 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulated 3D Scene Graphs for Open-World Mobile Manipulation
Feb 18, 2026Semantics has enabled 3D scene understanding and affordance-driven object interaction. However, robots operating in real-world environments face a critical limitation: they cannot anticipate how objects move. Long-horizon mobile manipulation requires closing the gap between semantics, geometry, and kinematics. In this work, we present MoMa-SG, a novel framework for building semantic-kinematic 3D scene graphs of articulated scenes containing a myriad of interactable objects. Given RGB-D sequences containing multiple object articulations, we temporally segment object interactions and infer object motion using occlusion-robust point tracking. We then lift point trajectories into 3D and estimate articulation models using a novel unified twist estimation formulation that robustly estimates revolute and prismatic joint parameters in a single optimization pass. Next, we associate objects with estimated articulations and detect contained objects by reasoning over parent-child relations at identified opening states. We also introduce the novel Arti4D-Semantic dataset, which uniquely combines hierarchical object semantics including parent-child relation labels with object axis annotations across 62 in-the-wild RGB-D sequences containing 600 object interactions and three distinct observation paradigms. We extensively evaluate the performance of MoMa-SG on two datasets and ablate key design choices of our approach. In addition, real-world experiments on both a quadruped and a mobile manipulator demonstrate that our semantic-kinematic scene graphs enable robust manipulation of articulated objects in everyday home environments. We provide code and data at: https://momasg.cs.uni-freiburg.de.
Visual Loop Closure Detection Through Deep Graph Consensus
May 27, 2025Visual loop closure detection traditionally relies on place recognition methods to retrieve candidate loops that are validated using computationally expensive RANSAC-based geometric verification. As false positive loop closures significantly degrade downstream pose graph estimates, verifying a large number of candidates in online simultaneous localization and mapping scenarios is constrained by limited time and compute resources. While most deep loop closure detection approaches only operate on pairs of keyframes, we relax this constraint by considering neighborhoods of multiple keyframes when detecting loops. In