 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigiForest: Digital Analytics and Robotics for Sustainable Forestry
Apr 16, 2026Covering one third of Earth's land surface, forests are vital to global biodiversity, climate regulation, and human well-being. In Europe, forests and woodlands reach approximately 40% of land area, and the forestry sector is central to achieving the EU's climate neutrality and biodiversity goals; these emphasize sustainable forest management, increased use of long-lived wood products, and resilient forest ecosystems. To meet these goals and properly address their inherent challenges, current practices require further innovation. This chapter introduces DigiForest, a novel, large-scale precision forestry approach leveraging digital technologies and autonomous robotics. DigiForest is structured around four main components: (1) autonomous, heterogeneous mobile robots (aerial, legged, and marsupial) for tree-level data collection; (2) automated extraction of tree traits to build forest inventories; (3) a Decision Support System (DSS) for forecasting forest growth and supporting decision-making; and (4) low-impact selective logging using purpose-built autonomous harvesters. These technologies have been extensively validated in real-world conditions in several locations, including forests in Finland, the UK, and Switzerland.
ROOM: A Physics-Based Continuum Robot Simulator for Photorealistic Medical Datasets Generation
Sep 16, 2025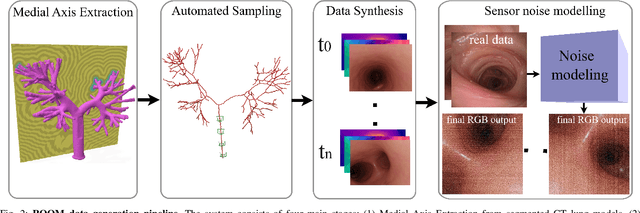



Continuum robots are advancing bronchoscopy procedures by accessing complex lung airways and enabling targeted interventions. However, their development is limited by the lack of realistic training and test environments: Real data is difficult to collect due to ethical constraints and patient safety concerns, and developing autonomy algorithms requires realistic imaging and physical feedback. We present ROOM (Realistic Optical Observation in Medicine), a comprehensive simulation framework designed for generating photorealistic bronchoscopy training data. By leveraging patient CT scans, our pipeline renders multi-modal sensor data including RGB images with realistic noise and light specularities, metric depth maps, surface normals, optical flow and point clouds at medically relevant scales. We validate the data generated by ROOM in two canonical tasks for medical robotics -- multi-view pose estimation and monocular depth estimation, demonstrating diverse challenges that state-of-the-art methods must overcome to transfer to these medical settings. Furthermore, we show that the data produced by ROOM can be used to fine-tune existing depth estimation models to overcome these challenges, also enabling other downstream applications such as navigation. We expect that ROOM will enable large-scale data generation across diverse patient anatomies and procedural scenarios that are challenging to capture in clinical settings. Code and data: https://github.com/iamsalvatore/room.
OpenLex3D: A New Evaluation Benchmark for Open-Vocabulary 3D Scene Representations
Mar 25, 2025



