 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Online Learning via Smooth Safety-Structured Policy Composition
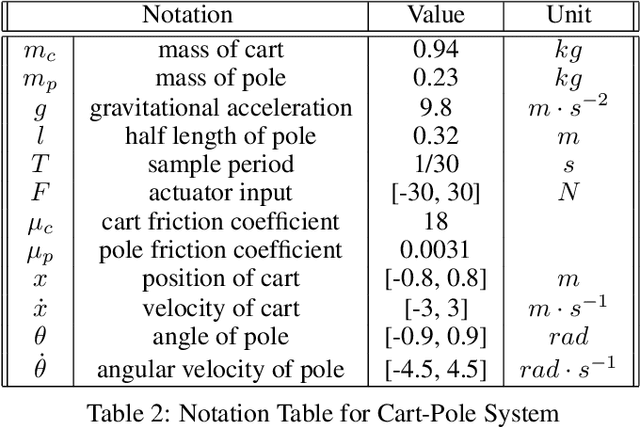
Jun 30, 2026Safe online reinforcement learning requires policies to respect safety constraints while maintaining smooth optimization dynamics. Existing approaches typically rely on either strict safety enforcement via action interventions, which introduce discontinuities in system interaction and learning, or soft safety constraint formulations, which preserve smooth learning but provide limited safety assurance. We propose AutoSafe, a safety-aware policy architecture that integrates structured safety monitoring and intervention directly into the action generation process. This design enables smooth, risk-dependent transitions between performance-driven and safety-preserving behaviors, resulting in continuous online interaction and learning dynamics. Empirical results across a suite of continuous-control benchmarks demonstrate strong safety enforcement without sacrificing learning smoothness. We further validate AutoSafe on a physical cart-pole system, highlighting its practical effectiveness for safe online learning in the real world.
Understanding the Theoretical Foundations of Deep Neural Networks through Differential Equations
Mar 18, 2026Deep neural networks (DNNs) have achieved remarkable empirical success, yet the absence of a principled theoretical foundation continues to hinder their systematic development. In this survey, we present differential equations as a theoretical foundation for understanding, analyzing, and improving DNNs. We organize the discussion around three guiding questions: i) how differential equations offer a principled understanding of DNN architectures, ii) how tools from differential equations can be used to improve DNN performance in a principled way, and iii) what real-world applications benefit from grounding DNNs in differential equations. We adopt a two-fold perspective spanning the model level, which interprets the whole DNN as a differential equation, and the layer level, which models individual DNN components as differential equations. From these two perspectives, we review how this framework connects model design, theoretical analysis, and performance improvement. We further discuss real-world applications, as well as key challenges and opportunities for future research.
Neural Probabilistic Circuits: Enabling Compositional and Interpretable Predictions through Logical Reasoning
Jan 13, 2025



End-to-end deep neural networks have achieved remarkable success across various domains but are often criticized for their lack of interpretability. While post hoc explanation methods attempt to address this issue, they often fail to accurately represent these black-box models, resulting in misleading or incomplete explanations. To overcome these challenges, we propose an inherently transparent model architecture called Neural Probabilistic Circuits (NPCs), which enable compositional and interpretable predictions through logical reasoning. In particular, an NPC consists of two modules: an attribute recognition model, which predicts probabilities for various attributes, and a task predictor built on a probabilistic circuit, which enables logical reasoning over recognized attributes to make class predictions. To train NPCs, we introduce a three-stage training algorithm comprising attribute recognition, circuit construction, and joint optimization. Moreover, we theoretically demonstrate that an NPC's error is upper-bounded by a linear combination of the errors from its modules. To further demonstrate the interpretability of NPC, we provide both the most probable explanations and the counterfactual explanations. Empirical results on four benchmark datasets show that NPCs strike a balance between interpretability and performance, achieving results competitive even with those of end-to-end black-box models while providing enhanced interpretability.
