 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerNav: A Highly Generalizable Memory-Execute-Review Framework for Zero-Shot Object Goal Navigation
Feb 05, 2026Visual Language Navigation (VLN) is one of the fundamental capabilities for embodied intelligence and a critical challenge that urgently needs to be addressed. However, existing methods are still unsatisfactory in terms of both success rate (SR) and generalization: Supervised Fine-Tuning (SFT) approaches typically achieve higher SR, while Training-Free (TF) approaches often generalize better, but it is difficult to obtain both simultaneously. To this end, we propose a Memory-Execute-Review framework. It consists of three parts: a hierarchical memory module for providing information support, an execute module for routine decision-making and actions, and a review module for handling abnormal situations and correcting behavior. We validated the effectiveness of this framework on the Object Goal Navigation task. Across 4 datasets, our average SR achieved absolute improvements of 7% and 5% compared to all baseline methods under TF and Zero-Shot (ZS) settings, respectively. On the most commonly used HM3D_v0.1 and the more challenging open vocabulary dataset HM3D_OVON, the SR improved by 8% and 6%, under ZS settings. Furthermore, on the MP3D and HM3D_OVON datasets, our method not only outperformed all TF methods but also surpassed all SFT methods, achieving comprehensive leadership in both SR (5% and 2%) and generalization.
Constraint-Aware Discrete-Time PID Gain Optimization for Robotic Joint Control Under Actuator Saturation
Jan 27, 2026The precise regulation of rotary actuation is fundamental in autonomous robotics, yet practical PID loops deviate from continuous-time theory due to discrete-time execution, actuator saturation, and small delays and measurement imperfections. We present an implementation-aware analysis and tuning workflow for saturated discrete-time joint control. We (i) derive PI stability regions under Euler and exact zero-order-hold (ZOH) discretizations using the Jury criterion, (ii) evaluate a discrete back-calculation anti-windup realization under saturation-dominant regimes, and (iii) propose a hybrid-certified Bayesian optimization workflow that screens analytically unstable candidates and behaviorally unsafe transients while optimizing a robust IAE objective with soft penalties on overshoot and saturation duty. Baseline sweeps ($τ=1.0$~s, $Δt=0.01$~s, $u\in[-10,10]$) quantify rise/settle trends for P/PI/PID. Under a randomized model family emulating uncertainty, delay, noise, quantization, and tighter saturation, robustness-oriented tuning improves median IAE from $0.843$ to $0.430$ while keeping median overshoot below $2\%$. In simulation-only tuning, the certification screen rejects $11.6\%$ of randomly sampled gains within bounds before full robust evaluation, improving sample efficiency without hardware experiments.
Adaptive Probability Flow Residual Minimization for High-Dimensional Fokker-Planck Equations
Dec 29, 2025Solving high-dimensional Fokker-Planck (FP) equations is a challenge in computational physics and stochastic dynamics, due to the curse of dimensionality (CoD) and the bottleneck of evaluating second-order diffusion terms. Existing deep learning approaches, such as Physics-Informed Neural Networks, face computational challenges as dimensionality increases, driven by the $O(d^2)$ complexity of automatic differentiation for second-order derivatives. While recent probability flow approaches bypass this by learning score functions or matching velocity fields, they often involve serial operations or depend on sampling efficiency in complex distributions. To address these issues, we propose the Adaptive Probability Flow Residual Minimization (A-PFRM) method. We reformulate the second-order FP equation into an equivalent first-order deterministic Probability Flow ODE (PF-ODE) constraint, which avoids explicit Hessian computation. Unlike score matching or velocity matching, A-PFRM solves this problem by minimizing the residual of the continuity equation induced by the PF-ODE. We leverage Continuous Normalizing Flows combined with the Hutchinson Trace Estimator to reduce the training complexity to linear scale $O(d)$, achieving an effective $O(1)$ wall-clock time on GPUs. To address data sparsity in high dimensions, we apply a generative adaptive sampling strategy and theoretically prove that dynamically aligning collocation points with the evolving probability mass is a necessary condition to bound the approximation error. Experiments on diverse benchmarks -- ranging from anisotropic Ornstein-Uhlenbeck (OU) processes and high-dimensional Brownian motions with time-varying diffusion terms, to Geometric OU processes featuring non-Gaussian solutions -- demonstrate that A-PFRM effectively mitigates the CoD, maintaining high accuracy and constant temporal cost for problems up to 100 dimensions.