this work, we introduce LoopGNN, a graph neural network architecture that estimates loop closure consensus by leveraging cliques of visually similar keyframes retrieved through place recognition. By propagating deep feature encodings among nodes of the clique, our method yields high-precision estimates while maintaining high recall. Extensive experimental evaluations on the TartanDrive 2.0 and NCLT datasets demonstrate that LoopGNN outperforms traditional baselines. Additionally, an ablation study across various keypoint extractors demonstrates that our method is robust, regardless of the type of deep feature encodings used, and exhibits higher computational efficiency compared to classical geometric verification baselines. We release our code, supplementary material, and keyframe data at https://loopgnn.cs.uni-freiburg.de.
MORE: Mobile Manipulation Rearrangement Through Grounded Language Reasoning
May 05, 2025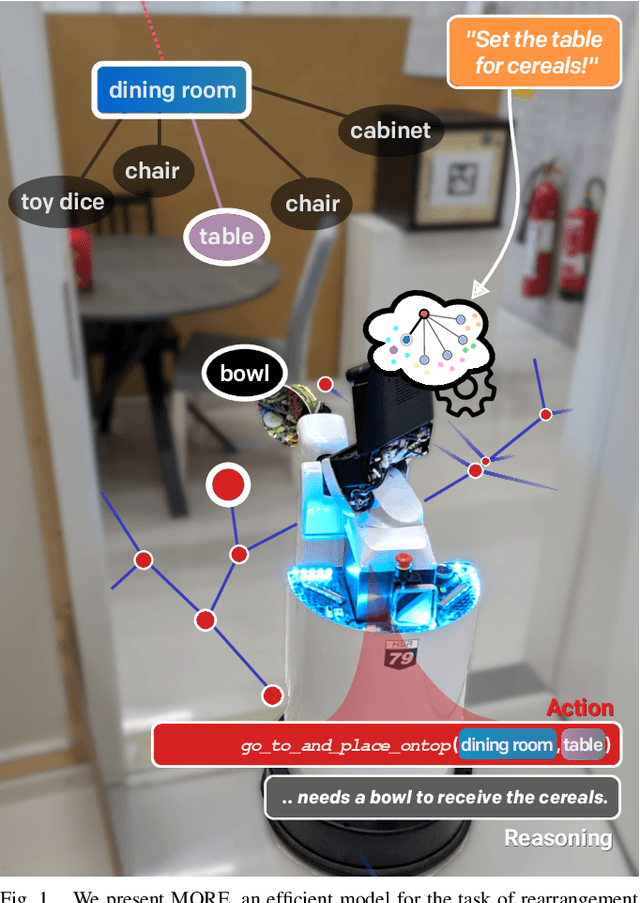
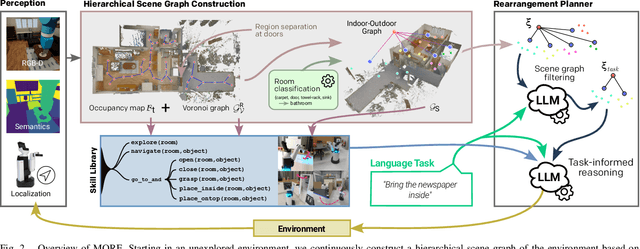
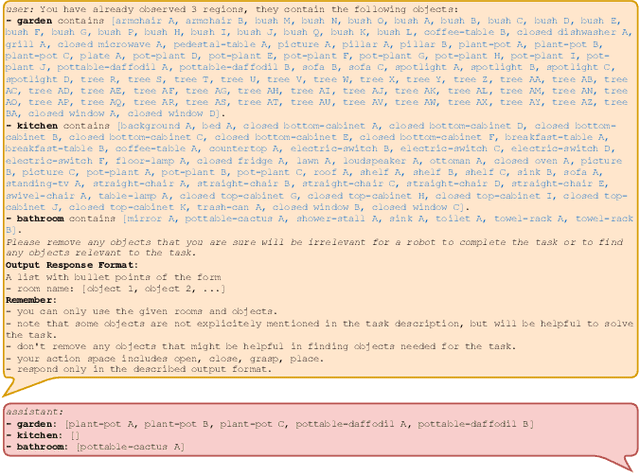
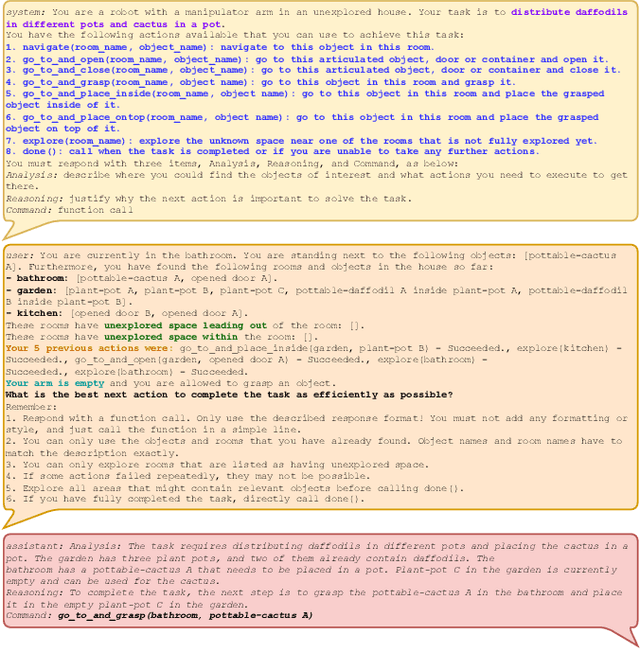
Autonomous long-horizon mobile manipulation encompasses a multitude of challenges, including scene dynamics, unexplored areas, and error recovery. Recent works have leveraged foundation models for scene-level robotic reasoning and planning. However, the performance of these methods degrades when dealing with a large number of objects and large-scale environments. To address these limitations, we propose MORE, a novel approach for enhancing the capabilities of language models to solve zero-shot mobile manipulation planning for rearrangement tasks. MORE leverages scene graphs to represent environments, incorporates instance differentiation, and introduces an active filtering scheme that extracts task-relevant subgraphs of object and region instances. These steps yield a bounded planning problem, effectively mitigating hallucinations and improving reliability. Additionally, we introduce several enhancements that enable planning across both indoor and outdoor environments. We evaluate MORE on 81 diverse rearrangement tasks from the BEHAVIOR-1K benchmark, where it becomes the first approach to successfully solve a significant share of the benchmark, outperforming recent foundation model-based approaches. Furthermore, we demonstrate the capabilities of our approach in several complex real-world tasks, mimicking everyday activities. We make the code publicly available at https://more-model.cs.uni-freiburg.de.
