 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigiForest: Digital Analytics and Robotics for Sustainable Forestry
Apr 16, 2026Covering one third of Earth's land surface, forests are vital to global biodiversity, climate regulation, and human well-being. In Europe, forests and woodlands reach approximately 40% of land area, and the forestry sector is central to achieving the EU's climate neutrality and biodiversity goals; these emphasize sustainable forest management, increased use of long-lived wood products, and resilient forest ecosystems. To meet these goals and properly address their inherent challenges, current practices require further innovation. This chapter introduces DigiForest, a novel, large-scale precision forestry approach leveraging digital technologies and autonomous robotics. DigiForest is structured around four main components: (1) autonomous, heterogeneous mobile robots (aerial, legged, and marsupial) for tree-level data collection; (2) automated extraction of tree traits to build forest inventories; (3) a Decision Support System (DSS) for forecasting forest growth and supporting decision-making; and (4) low-impact selective logging using purpose-built autonomous harvesters. These technologies have been extensively validated in real-world conditions in several locations, including forests in Finland, the UK, and Switzerland.
TreeLoc++: Robust 6-DoF LiDAR Localization in Forests with a Compact Digital Forest Inventory
Mar 04, 2026Reliable localization is essential for sustainable forest management, as it allows robots or sensor systems to revisit and monitor the status of individual trees over long periods. In modern forestry, this management is structured around Digital Forest Inventories (DFIs), which encode stems using compact geometric attributes rather than raw data. Despite their central role, DFIs have been overlooked in localization research, and most methods still rely on dense gigabyte-sized point clouds that are costly to store and maintain. To improve upon this, we propose TreeLoc++, a global localization framework that operates directly on DFIs as a discriminative representation, eliminating the need to use the raw point clouds. TreeLoc++ reduces false matches in structurally ambiguous forests and improves the reliability of full 6-DoF pose estimation. It augments coarse retrieval with a pairwise distance histogram that encodes local tree-layout context, subsequently refining candidates via DBH-based filtering and yaw-consistent inlier selection to further reduce mismatches. Furthermore, a constrained optimization leveraging tree geometry jointly estimates roll, pitch, and height, enhancing pose stability and enabling accurate localization without reliance on dense 3D point cloud data. Evaluations on 27 sequences recorded in forests across three datasets and four countries show that TreeLoc++ achieves precise localization with centimeter-level accuracy. We further demonstrate robustness to long-term change by localizing data recorded in 2025 against inventories built from 2023 data, spanning a two-year interval. The system represents 15 sessions spanning 7.98 km of trajectories using only 250KB of map data and outperforms both hand-crafted and learning-based baselines that rely on point cloud maps. This demonstrates the scalability of TreeLoc++ for long-term deployment.
Sapling-NeRF: Geo-Localised Sapling Reconstruction in Forests for Ecological Monitoring
Feb 26, 2026Saplings are key indicators of forest regeneration and overall forest health. However, their fine-scale architectural traits are difficult to capture with existing 3D sensing methods, which make quantitative evaluation difficult. Terrestrial Laser Scanners (TLS), Mobile Laser Scanners (MLS), or traditional photogrammetry approaches poorly reconstruct thin branches, dense foliage, and lack the scale consistency needed for long-term monitoring. Implicit 3D reconstruction methods such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) are promising alternatives, but cannot recover the true scale of a scene and lack any means to be accurately geo-localised. In this paper, we present a pipeline which fuses NeRF, LiDAR SLAM, and GNSS to enable repeatable, geo-localised ecological monitoring of saplings. Our system proposes a three-level representation: (i) coarse Earth-frame localisation using GNSS, (ii) LiDAR-based SLAM for centimetre-accurate localisation and reconstruction, and (iii) NeRF-derived object-centric dense reconstruction of individual saplings. This approach enables repeatable quantitative evaluation and long-term monitoring of sapling traits. Our experiments in forest plots in Wytham Woods (Oxford, UK) and Evo (Finland) show that stem height, branching patterns, and leaf-to-wood ratios can be captured with increased accuracy as compared to TLS. We demonstrate that accurate stem skeletons and leaf distributions can be measured for saplings with heights between 0.5m and 2m in situ, giving ecologists access to richer structural and quantitative data for analysing forest dynamics.
