 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Real-World Autonomous Racing via Attenuated Residual Policy Optimization
Mar 13, 2026Residual policy learning (RPL), in which a learned policy refines a static base policy using deep reinforcement learning (DRL), has shown strong performance across various robotic applications. Its effectiveness is particularly evident in autonomous racing, a domain that serves as a challenging benchmark for real-world DRL. However, deploying RPL-based controllers introduces system complexity and increases inference latency. We address this by introducing an extension of RPL named attenuated residual policy optimization ($α$-RPO). Unlike standard RPL, $α$-RPO yields a standalone neural policy by progressively attenuating the base policy, which initially serves to bootstrap learning. Furthermore, this mechanism enables a form of privileged learning, where the base policy is permitted to use sensor modalities not required for final deployment. We design $α$-RPO to integrate seamlessly with PPO, ensuring that the attenuated influence of the base controller is dynamically compensated during policy optimization. We evaluate $α$-RPO by building a framework for 1:10-scaled autonomous racing around it. In both simulation and zero-shot real-world transfer to Roboracer cars, $α$-RPO not only reduces system complexity but also improves driving performance compared to baselines - demonstrating its practicality for robotic deployment. Our code is available at: https://github.com/raphajaner/arpo_racing.
Continuous World Coverage Path Planning for Fixed-Wing UAVs using Deep Reinforcement Learning
May 13, 2025Unmanned Aerial Vehicle (UAV) Coverage Path Planning (CPP) is critical for applications such as precision agriculture and search and rescue. While traditional methods rely on discrete grid-based representations, real-world UAV operations require power-efficient continuous motion planning. We formulate the UAV CPP problem in a continuous environment, minimizing power consumption while ensuring complete coverage. Our approach models the environment with variable-size axis-aligned rectangles and UAV motion with curvature-constrained B\'ezier curves. We train a reinforcement learning agent using an action-mapping-based Soft Actor-Critic (AM-SAC) algorithm employing a self-adaptive curriculum. Experiments on both procedurally generated and hand-crafted scenarios demonstrate the effectiveness of our method in learning energy-efficient coverage strategies.
Impoola: The Power of Average Pooling for Image-Based Deep Reinforcement Learning
Mar 07, 2025



As image-based deep reinforcement learning tackles more challenging tasks, increasing model size has become an important factor in improving performance. Recent studies achieved this by focusing on the parameter efficiency of scaled networks, typically using Impala-CNN, a 15-layer ResNet-inspired network, as the image encoder. However, while Impala-CNN evidently outperforms older CNN architectures, potential advancements in network design for deep reinforcement learning-specific