OpenLex3D: A New Evaluation Benchmark for Open-Vocabulary 3D Scene Representations
Mar 25, 2025



3D scene understanding has been transformed by open-vocabulary language models that enable interaction via natural language. However, the evaluation of these representations is limited to closed-set semantics that do not capture the richness of language. This work presents OpenLex3D, a dedicated benchmark to evaluate 3D open-vocabulary scene representations. OpenLex3D provides entirely new label annotations for 23 scenes from Replica, ScanNet++, and HM3D, which capture real-world linguistic variability by introducing synonymical object categories and additional nuanced descriptions. By introducing an open-set 3D semantic segmentation task and an object retrieval task, we provide insights on feature precision, segmentation, and downstream capabilities. We evaluate various existing 3D open-vocabulary methods on OpenLex3D, showcasing failure cases, and avenues for improvement. The benchmark is publicly available at: https://openlex3d.github.io/.
The Bare Necessities: Designing Simple, Effective Open-Vocabulary Scene Graphs
Dec 02, 20243D open-vocabulary scene graph methods are a promising map representation for embodied agents, however many current approaches are computationally expensive. In this paper, we reexamine the critical design choices established in previous works to optimize both efficiency and performance. We propose a general scene graph framework and conduct three studies that focus on image pre-processing, feature fusion, and feature selection. Our findings reveal that commonly used image pre-processing techniques provide minimal performance improvement while tripling computation (on a per object view basis). We also show that averaging feature labels across different views significantly degrades performance. We study alternative feature selection strategies that enhance performance without adding unnecessary computational costs. Based on our findings, we introduce a computationally balanced approach for 3D point cloud segmentation with per-object features. The approach matches state-of-the-art classification accuracy while achieving a threefold reduction in computation.
Learning Lane Graphs from Aerial Imagery Using Transformers
Jul 08, 2024



The robust and safe operation of automated vehicles underscores the critical need for detailed and accurate topological maps. At the heart of this requirement is the construction of lane graphs, which provide essential information on lane connectivity, vital for navigating complex urban environments autonomously. While transformer-based models have been effective in creating map topologies from vehicle-mounted sensor data, their potential for generating such graphs from aerial imagery remains untapped. This work introduces a novel approach to generating successor lane graphs from aerial imagery, utilizing the advanced capabilities of transformer models. We frame successor lane graphs as a collection of maximal length paths and predict them using a Detection Transformer (DETR) architecture. We demonstrate the efficacy of our method through extensive experiments on the diverse and large-scale UrbanLaneGraph dataset, illustrating its accuracy in generating successor lane graphs and highlighting its potential for enhancing autonomous vehicle navigation in complex environments.
Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation
Mar 26, 2024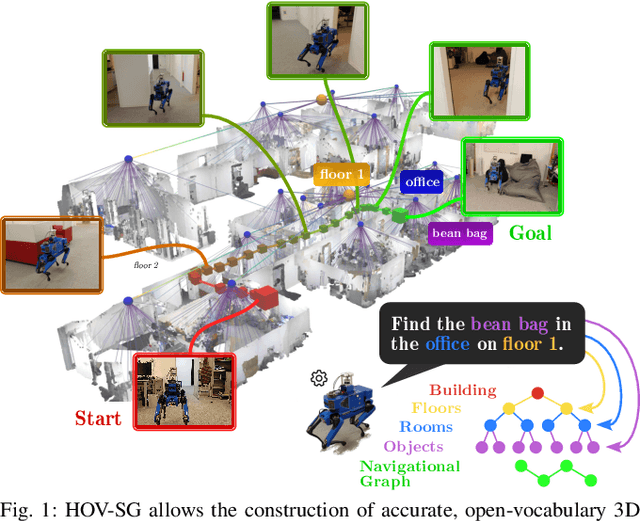



Recent open-vocabulary robot mapping methods enrich dense geometric maps with pre-trained visual-language features. While these maps allow for the prediction of point-wise saliency maps when queried for a certain language concept, large-scale environments and abstract queries beyond the object level still pose a considerable hurdle, ultimately limiting language-grounded robotic navigation. In this work, we present HOV-SG, a hierarchical open-vocabulary 3D scene graph mapping approach for language-grounded robot navigation. Leveraging open-vocabulary vision foundation models, we first obtain state-of-the-art open-vocabulary segment-level maps in 3D and subsequently construct a 3D scene graph hierarchy consisting of floor, room, and object concepts, each enriched with open-vocabulary features. Our approach is able to represent multi-story buildings and allows robotic traversal of those using a cross-floor Voronoi graph. HOV-SG is evaluated on three distinct datasets and surpasses previous baselines in open-vocabulary semantic accuracy on the object, room, and floor level while producing a 75% reduction in representation size compared to dense open-vocabulary maps. In order to prove the efficacy and generalization capabilities of HOV-SG, we showcase successful long-horizon language-conditioned robot navigation within real-world multi-storage environments. We provide code and trial video data at http://hovsg.github.io/.