3D scene understanding has been transformed by open-vocabulary language models that enable interaction via natural language. However, the evaluation of these representations is limited to closed-set semantics that do not capture the richness of language. This work presents OpenLex3D, a dedicated benchmark to evaluate 3D open-vocabulary scene representations. OpenLex3D provides entirely new label annotations for 23 scenes from Replica, ScanNet++, and HM3D, which capture real-world linguistic variability by introducing synonymical object categories and additional nuanced descriptions. By introducing an open-set 3D semantic segmentation task and an object retrieval task, we provide insights on feature precision, segmentation, and downstream capabilities. We evaluate various existing 3D open-vocabulary methods on OpenLex3D, showcasing failure cases, and avenues for improvement. The benchmark is publicly available at: https://openlex3d.github.io/.
The Bare Necessities: Designing Simple, Effective Open-Vocabulary Scene Graphs
Dec 02, 20243D open-vocabulary scene graph methods are a promising map representation for embodied agents, however many current approaches are computationally expensive. In this paper, we reexamine the critical design choices established in previous works to optimize both efficiency and performance. We propose a general scene graph framework and conduct three studies that focus on image pre-processing, feature fusion, and feature selection. Our findings reveal that commonly used image pre-processing techniques provide minimal performance improvement while tripling computation (on a per object view basis). We also show that averaging feature labels across different views significantly degrades performance. We study alternative feature selection strategies that enhance performance without adding unnecessary computational costs. Based on our findings, we introduce a computationally balanced approach for 3D point cloud segmentation with per-object features. The approach matches state-of-the-art classification accuracy while achieving a threefold reduction in computation.
Autonomous Forest Inventory with Legged Robots: System Design and Field Deployment
Apr 22, 2024We present a solution for autonomous forest inventory with a legged robotic platform. Compared to their wheeled and aerial counterparts, legged platforms offer an attractive balance of endurance and low soil impact for forest applications. In this paper, we present the complete system architecture of our forest inventory solution which includes state estimation, navigation, mission planning, and real-time tree segmentation and trait estimation. We present preliminary results for three campaigns in forests in Finland and the UK and summarize the main outcomes, lessons, and challenges. Our UK experiment at the Forest of Dean with the ANYmal D legged platform, achieved an autonomous survey of a 0.96 hectare plot in 20 min, identifying over 100 trees with typical DBH accuracy of 2 cm.
Wild Visual Navigation: Fast Traversability Learning via Pre-Trained Models and Online Self-Supervision
Apr 10, 2024Natural environments such as forests and grasslands are challenging for robotic navigation because of the false perception of rigid obstacles from high grass, twigs, or bushes. In this work, we present Wild Visual Navigation (WVN), an online self-supervised learning system for visual traversability estimation. The system is able to continuously adapt from a short human demonstration in the field, only using onboard sensing and computing. One of the key ideas to achieve this is the use of high-dimensional features from pre-trained self-supervised models, which implicitly encode semantic information that massively simplifies the learning task. Further, the development of an online scheme for supervision generator enables concurrent training and inference of the learned model in the wild. We demonstrate our approach through diverse real-world deployments in forests, parks, and grasslands. Our system is able to bootstrap the traversable terrain segmentation in less than 5 min of in-field training time, enabling the robot to navigate in complex, previously unseen outdoor terrains. Code: https://bit.ly/498b0CV - Project page:https://bit.ly/3M6nMHH
An Efficient Locally Reactive Controller for Safe Navigation in Visual Teach and Repeat Missions
Jan 11, 2022