AstraNav-World: World Model for Foresight Control and Consistency
Dec 25, 2025Embodied navigation in open, dynamic environments demands accurate foresight of how the world will evolve and how actions will unfold over time. We propose AstraNav-World, an end-to-end world model that jointly reasons about future visual states and action sequences within a unified probabilistic framework. Our framework integrates a diffusion-based video generator with a vision-language policy, enabling synchronized rollouts where predicted scenes and planned actions are updated simultaneously. Training optimizes two complementary objectives: generating action-conditioned multi-step visual predictions and deriving trajectories conditioned on those predicted visuals. This bidirectional constraint makes visual predictions executable and keeps decisions grounded in physically consistent, task-relevant futures, mitigating cumulative errors common in decoupled "envision-then-plan" pipelines. Experiments across diverse embodied navigation benchmarks show improved trajectory accuracy and higher success rates. Ablations confirm the necessity of tight vision-action coupling and unified training, with either branch removal degrading both prediction quality and policy reliability. In real-world testing, AstraNav-World demonstrated exceptional zero-shot capabilities, adapting to previously unseen scenarios without any real-world fine-tuning. These results suggest that AstraNav-World captures transferable spatial understanding and planning-relevant navigation dynamics, rather than merely overfitting to simulation-specific data distribution. Overall, by unifying foresight vision and control within a single generative model, we move closer to reliable, interpretable, and general-purpose embodied agents that operate robustly in open-ended real-world settings.
Self-Consistent Probability Flow for High-Dimensional Fokker-Planck Equations
Dec 22, 2025Solving high-dimensional Fokker-Planck (FP) equations is a challenge in computational physics and stochastic dynamics, due to the curse of dimensionality (CoD) and the bottleneck of evaluating second-order diffusion terms. Existing deep learning approaches, such as Physics-Informed Neural Networks (PINNs), face computational challenges as dimensionality increases, driven by the $O(D^2)$ complexity of automatic differentiation for second-order derivatives. While recent probability flow approaches bypass this by learning score functions or matching velocity fields, they often involve serial computational operations or depend on sampling efficiency in complex distributions. To address these issues, we propose the Self-Consistent Probability Flow (SCPF) method. We reformulate the second-order FP equation into an equivalent first-order deterministic Probability Flow ODE (PF-ODE) constraint. Unlike score matching or velocity matching, SCPF solves this problem by minimizing the residual of the PF-ODE continuity equation, which avoids explicit Hessian computation. We leverage Continuous Normalizing Flows (CNF) combined with the Hutchinson Trace Estimator (HTE) to reduce the training complexity to linear scale $O(D)$, achieving an effective $O(1)$ wall-clock time on GPUs. To address data sparsity in high dimensions, we apply a generative adaptive sampling strategy and theoretically prove that dynamically aligning collocation points with the evolving probability mass is a necessary condition to bound the approximation error. Experiments on diverse benchmarks -- ranging from anisotropic Ornstein-Uhlenbeck (OU) processes and high-dimensional Brownian motions with time-varying diffusion terms, to Geometric OU processes featuring non-Gaussian solutions -- demonstrate that SCPF effectively mitigates the CoD, maintaining high accuracy and constant computational cost for problems up to 100 dimensions.