Physics-model-guided Worst-case Sampling for Safe Reinforcement Learning
Dec 17, 2024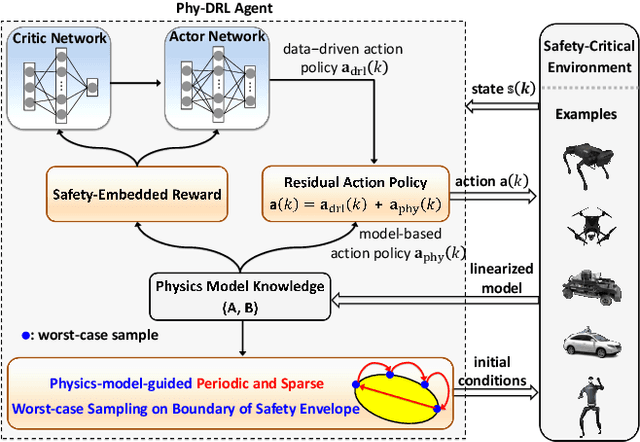

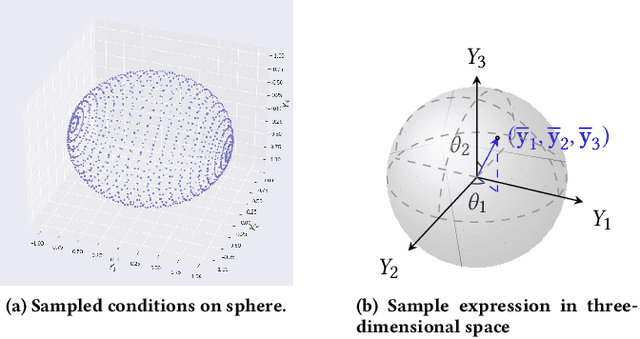
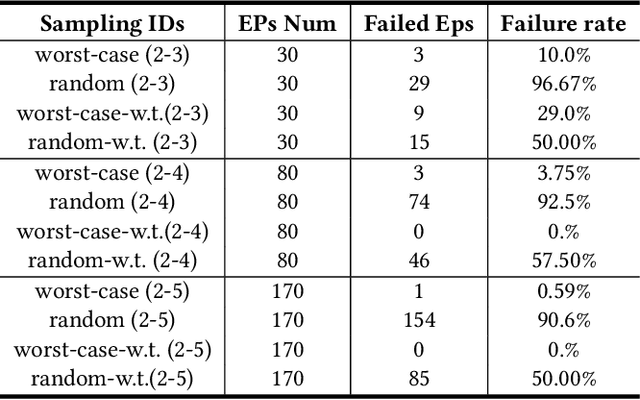
Real-world accidents in learning-enabled CPS frequently occur in challenging corner cases. During the training of deep reinforcement learning (DRL) policy, the standard setup for training conditions is either fixed at a single initial condition or uniformly sampled from the admissible state space. This setup often overlooks the challenging but safety-critical corner cases. To bridge this gap, this paper proposes a physics-model-guided worst-case sampling strategy for training safe policies that can handle safety-critical cases toward guaranteed safety. Furthermore, we integrate the proposed worst-case sampling strategy into the physics-regulated deep reinforcement learning (Phy-DRL) framework to build a more data-efficient and safe learning algorithm for safety-critical CPS. We validate the proposed training strategy with Phy-DRL through extensive experiments on a simulated cart-pole system, a 2D quadrotor, a simulated and a real quadruped robot, showing remarkably improved sampling efficiency to learn more robust safe policies.