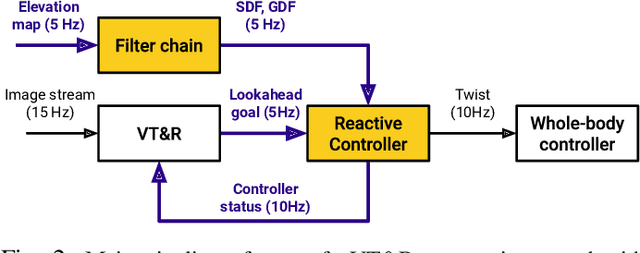
To achieve successful field autonomy, mobile robots need to freely adapt to changes in their environment. Visual navigation systems such as Visual Teach and Repeat (VT&R) often assume the space around the reference trajectory is free, but if the environment is obstructed path tracking can fail or the robot could collide with a previously unseen obstacle. In this work, we present a locally reactive controller for a VT&R system that allows a robot to navigate safely despite physical changes to the environment. Our controller uses a local elevation map to compute vector representations and outputs twist commands for navigation at 10 Hz. They are combined in a Riemannian Motion Policies (RMP) controller that requires <2 ms to run on a CPU. We integrated our controller with a VT&R system onboard an ANYmal C robot and tested it in indoor cluttered spaces and a large-scale underground mine. We demonstrate that our locally reactive controller keeps the robot safe when physical occlusions or loss of visual tracking occur such as when walking close to walls, crossing doorways, or traversing narrow corridors. Video: https://youtu.be/G_AwNec5AwU
Learning Camera Performance Models for Active Multi-Camera Visual Teach and Repeat
Mar 25, 2021
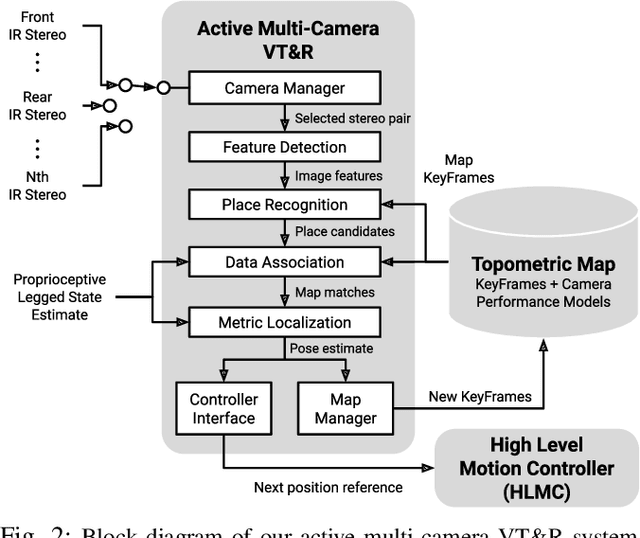
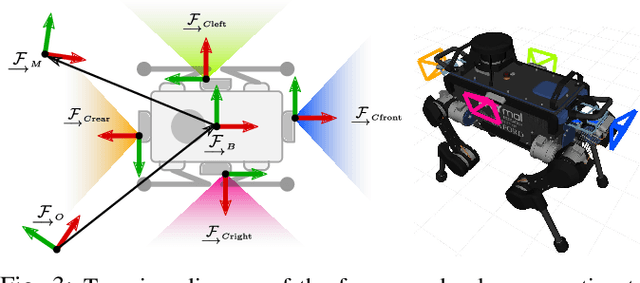
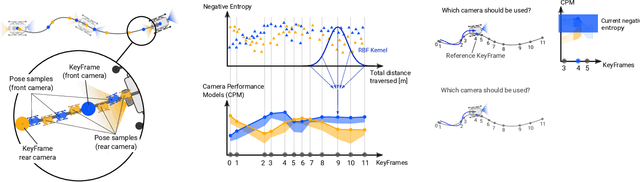
In dynamic and cramped industrial environments, achieving reliable Visual Teach and Repeat (VT&R) with a single-camera is challenging. In this work, we develop a robust method for non-synchronized multi-camera VT&R. Our contribution are expected Camera Performance Models (CPM) which evaluate the camera streams from the teach step to determine the most informative one for localization during the repeat step. By actively selecting the most suitable camera for localization, we are able to successfully complete missions when one of the cameras is occluded, faces into feature poor locations or if the environment has changed. Furthermore, we explore the specific challenges of achieving VT&R on a dynamic quadruped robot, ANYmal. The camera does not follow a linear path (due to the walking gait and holonomicity) such that precise path-following cannot be achieved. Our experiments feature forward and backward facing stereo cameras showing VT&R performance in cluttered indoor and outdoor scenarios. We compared the trajectories the robot executed during the repeat steps demonstrating typical tracking precision of less than 10cm on average. With a view towards omni-directional localization, we show how the approach generalizes to four cameras in simulation. Video: https://youtu.be/iAY0lyjAnqY
Visual SLAM-based Localization and Navigation for Service Robots: The Pepper Case
Nov 20, 2018
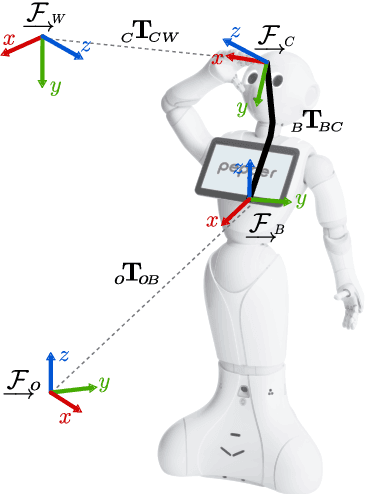
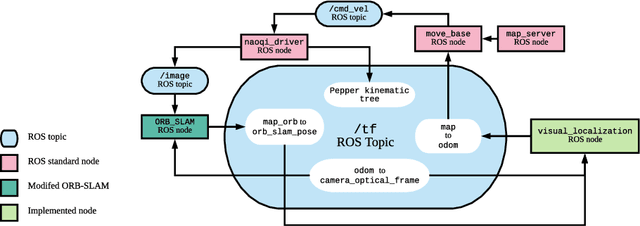

We propose a Visual-SLAM based localization and navigation system for service robots. Our system is built on top of the ORB-SLAM monocular system but extended by the inclusion of wheel odometry in the estimation procedures. As a case study, the proposed system is validated using the Pepper robot, whose short-range LIDARs and RGB-D camera do not allow the robot to self-localize in large environments. The localization system is tested in navigation tasks using Pepper in two different environments: a medium-size laboratory, and a large-size hall.
The NAO Backpack: An Open-hardware Add-on for Fast Software Development with the NAO Robot
Jun 20, 2017



We present an open-source accessory for the NAO robot, which enables to test computationally demanding algorithms in an external platform while preserving robot's autonomy and mobility. The platform has the form of a backpack, which can be 3D printed and replicated, and holds an ODROID XU4 board to process algorithms externally with ROS compatibility. We provide also a software bridge between the B-Human's framework and ROS to have access to the robot's sensors close to real-time. We tested the platform in several robotics applications such as data logging, visual SLAM, and robot vision with deep learning techniques. The CAD model, hardware specifications and software are available online for the benefit of the community: https://github.com/uchile-robotics/nao-backpack