TreeLoc: 6-DoF LiDAR Global Localization in Forests via Inter-Tree Geometric Matching
Feb 03, 2026Reliable localization is crucial for navigation in forests, where GPS is often degraded and LiDAR measurements are repetitive, occluded, and structurally complex. These conditions weaken the assumptions of traditional urban-centric localization methods, which assume that consistent features arise from unique structural patterns, necessitating forest-centric solutions to achieve robustness in these environments. To address these challenges, we propose TreeLoc, a LiDAR-based global localization framework for forests that handles place recognition and 6-DoF pose estimation. We represent scenes using tree stems and their Diameter at Breast Height (DBH), which are aligned to a common reference frame via their axes and summarized using the tree distribution histogram (TDH) for coarse matching, followed by fine matching with a 2D triangle descriptor. Finally, pose estimation is achieved through a two-step geometric verification. On diverse forest benchmarks, TreeLoc outperforms baselines, achieving precise localization. Ablation studies validate the contribution of each component. We also propose applications for long-term forest management using descriptors from a compact global tree database. TreeLoc is open-sourced for the robotics community at https://github.com/minwoo0611/TreeLoc.
Markerless Aerial-Terrestrial Co-Registration of Forest Point Clouds using a Deformable Pose Graph
Oct 13, 2024
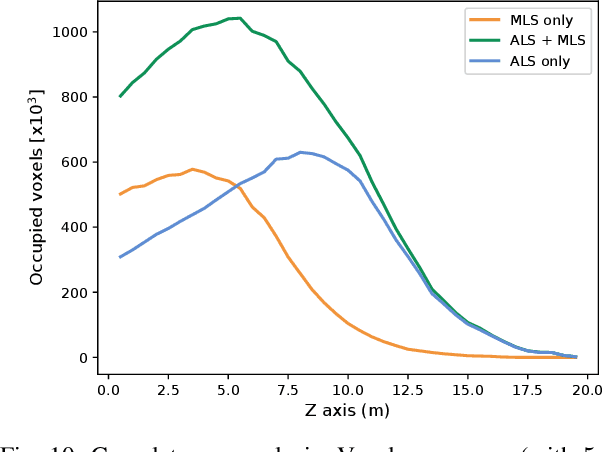
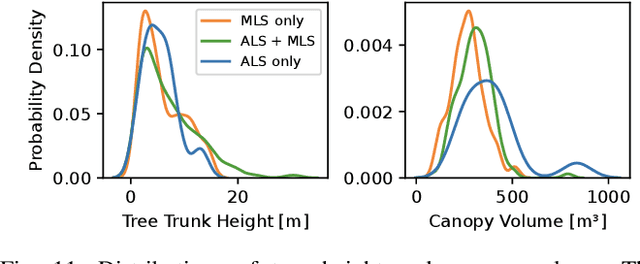

For biodiversity and forestry applications, end-users desire maps of forests that are fully detailed, from the forest floor to the canopy. Terrestrial laser scanning and aerial laser scanning are accurate and increasingly mature methods for scanning the forest. However, individually they are not able to estimate attributes such as tree height, trunk diameter and canopy density due to the inherent differences in their field-of-view and mapping processes. In this work, we present a pipeline that can automatically generate a single joint terrestrial and aerial forest reconstruction. The novelty of the approach is a marker-free registration pipeline, which estimates a set of relative transformation constraints between the aerial cloud and terrestrial sub-clouds without requiring any co-registration reflective markers to be physically placed in the scene. Our method then uses these constraints in a pose graph formulation, which enables us to finely align the respective clouds while respecting spatial constraints introduced by the terrestrial SLAM scanning process. We demonstrate that our approach can produce a fine-grained and complete reconstruction of large-scale natural environments, enabling multi-platform data capture for forestry applications without requiring external infrastructure.