JanusVLN: Decoupling Semantics and Spatiality with Dual Implicit Memory for Vision-Language Navigation
Sep 26, 2025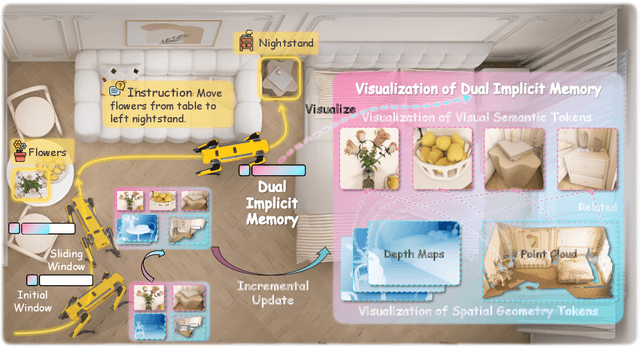
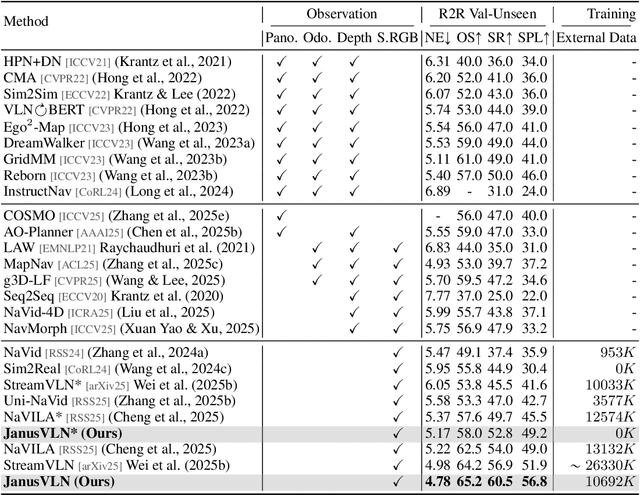
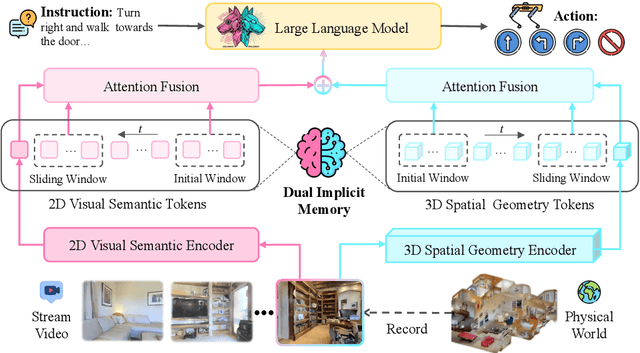
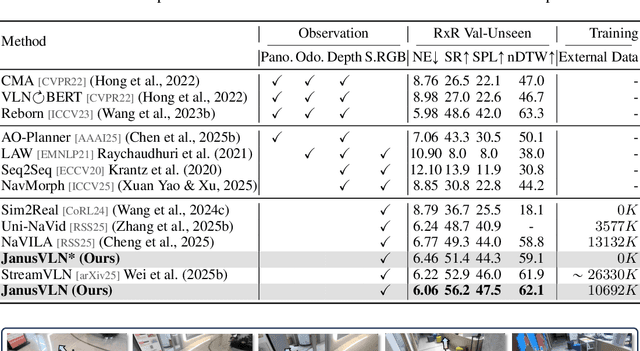
Vision-and-Language Navigation requires an embodied agent to navigate through unseen environments, guided by natural language instructions and a continuous video stream. Recent advances in VLN have been driven by the powerful semantic understanding of Multimodal Large Language Models. However, these methods typically rely on explicit semantic memory, such as building textual cognitive maps or storing historical visual frames. This type of method suffers from spatial information loss, computational redundancy, and memory bloat, which impede efficient navigation. Inspired by the implicit scene representation in human navigation, analogous to the left brain's semantic understanding and the right brain's spatial cognition, we propose JanusVLN, a novel VLN framework featuring a dual implicit neural memory that models spatial-geometric and visual-semantic memory as separate, compact, and fixed-size neural representations. This framework first extends the MLLM to incorporate 3D prior knowledge from the spatial-geometric encoder, thereby enhancing the spatial reasoning capabilities of models based solely on RGB input. Then, the historical key-value caches from the spatial-geometric and visual-semantic encoders are constructed into a dual implicit memory. By retaining only the KVs of tokens in the initial and sliding window, redundant computation is avoided, enabling efficient incremental updates. Extensive experiments demonstrate that JanusVLN outperforms over 20 recent methods to achieve SOTA performance. For example, the success rate improves by 10.5-35.5 compared to methods using multiple data types as input and by 3.6-10.8 compared to methods using more RGB training data. This indicates that the proposed dual implicit neural memory, as a novel paradigm, explores promising new directions for future VLN research. Ours project page: https://miv-xjtu.github.io/JanusVLN.github.io/.