image encoders remain largely unexplored. We find that replacing the flattening of output feature maps in Impala-CNN with global average pooling leads to a notable performance improvement. This approach outperforms larger and more complex models in the Procgen Benchmark, particularly in terms of generalization. We call our proposed encoder model Impoola-CNN. A decrease in the network's translation sensitivity may be central to this improvement, as we observe the most significant gains in games without agent-centered observations. Our results demonstrate that network scaling is not just about increasing model size - efficient network design is also an essential factor.
Physics-model-guided Worst-case Sampling for Safe Reinforcement Learning
Dec 17, 2024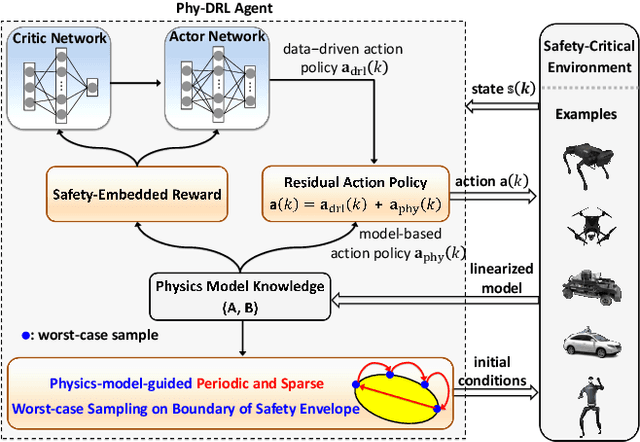

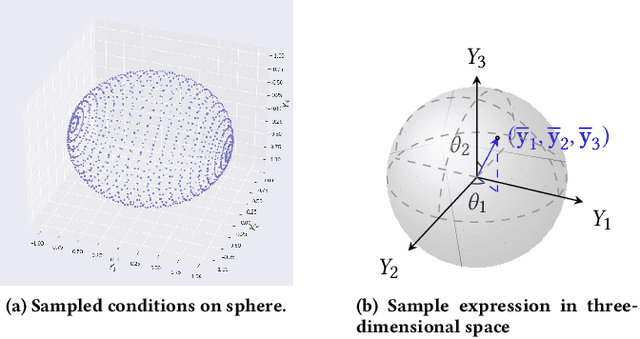
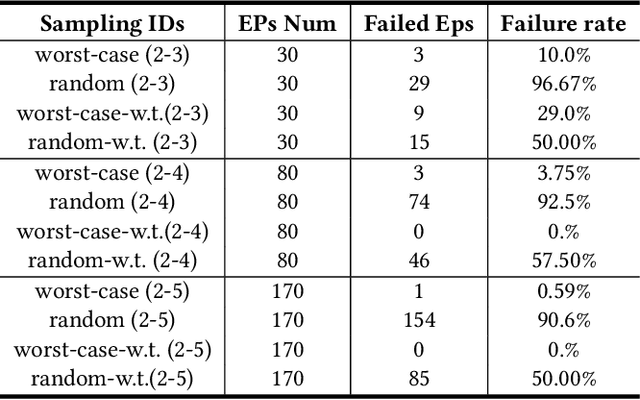
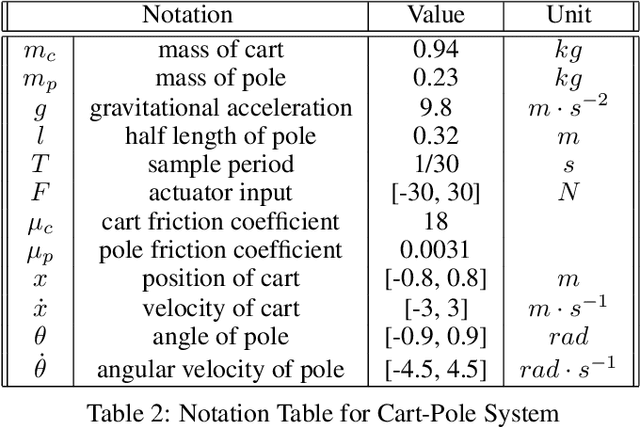
Real-world accidents in learning-enabled CPS frequently occur in challenging corner cases. During the training of deep reinforcement learning (DRL) policy, the standard setup for training conditions is either fixed at a single initial condition or uniformly sampled from the admissible state space. This setup often overlooks the challenging but safety-critical corner cases. To bridge this gap, this paper proposes a physics-model-guided worst-case sampling strategy for training safe policies that can handle safety-critical cases toward guaranteed safety. Furthermore, we integrate the proposed worst-case sampling strategy into the physics-regulated deep reinforcement learning (Phy-DRL) framework to build a more data-efficient and safe learning algorithm for safety-critical CPS. We validate the proposed training strategy with Phy-DRL through extensive experiments on a simulated cart-pole system, a 2D quadrotor, a simulated and a real quadruped robot, showing remarkably improved sampling efficiency to learn more robust safe policies.
Action Mapping for Reinforcement Learning in Continuous Environments with Constraints
Dec 05, 2024



Deep reinforcement learning (DRL) has had success across various domains, but applying it to environments with constraints remains challenging due to poor sample efficiency and slow convergence. Recent literature explored incorporating model knowledge to mitigate these problems, particularly through the use of models that assess the feasibility of proposed actions. However, integrating feasibility models efficiently into DRL pipelines in environments with continuous action spaces is non-trivial. We propose a novel DRL training strategy utilizing action mapping that leverages feasibility models to streamline the learning process. By decoupling the learning of feasible actions from policy optimization, action mapping allows DRL agents to focus on selecting the optimal action from a reduced feasible action set. We demonstrate through experiments that action mapping significantly improves training performance in constrained environments with continuous action spaces, especially with imperfect feasibility models.