Autonomous Forest Inventory with Legged Robots: System Design and Field Deployment
Apr 22, 2024We present a solution for autonomous forest inventory with a legged robotic platform. Compared to their wheeled and aerial counterparts, legged platforms offer an attractive balance of endurance and low soil impact for forest applications. In this paper, we present the complete system architecture of our forest inventory solution which includes state estimation, navigation, mission planning, and real-time tree segmentation and trait estimation. We present preliminary results for three campaigns in forests in Finland and the UK and summarize the main outcomes, lessons, and challenges. Our UK experiment at the Forest of Dean with the ANYmal D legged platform, achieved an autonomous survey of a 0.96 hectare plot in 20 min, identifying over 100 trees with typical DBH accuracy of 2 cm.
Wild Visual Navigation: Fast Traversability Learning via Pre-Trained Models and Online Self-Supervision
Apr 10, 2024Natural environments such as forests and grasslands are challenging for robotic navigation because of the false perception of rigid obstacles from high grass, twigs, or bushes. In this work, we present Wild Visual Navigation (WVN), an online self-supervised learning system for visual traversability estimation. The system is able to continuously adapt from a short human demonstration in the field, only using onboard sensing and computing. One of the key ideas to achieve this is the use of high-dimensional features from pre-trained self-supervised models, which implicitly encode semantic information that massively simplifies the learning task. Further, the development of an online scheme for supervision generator enables concurrent training and inference of the learned model in the wild. We demonstrate our approach through diverse real-world deployments in forests, parks, and grasslands. Our system is able to bootstrap the traversable terrain segmentation in less than 5 min of in-field training time, enabling the robot to navigate in complex, previously unseen outdoor terrains. Code: https://bit.ly/498b0CV - Project page:https://bit.ly/3M6nMHH
Online Tree Reconstruction and Forest Inventory on a Mobile Robotic System
Mar 26, 2024



Terrestrial laser scanning (TLS) is the standard technique used to create accurate point clouds for digital forest inventories. However, the measurement process is demanding, requiring up to two days per hectare for data collection, significant data storage, as well as resource-heavy post-processing of 3D data. In this work, we present a real-time mapping and analysis system that enables online generation of forest inventories using mobile laser scanners that can be mounted e.g. on mobile robots. Given incrementally created and locally accurate submaps-data payloads-our approach extracts tree candidates using a custom, Voronoi-inspired clustering algorithm. Tree candidates are reconstructed using an adapted Hough algorithm, which enables robust modeling of the tree stem. Further, we explicitly incorporate the incremental nature of the data collection by consistently updating the database using a pose graph LiDAR