NC-SDF: Enhancing Indoor Scene Reconstruction Using Neural SDFs with View-Dependent Normal Compensation
May 01, 2024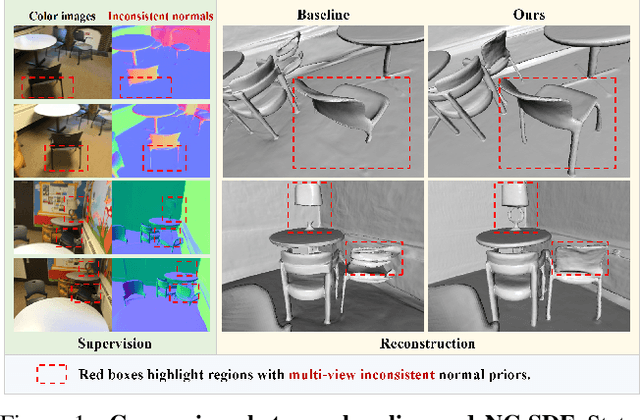



State-of-the-art neural implicit surface representations have achieved impressive results in indoor scene reconstruction by incorporating monocular geometric priors as additional supervision. However, we have observed that multi-view inconsistency between such priors poses a challenge for high-quality reconstructions. In response, we present NC-SDF, a neural signed distance field (SDF) 3D reconstruction framework with view-dependent normal compensation (NC). Specifically, we integrate view-dependent biases in monocular normal priors into the neural implicit representation of the scene. By adaptively learning and correcting the biases, our NC-SDF effectively mitigates the adverse impact of inconsistent supervision, enhancing both the global consistency and local details in the reconstructions. To further refine the details, we introduce an informative pixel sampling strategy to pay more attention to intricate geometry with higher information content. Additionally, we design a hybrid geometry modeling approach to improve the neural implicit representation. Experiments on synthetic and real-world datasets demonstrate that NC-SDF outperforms existing approaches in terms of reconstruction quality.
Wikiformer: Pre-training with Structured Information of Wikipedia for Ad-hoc Retrieval
Jan 01, 2024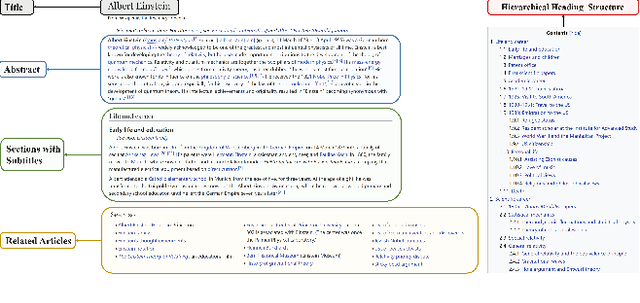
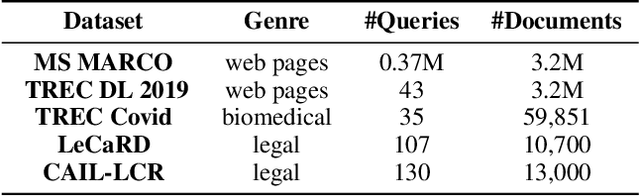
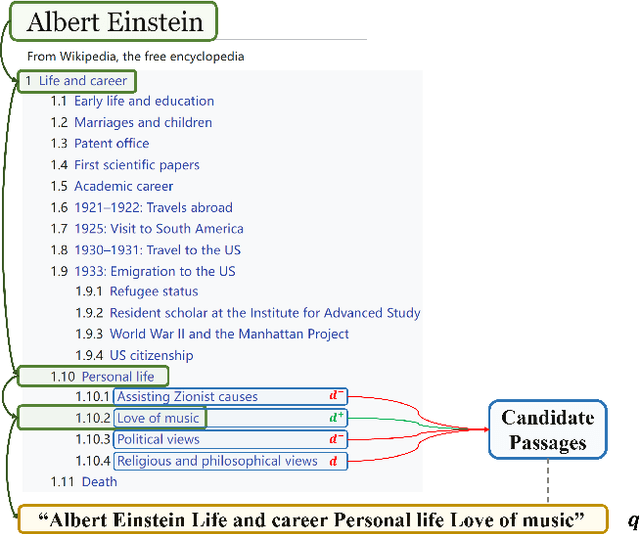
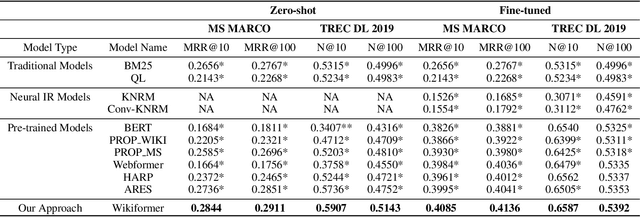
With the development of deep learning and natural language processing techniques, pre-trained language models have been widely used to solve information retrieval (IR) problems. Benefiting from the pre-training and fine-tuning paradigm, these models achieve state-of-the-art performance. In previous works, plain texts in Wikipedia have been widely used in the pre-training stage. However, the rich structured information in Wikipedia, such as the titles, abstracts, hierarchical heading (multi-level title) structure, relationship