Simplex-enabled Safe Continual Learning Machine
Sep 05, 2024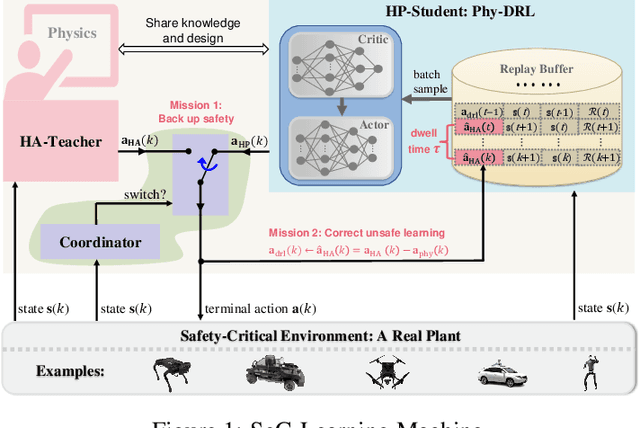

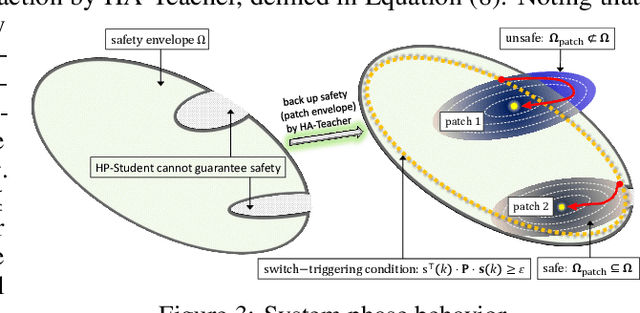
This paper proposes the SeC-Learning Machine: Simplex-enabled safe continual learning for safety-critical autonomous systems. The SeC-learning machine is built on Simplex logic (that is, ``using simplicity to control complexity'') and physics-regulated deep reinforcement learning (Phy-DRL). The SeC-learning machine thus constitutes HP (high performance)-Student, HA (high assurance)-Teacher, and Coordinator. Specifically, the HP-Student is a pre-trained high-performance but not fully verified Phy-DRL, continuing to learn in a real plant to tune the action policy to be safe. In contrast, the HA-Teacher is a mission-reduced, physics-model-based, and verified design. As a complementary, HA-Teacher has two missions: backing up safety and correcting unsafe learning. The Coordinator triggers the interaction and the switch between HP-Student and HA-Teacher. Powered by the three interactive components, the SeC-learning machine can i) assure lifetime safety (i.e., safety guarantee in any continual-learning stage, regardless of HP-Student's success or convergence), ii) address the Sim2Real gap, and iii) learn to tolerate unknown unknowns in real plants. The experiments on a cart-pole system and a real quadruped robot demonstrate the distinguished features of the SeC-learning machine, compared with continual learning built on state-of-the-art safe DRL frameworks with approaches to addressing the Sim2Real gap.
A Containerized Microservice Architecture for a ROS 2 Autonomous Driving Software: An End-to-End Latency Evaluation
Apr 19, 2024The automotive industry is transitioning from traditional ECU-based systems to software-defined vehicles. A central role of this revolution is played by containers, lightweight virtualization technologies that enable the flexible consolidation of complex software applications on a common hardware platform. Despite their widespread adoption, the impact of containerization on fundamental real-time metrics such as end-to-end latency, communication jitter, as well as memory and CPU utilization has remained virtually unexplored. This paper presents a microservice architecture for a real-world autonomous driving application where containers isolate each service. Our comprehensive evaluation shows the benefits in terms of end-to-end latency of such a solution even over standard bare-Linux deployments. Specifically, in the case of the presented microservice architecture, the mean end-to-end latency can be improved by 5-8 %. Also, the maximum latencies were significantly reduced using container deployment.
Equivariant Ensembles and Regularization for Reinforcement Learning in Map-based Path Planning
Mar 19, 2024



In reinforcement learning (RL), exploiting environmental symmetries can significantly enhance efficiency, robustness, and performance. However, ensuring that the deep RL policy and value networks are respectively equivariant and invariant to exploit these symmetries is a substantial challenge. Related works try to design networks that are equivariant and invariant by construction, limiting them to a very restricted library of components, which in turn hampers the expressiveness of the networks. This paper proposes a method to construct equivariant policies and invariant value functions without specialized neural network components, which we term equivariant ensembles. We further add a regularization term for adding inductive bias during training. In a map-based path planning case study, we show how equivariant ensembles and regularization benefit sample efficiency and performance.
