 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikiformer: Pre-training with Structured Information of Wikipedia for Ad-hoc Retrieval
Jan 01, 2024
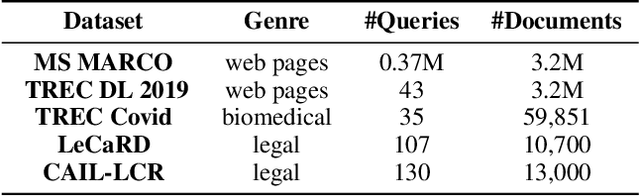
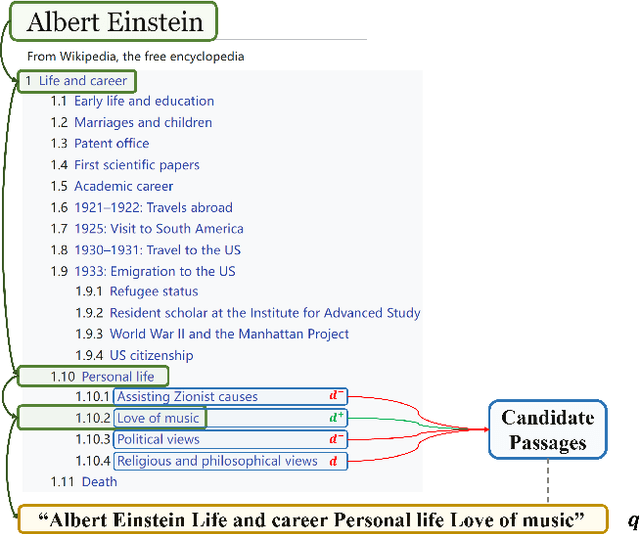
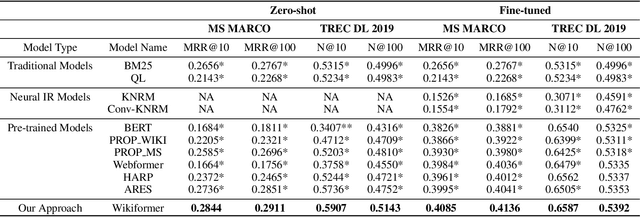
With the development of deep learning and natural language processing techniques, pre-trained language models have been widely used to solve information retrieval (IR) problems. Benefiting from the pre-training and fine-tuning paradigm, these models achieve state-of-the-art performance. In previous works, plain texts in Wikipedia have been widely used in the pre-training stage. However, the rich structured information in Wikipedia, such as the titles, abstracts, hierarchical heading (multi-level title) structure, relationship between articles, references, hyperlink structures, and the writing organizations, has not been fully explored. In this paper, we devise four pre-training objectives tailored for IR tasks based on the structured knowledge of Wikipedia. Compared to existing pre-training methods, our approach can better capture the semantic knowledge in the training corpus by leveraging the human-edited structured data from Wikipedia. Experimental results on multiple IR benchmark datasets show the superior performance of our model in both zero-shot and fine-tuning settings compared to existing strong retrieval baselines. Besides, experimental results in biomedical and legal domains demonstrate that our approach achieves better performance in vertical domains compared to previous models, especially in scenarios where long text similarity matching is needed.
On Semi-Supervised Multiple Representation Behavior Learning
Oct 21, 2019


We propose a novel paradigm of semi-supervised learning (SSL)--the semi-supervised multiple representation behavior learning (SSMRBL). SSMRBL aims to tackle the difficulty of learning a grammar for natural language parsing where the data are natural language texts and the 'labels' for marking data are parsing trees and/or grammar rule pieces. We call such 'labels' as compound structured labels which require a hard work for training. SSMRBL is an incremental learning process that can learn more than one representation, which is an appropriate solution for dealing with the scarce of labeled training data in the age of big data and with the heavy workload of learning compound structured labels. We also present a typical example of SSMRBL, regarding behavior learning in form of a grammatical approach towards domain-based multiple text summarization (DBMTS). DBMTS works under the framework of rhetorical structure theory (RST). SSMRBL includes two representations: text embedding (for representing information contained in the texts) and grammar model (for representing parsing as a behavior). The first representation was learned as embedded digital vectors called impacts in a low dimensional space. The grammar model was learned in an iterative way. Then an automatic domain-oriented multi-text summarization approach was proposed based on the two representations discussed above. Experimental results on large-scale Chinese dataset SogouCA indicate that the proposed method brings a good performance even if only few labeled texts are used for training with respect to our defined automated metrics.
Knowledge-guided Unsupervised Rhetorical Parsing for Text Summarization
Oct 14, 2019

