summary, knowware, software and hardware should be considered as three equally important underpinnings of IT industry. Ruqian Lu is a professor of computer science of the Institute of Mathematics, Academy of Mathematics and System Sciences. He is a fellow of Chinese Academy of Sciences. His research interests include artificial intelligence, knowledge engineering and knowledge based software engineering. He has published more than 100 papers and 10 books. He has won two first class awards from the Academia Sinica and a National second class prize from the Ministry of Science and Technology. He has also won the sixth Hua Loo-keng Mathematics Prize.
* 109 pages, ISBN 978-88-7699-095-3 (Printed edition), ISBN 978-88-7699-096-0 (Electronic edition), printed edition available on Amazon and on Lulu.com