 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogic Programming on Knowledge Graph Networks And its Application in Medical Domain
Jan 21, 2026The rash development of knowledge graph research has brought big driving force to its application in many areas, including the medicine and healthcare domain. However, we have found that the application of some major information processing techniques on knowledge graph still lags behind. This defect includes the failure to make sufficient use of advanced logic reasoning, advanced artificial intelligence techniques, special-purpose programming languages, modern probabilistic and statistic theories et al. on knowledge graphs development and application. In particular, the multiple knowledge graphs cooperation and competition techniques have not got enough attention from researchers. This paper develops a systematic theory, technique and application of the concept 'knowledge graph network' and its application in medical and healthcare domain. Our research covers its definition, development, reasoning, computing and application under different conditions such as unsharp, uncertain, multi-modal, vectorized, distributed, federated. Almost in each case we provide (real data) examples and experiment results. Finally, a conclusion of innovation is provided.
SpikeSEE: An Energy-Efficient Dynamic Scenes Processing Framework for Retinal Prostheses
Sep 16, 2022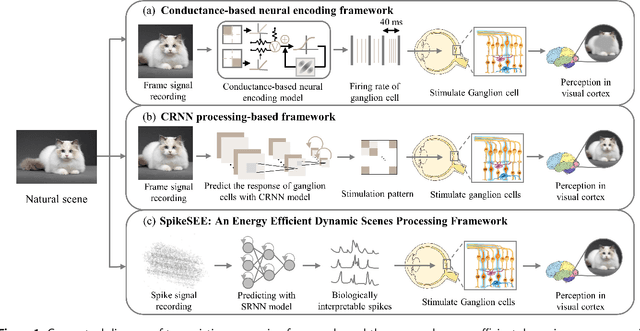
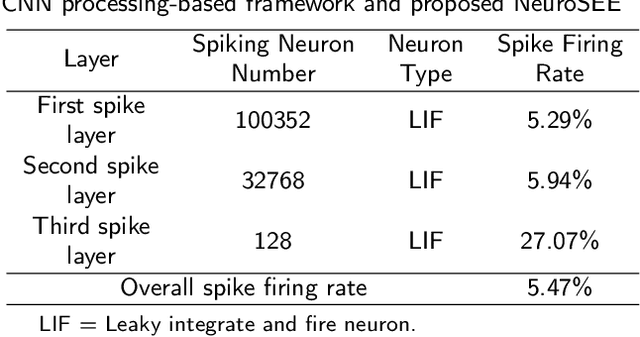
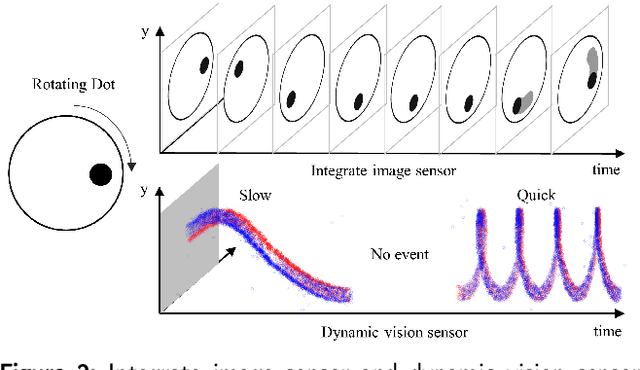
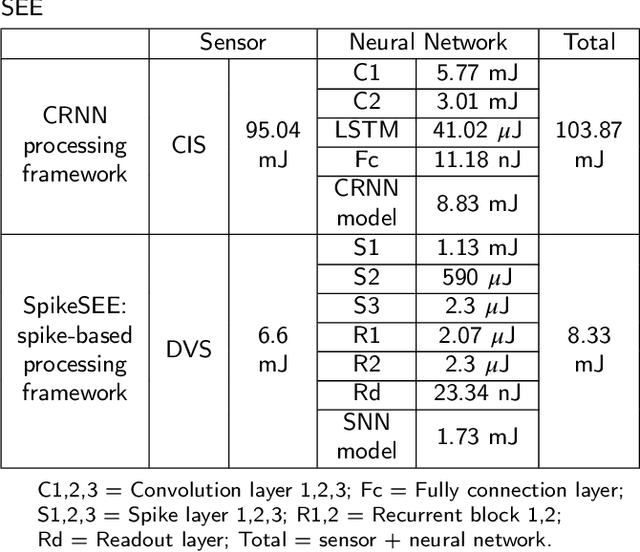
Intelligent and low-power retinal prostheses are highly demanded in this era, where wearable and implantable devices are used for numerous healthcare applications. In this paper, we propose an energy-efficient dynamic scenes processing framework (SpikeSEE) that combines a spike representation encoding technique and a bio-inspired spiking recurrent neural network (SRNN) model to achieve intelligent processing and extreme low-power computation for retinal prostheses. The spike representation encoding technique could interpret dynamic scenes with sparse spike trains, decreasing the data volume. The