Verification and Validation of a Vision-Based Landing System for Autonomous VTOL Air Taxis
Dec 11, 2024
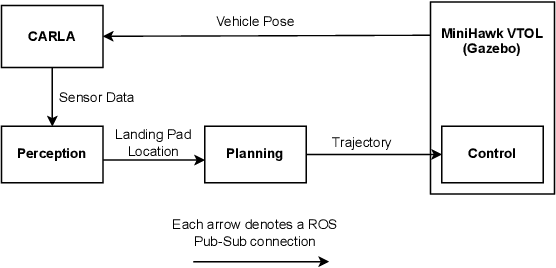
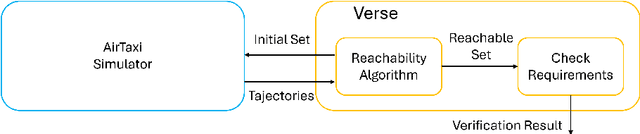
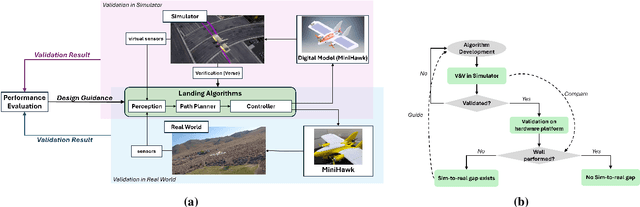
Autonomous air taxis are poised to revolutionize urban mass transportation, however, ensuring their safety and reliability remains an open challenge. Validating autonomy solutions on air taxis in the real world presents complexities, risks, and costs that further convolute this challenge. Verification and Validation (V&V) frameworks play a crucial role in the design and development of highly reliable systems by formally verifying safety properties and validating algorithm behavior across diverse operational scenarios. Advancements in high-fidelity simulators have significantly enhanced their capability to emulate real-world conditions, encouraging their use for validating autonomous air taxi solutions, especially during early development stages. This evolution underscores the growing importance of simulation environments, not only as complementary tools to real-world testing but as essential platforms for evaluating algorithms in a controlled, reproducible, and scalable manner. This work presents a V&V framework for a vision-based landing system for air taxis with vertical take-off and landing (VTOL) capabilities. Specifically, we use Verse, a tool for formal verification, to model and verify the safety of the system by obtaining and analyzing the reachable sets. To conduct this analysis, we utilize a photorealistic simulation environment. The simulation environment, built on Unreal Engine, provides realistic terrain, weather, and sensor characteristics to emulate real-world conditions with high fidelity. To validate the safety analysis results, we conduct extensive scenario-based testing to assess the reachability set and robustness of the landing algorithm in various conditions. This approach showcases the representativeness of high-fidelity simulators, offering an effective means to analyze and refine algorithms before real-world deployment.
Bayesian Data Augmentation and Training for Perception DNN in Autonomous Aerial Vehicles
Dec 10, 2024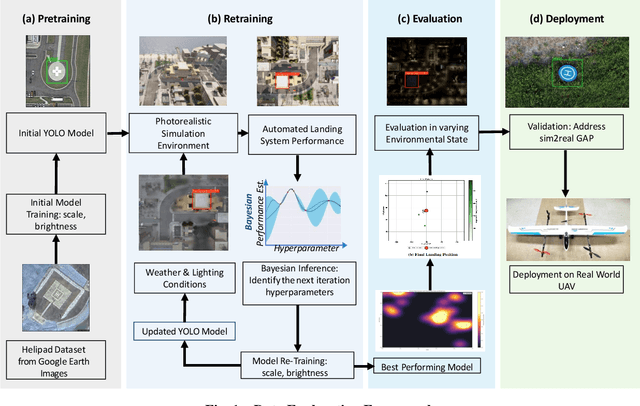
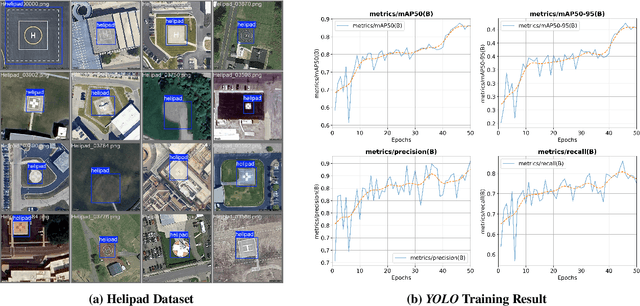
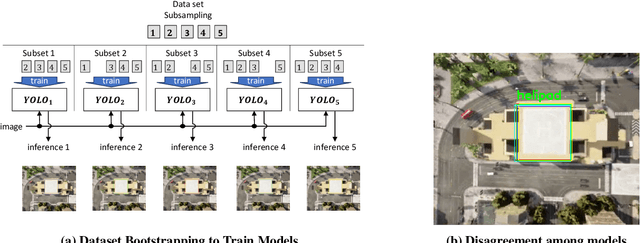
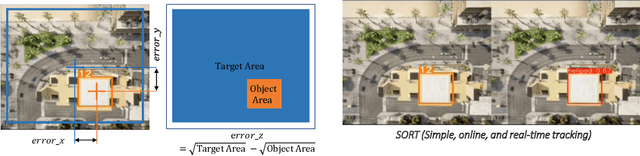
Learning-based solutions have enabled incredible capabilities for autonomous systems. Autonomous vehicles, both aerial and ground, rely on DNN for various integral tasks, including perception. The efficacy of supervised learning solutions hinges on the quality of the training data. Discrepancies between training data and operating conditions result in faults that can lead to catastrophic incidents. However, collecting vast amounts of context-sensitive data, with broad coverage of possible operating environments, is prohibitively