SLAM system. This enables us to refine our estimates of the tree traits if an area is revisited later during a mission. We demonstrate competitive accuracy to TLS or manual measurements using laser scanners that we mounted on backpacks or mobile robots operating in conifer, broad-leaf and mixed forests. Our results achieve RMSE of 1.93 cm, a bias of 0.65 cm and a standard deviation of 1.81 cm (averaged across these sequences)-with no post-processing required after the mission is complete.
Evaluation and Deployment of LiDAR-based Place Recognition in Dense Forests
Mar 21, 2024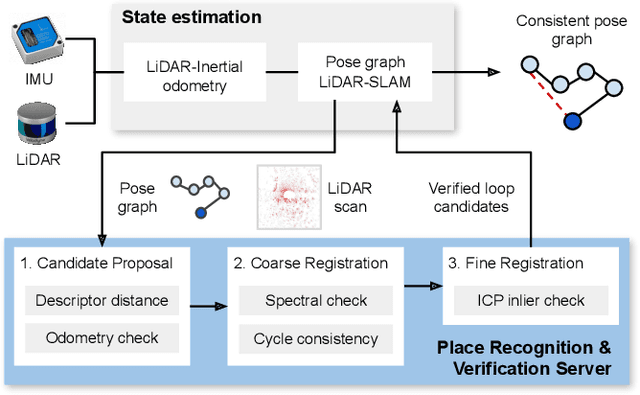
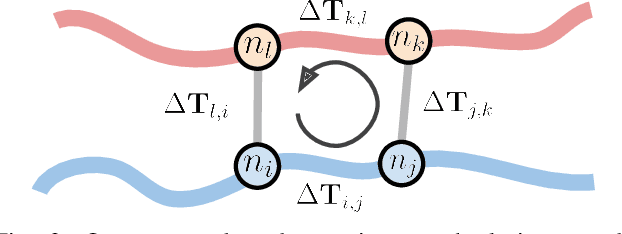
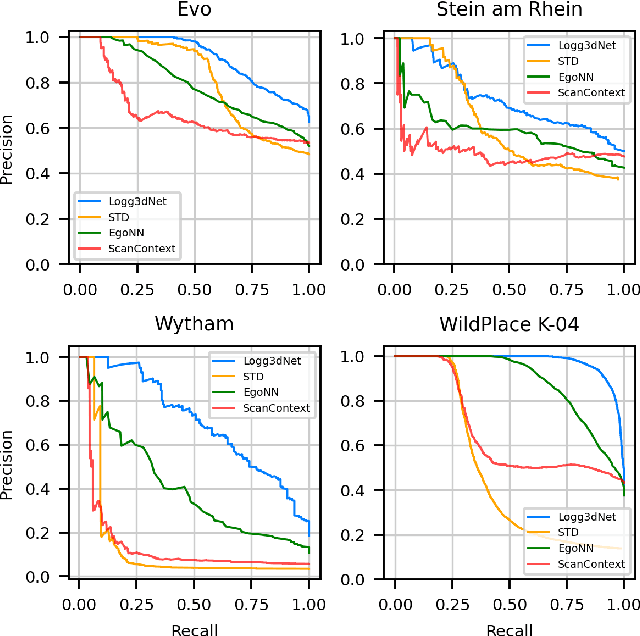
Many LiDAR place recognition systems have been developed and tested specifically for urban driving scenarios. Their performance in natural environments such as forests and woodlands have been studied less closely. In this paper, we analyzed the capabilities of four different LiDAR place recognition systems, both handcrafted and learning-based methods, using LiDAR data collected with a handheld device and legged robot within dense forest environments. In particular, we focused on evaluating localization where there is significant translational and orientation difference between corresponding LiDAR scan pairs. This is particularly important for forest survey systems where the sensor or robot does not follow a defined road or path. Extending our analysis we then incorporated the best performing approach, Logg3dNet, into a full 6-DoF pose estimation system -- introducing several verification layers for precise registration. We demonstrated the performance of our methods in three operational modes: online SLAM, offline multi-mission SLAM map merging, and relocalization into a prior map. We evaluated these modes using data captured in forests from three different countries, achieving 80% of correct loop closures candidates with baseline distances up to 5m, and 60% up to 10m.
SiLVR: Scalable Lidar-Visual Reconstruction with Neural Radiance Fields for Robotic Inspection
Mar 11, 2024
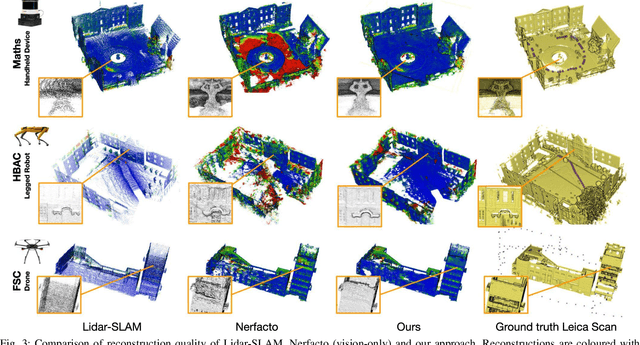


We present a neural-field-based large-scale reconstruction system that fuses lidar and vision data to generate high-quality reconstructions that are geometrically accurate and capture photo-realistic textures. This system adapts the state-of-the-art neural radiance field (NeRF) representation to also incorporate lidar data which adds strong geometric constraints on the depth and surface normals. We exploit the trajectory from a real-time lidar SLAM system to bootstrap a Structure-from-Motion (SfM) procedure to both significantly reduce the computation time and to provide metric scale which is crucial for lidar depth loss. We use submapping to scale the system to large-scale environments captured over long trajectories. We demonstrate the reconstruction system with data from a multi-camera, lidar sensor suite onboard a legged robot, hand-held while scanning building scenes for 600 metres, and onboard an aerial robot surveying a multi-storey mock disaster site-building. Website: https://ori-drs.github.io/projects/silvr/