SRNN model, inspired by the human retina special structure and spike processing method, is adopted to predict the response of ganglion cells to dynamic scenes. Experimental results show that the Pearson correlation coefficient of the proposed SRNN model achieves 0.93, which outperforms the state of the art processing framework for retinal prostheses. Thanks to the spike representation and SRNN processing, the model can extract visual features in a multiplication-free fashion. The framework achieves 12 times power reduction compared with the convolutional recurrent neural network (CRNN) processing-based framework. Our proposed SpikeSEE predicts the response of ganglion cells more accurately with lower energy consumption, which alleviates the precision and power issues of retinal prostheses and provides a potential solution for wearable or implantable prostheses.
Attributed Rhetorical Structure Grammar for Domain Text Summarization
Sep 03, 2019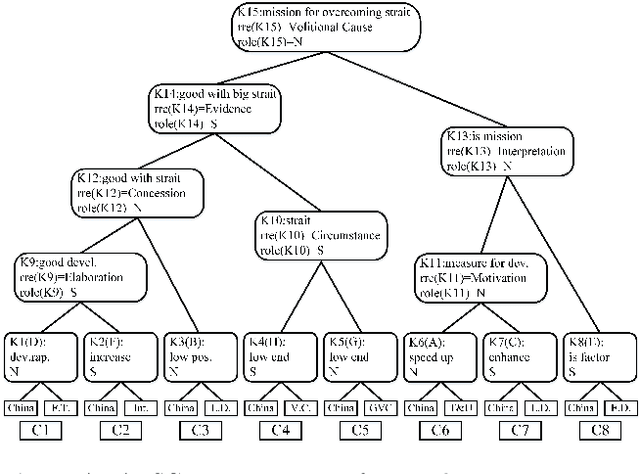


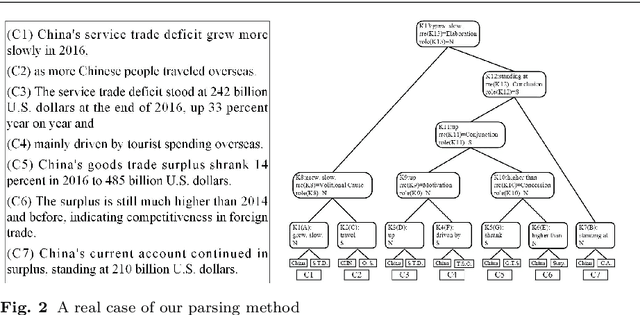
This paper presents a new approach of automatic text summarization which combines domain oriented text analysis (DoTA) and rhetorical structure theory (RST) in a grammar form: the attributed rhetorical structure grammar (ARSG), where the non-terminal symbols are domain keywords, called domain relations, while the rhetorical relations serve as attributes. We developed machine learning algorithms for learning such a grammar from a corpus of sample domain texts, as well as parsing algorithms for the learned grammar, together with adjustable text summarization algorithms for generating domain specific summaries. Our practical experiments have shown that with support of domain knowledge the drawback of missing very large training data set can be effectively compensated. We have also shown that the knowledge based approach may be made more powerful by introducing grammar parsing and RST as inference engine. For checking the feasibility of model transfer, we introduced a technique for mapping a grammar from one domain to others with acceptable cost. We have also made a comprehensive comparison of our approach with some others.