difficult. Synthetic data generation techniques for DNN allow for the easy exploration of diverse scenarios. However, synthetic data generation solutions for aerial vehicles are still lacking. This work presents a data augmentation framework for aerial vehicle's perception training, leveraging photorealistic simulation integrated with high-fidelity vehicle dynamics. Safe landing is a crucial challenge in the development of autonomous air taxis, therefore, landing maneuver is chosen as the focus of this work. With repeated simulations of landing in varying scenarios we assess the landing performance of the VTOL type UAV and gather valuable data. The landing performance is used as the objective function to optimize the DNN through retraining. Given the high computational cost of DNN retraining, we incorporated Bayesian Optimization in our framework that systematically explores the data augmentation parameter space to retrain the best-performing models. The framework allowed us to identify high-performing data augmentation parameters that are consistently effective across different landing scenarios. Utilizing the capabilities of this data augmentation framework, we obtained a robust perception model. The model consistently improved the perception-based landing success rate by at least 20% under different lighting and weather conditions.
Simplex-enabled Safe Continual Learning Machine
Sep 05, 2024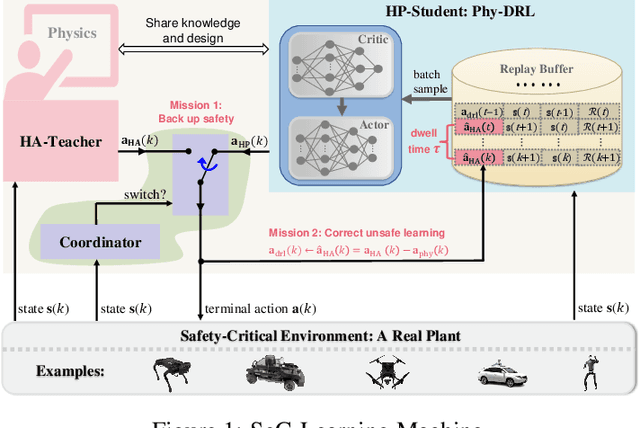

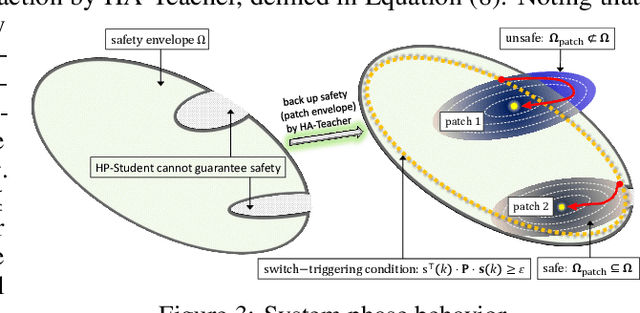
This paper proposes the SeC-Learning Machine: Simplex-enabled safe continual learning for safety-critical autonomous systems. The SeC-learning machine is built on Simplex logic (that is, ``using simplicity to control complexity'') and physics-regulated deep reinforcement learning (Phy-DRL). The SeC-learning machine thus constitutes HP (high performance)-Student, HA (high assurance)-Teacher, and Coordinator. Specifically, the HP-Student is a pre-trained high-performance but not fully verified Phy-DRL, continuing to learn in a real plant to tune the action policy to be safe. In contrast, the HA-Teacher is a mission-reduced, physics-model-based, and verified design. As a complementary, HA-Teacher has two missions: backing up safety and correcting unsafe learning. The Coordinator triggers the interaction and the switch between HP-Student and HA-Teacher. Powered by the three interactive components, the SeC-learning machine can i) assure lifetime safety (i.e., safety guarantee in any continual-learning stage, regardless of HP-Student's success or convergence), ii) address the Sim2Real gap, and iii) learn to tolerate unknown unknowns in real plants. The experiments on a cart-pole system and a real quadruped robot demonstrate the distinguished features of the SeC-learning machine, compared with continual learning built on state-of-the-art safe DRL frameworks with approaches to addressing the Sim2Real gap.