Language-Grounded Dynamic Scene Graphs for Interactive Object Search with Mobile Manipulation
Mar 14, 2024



To fully leverage the capabilities of mobile manipulation robots, it is imperative that they are able to autonomously execute long-horizon tasks in large unexplored environments. While large language models (LLMs) have shown emergent reasoning skills on arbitrary tasks, existing work primarily concentrates on explored environments, typically focusing on either navigation or manipulation tasks in isolation. In this work, we propose MoMa-LLM, a novel approach that grounds language models within structured representations derived from open-vocabulary scene graphs, dynamically updated as the environment is explored. We tightly interleave these representations with an object-centric action space. The resulting approach is zero-shot, open-vocabulary, and readily extendable to a spectrum of mobile manipulation and household robotic tasks. We demonstrate the effectiveness of MoMa-LLM in a novel semantic interactive search task in large realistic indoor environments. In extensive experiments in both simulation and the real world, we show substantially improved search efficiency compared to conventional baselines and state-of-the-art approaches, as well as its applicability to more abstract tasks. We make the code publicly available at http://moma-llm.cs.uni-freiburg.de.
Compositional Servoing by Recombining Demonstrations
Oct 06, 2023Learning-based manipulation policies from image inputs often show weak task transfer capabilities. In contrast, visual servoing methods allow efficient task transfer in high-precision scenarios while requiring only a few demonstrations. In this work, we present a framework that formulates the visual servoing task as graph traversal. Our method not only extends the robustness of visual servoing, but also enables multitask capability based on a few task-specific demonstrations. We construct demonstration graphs by splitting existing demonstrations and recombining them. In order to traverse the demonstration graph in the inference case, we utilize a similarity function that helps select the best demonstration for a specific task. This enables us to compute the shortest path through the graph. Ultimately, we show that recombining demonstrations leads to higher task-respective success. We present extensive simulation and real-world experimental results that demonstrate the efficacy of our approach.
Collaborative Dynamic 3D Scene Graphs for Automated Driving
Sep 19, 2023



Maps have played an indispensable role in enabling safe and automated driving. Although there have been many advances on different fronts ranging from SLAM to semantics, building an actionable hierarchical semantic representation of urban dynamic scenes from multiple agents is still a challenging problem. In this work, we present Collaborative URBan Scene Graphs (CURB-SG) that enable higher-order reasoning and efficient querying for many functions of automated driving. CURB-SG leverages panoptic LiDAR data from multiple agents to build large-scale maps using an effective graph-based collaborative SLAM approach that detects inter-agent loop closures. To semantically decompose the obtained 3D map, we build a lane graph from the paths of ego agents and their panoptic observations of other vehicles. Based on the connectivity of the lane graph, we segregate the environment into intersecting and non-intersecting road areas. Subsequently, we construct a multi-layered scene graph that includes lane information, the position of static landmarks and their assignment to certain map sections, other vehicles observed by the ego agents, and the pose graph from SLAM including 3D panoptic point clouds. We extensively evaluate CURB-SG in urban scenarios using a photorealistic simulator. We release our code at http://curb.cs.uni-freiburg.de.