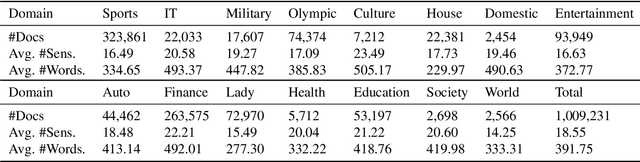
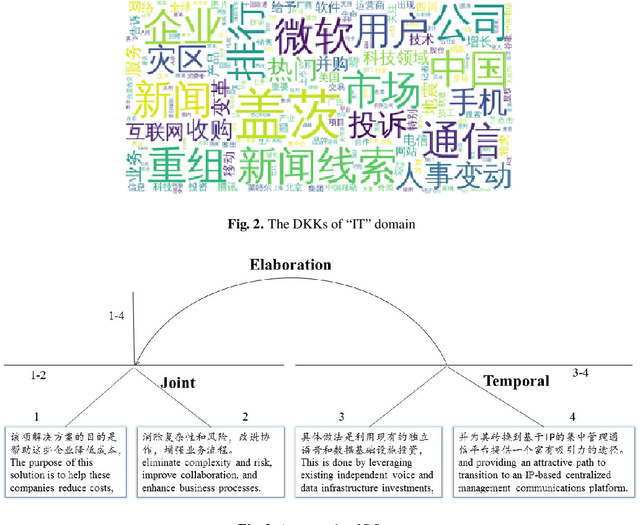
Automatic text summarization (ATS) has recently achieved impressive performance thanks to recent advances in deep learning and the availability of large-scale corpora. To make the summarization results more faithful, this paper presents an unsupervised approach that combines rhetorical structure theory, deep neural model and domain knowledge concern for ATS. This architecture mainly contains three components: domain knowledge base construction based on representation learning, attentional encoder-decoder model for rhetorical parsing and subroutine-based model for text summarization. Domain knowledge can be effectively used for unsupervised rhetorical parsing thus rhetorical structure trees for each document can be derived. In the unsupervised rhetorical parsing module, the idea of translation was adopted to alleviate the problem of data scarcity. The subroutine-based summarization model purely depends on the derived rhetorical structure trees and can generate content-balanced results. To evaluate the summary results without golden standard, we proposed an unsupervised evaluation metric, whose hyper-parameters were tuned by supervised learning. Experimental results show that, on a large-scale Chinese dataset, our proposed approach can obtain comparable performances compared with existing methods.
Attributed Rhetorical Structure Grammar for Domain Text Summarization
Sep 03, 2019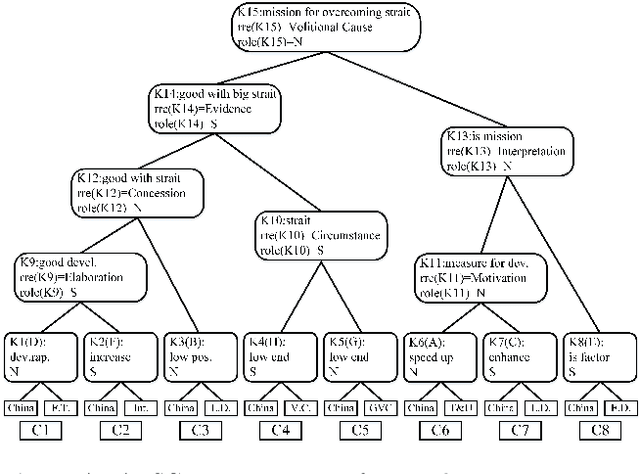


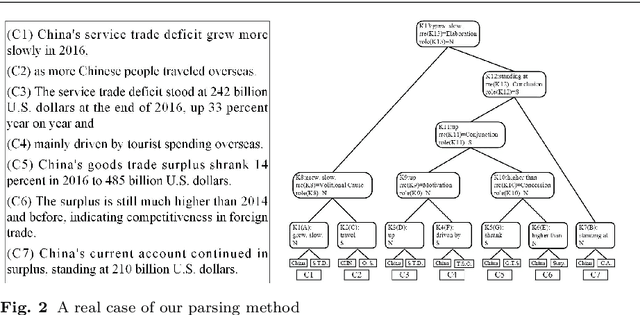
This paper presents a new approach of automatic text summarization which combines domain oriented text analysis (DoTA) and rhetorical structure theory (RST) in a grammar form: the attributed rhetorical structure grammar (ARSG), where the non-terminal symbols are domain keywords, called domain relations, while the rhetorical relations serve as attributes. We developed machine learning algorithms for learning such a grammar from a corpus of sample domain texts, as well as parsing algorithms for the learned grammar, together with adjustable text summarization algorithms for generating domain specific summaries. Our practical experiments have shown that with support of domain knowledge the drawback of missing very large training data set can be effectively compensated. We have also shown that the knowledge based approach may be made more powerful by introducing grammar parsing and RST as inference engine. For checking the feasibility of model transfer, we introduced a technique for mapping a grammar from one domain to others with acceptable cost. We have also made a comprehensive comparison of our approach with some others.