between articles, references, hyperlink structures, and the writing organizations, has not been fully explored. In this paper, we devise four pre-training objectives tailored for IR tasks based on the structured knowledge of Wikipedia. Compared to existing pre-training methods, our approach can better capture the semantic knowledge in the training corpus by leveraging the human-edited structured data from Wikipedia. Experimental results on multiple IR benchmark datasets show the superior performance of our model in both zero-shot and fine-tuning settings compared to existing strong retrieval baselines. Besides, experimental results in biomedical and legal domains demonstrate that our approach achieves better performance in vertical domains compared to previous models, especially in scenarios where long text similarity matching is needed.
SSP: Self-Supervised Post-training for Conversational Search
Jul 02, 2023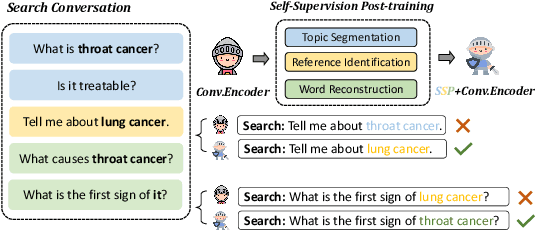



Conversational search has been regarded as the next-generation search paradigm. Constrained by data scarcity, most existing methods distill the well-trained ad-hoc retriever to the conversational retriever. However, these methods, which usually initialize parameters by query reformulation to discover contextualized dependency, have trouble in understanding the dialogue structure information and struggle with contextual semantic vanishing. In this paper, we propose \fullmodel (\model) which is a new post-training paradigm with three self-supervised tasks to efficiently initialize the conversational search model to enhance the dialogue structure and contextual semantic understanding. Furthermore, the \model can be plugged into most of the existing conversational models to boost their performance. To verify the effectiveness of our proposed method, we apply the conversational encoder post-trained by \model on the conversational search task using two benchmark datasets: CAsT-19 and CAsT-20. Extensive experiments that our \model can boost the performance of several existing conversational search methods. Our source code is available at \url{https://github.com/morecry/SSP}.