Strict Partitioning for Sporadic Rigid Gang Tasks
Mar 15, 2024


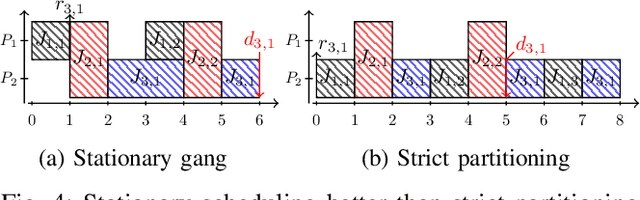
The rigid gang task model is based on the idea of executing multiple threads simultaneously on a fixed number of processors to increase efficiency and performance. Although there is extensive literature on global rigid gang scheduling, partitioned approaches have several practical advantages (e.g., task isolation and reduced scheduling overheads). In this paper, we propose a new partitioned scheduling strategy for rigid gang tasks, named strict partitioning. The method creates disjoint partitions of tasks and processors to avoid inter-partition interference. Moreover, it tries to assign tasks with similar volumes (i.e., parallelisms) to the same partition so that the intra-partition interference can be reduced. Within each partition, the tasks can be scheduled using any type of scheduler, which allows the use of a less pessimistic schedulability test. Extensive synthetic experiments and a case study based on Edge TPU benchmarks show that strict partitioning achieves better schedulability performance than state-of-the-art global gang schedulability analyses for both preemptive and non-preemptive rigid gang task sets.
RaceMOP: Mapless Online Path Planning for Multi-Agent Autonomous Racing using Residual Policy Learning
Mar 11, 2024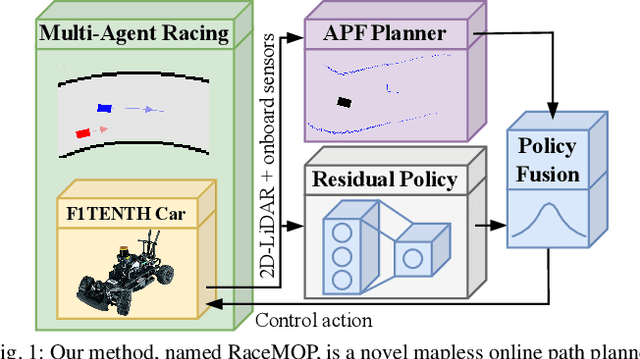
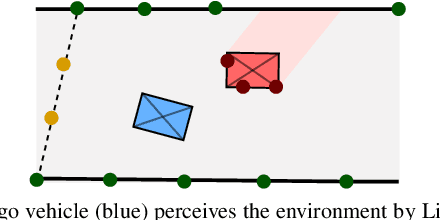
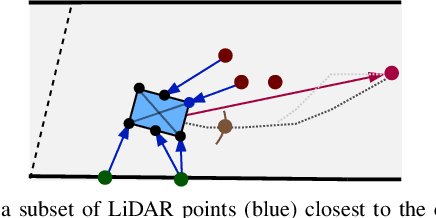
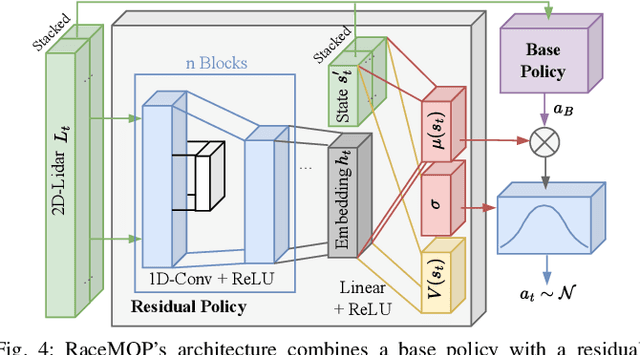
The interactive decision-making in multi-agent autonomous racing offers insights valuable beyond the domain of self-driving cars. Mapless online path planning is particularly of practical appeal but poses a challenge for safely overtaking opponents due to the limited planning horizon. Accordingly, this paper introduces RaceMOP, a novel method for mapless online path planning designed for multi-agent racing of F1TENTH cars. Unlike classical planners that depend on predefined racing lines, RaceMOP operates without a map, relying solely on local observations to overtake other race cars at high speed. Our approach combines an artificial potential field method as a base policy with residual policy learning to introduce long-horizon planning capabilities. We advance the field by introducing a novel approach for policy fusion with the residual policy directly in probability space. Our experiments for twelve simulated racetracks validate that RaceMOP is capable of long-horizon decision-making with robust collision avoidance during overtaking maneuvers. RaceMOP demonstrates superior handling over existing mapless planners while generalizing to unknown racetracks, paving the way for further use of our method in robotics. We make the open-source code for RaceMOP available at http://github.com/raphajaner/racemop.