Building an Aerial-Ground Robotics System for Precision Farming
Nov 08, 2019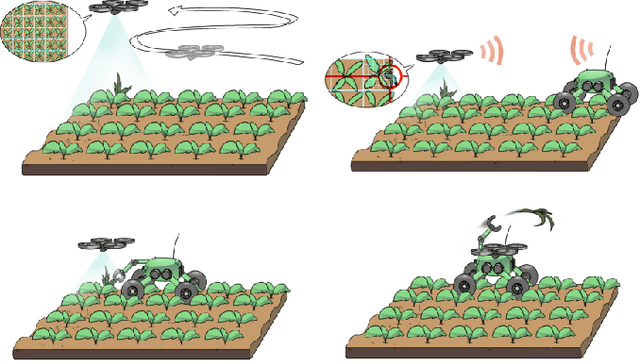

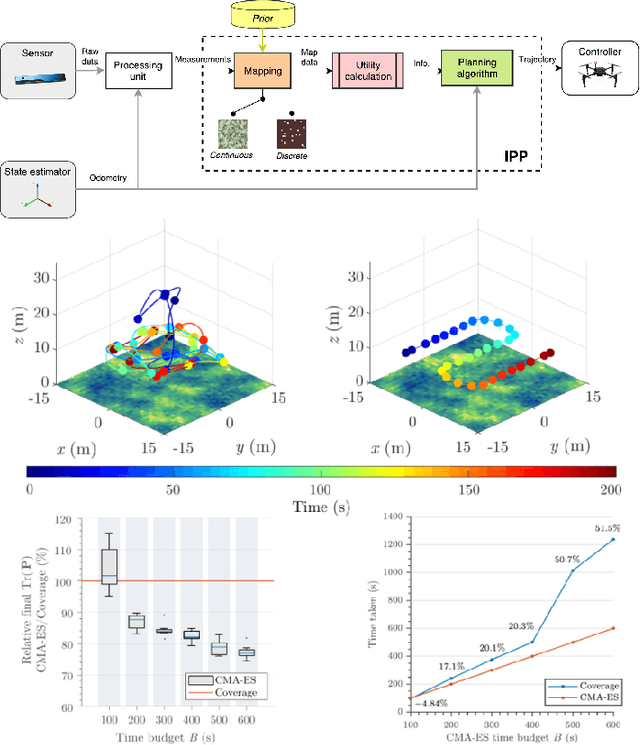
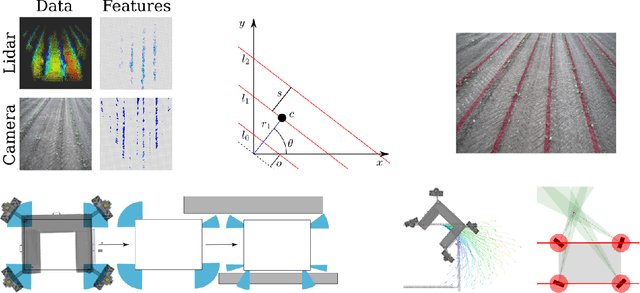
The application of autonomous robots in agriculture is gaining more and more popularity thanks to the high impact it may have on food security, sustainability, resource use efficiency, reduction of chemical treatments, minimization of the human effort and maximization of yield. The Flourish research project faced this challenge by developing an adaptable robotic solution for precision farming that combines the aerial survey capabilities of small autonomous unmanned aerial vehicles (UAVs) with flexible targeted intervention performed by multi-purpose agricultural unmanned ground vehicles (UGVs). This paper presents an exhaustive overview of the scientific and technological advances and outcomes obtained in the Flourish project. We introduce multi-spectral perception algorithms and aerial and ground based systems developed to monitor crop density, weed pressure, crop nitrogen nutrition status, and to accurately classify and locate weeds. We then introduce the navigation and mapping systems to deal with the specificity of the employed robots and of the agricultural environment, highlighting the collaborative modules that enable the UAVs and UGVs to collect and share information in a unified environment model. We finally present the ground intervention hardware, software solutions, and interfaces we implemented and tested in different field conditions and with different crops. We describe here a real use case in which a UAV collaborates with a UGV to monitor the field and to perform selective spraying treatments in a totally autonomous way.