Synergistic Perception and Control Simplex for Verifiable Safe Vertical Landing
Dec 05, 2023



Perception, Planning, and Control form the essential components of autonomy in advanced air mobility. This work advances the holistic integration of these components to enhance the performance and robustness of the complete cyber-physical system. We adapt Perception Simplex, a system for verifiable collision avoidance amidst obstacle detection faults, to the vertical landing maneuver for autonomous air mobility vehicles. We improve upon this system by replacing static assumptions of control capabilities with dynamic confirmation, i.e., real-time confirmation of control limitations of the system, ensuring reliable fulfillment of safety maneuvers and overrides, without dependence on overly pessimistic assumptions. Parameters defining control system capabilities and limitations, e.g., maximum deceleration, are continuously tracked within the system and used to make safety-critical decisions. We apply these techniques to propose a verifiable collision avoidance solution for autonomous aerial mobility vehicles operating in cluttered and potentially unsafe environments.
Physical Deep Reinforcement Learning: Safety and Unknown Unknowns
May 26, 2023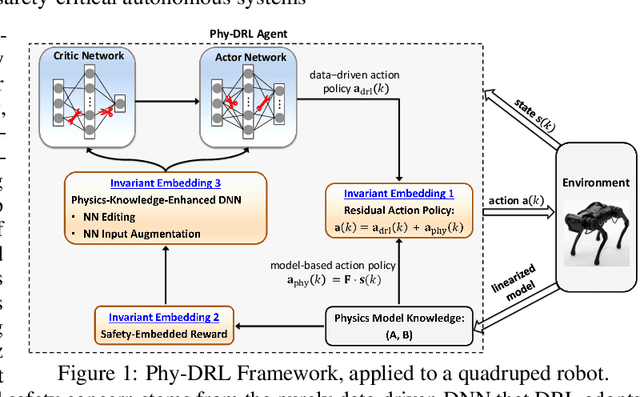
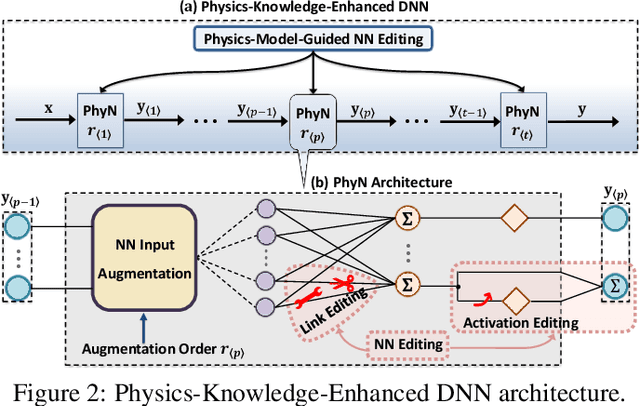

In this paper, we propose the Phy-DRL: a physics-model-regulated deep reinforcement learning framework for safety-critical autonomous systems. The Phy-DRL is unique in three innovations: i) proactive unknown-unknowns training, ii) conjunctive residual control (i.e., integration of data-driven control and physics-model-based control) and safety- \& stability-sensitive reward, and iii) physics-model-based neural network editing, including link editing and activation editing. Thanks to the concurrent designs, the Phy-DRL is able to 1) tolerate unknown-unknowns disturbances, 2) guarantee mathematically provable safety and stability, and 3) strictly comply with physical knowledge pertaining to Bellman equation and reward. The effectiveness of the Phy-DRL is finally validated by an inverted pendulum and a quadruped robot. The experimental results demonstrate that compared with purely data-driven DRL, Phy-DRL features remarkably fewer learning parameters, accelerated training and enlarged reward, while offering enhanced model robustness and safety assurance.
Physical Deep Reinforcement Learning Towards Safety Guarantee
Mar 29, 2023Deep reinforcement learning (DRL) has achieved tremendous success in many complex decision-making tasks of autonomous systems with high-dimensional state and/or action spaces. However, the safety and stability still remain major concerns that hinder the applications of DRL to safety-critical autonomous systems. To address the concerns, we proposed the Phy-DRL: a physical deep reinforcement learning framework. The Phy-DRL is novel in two architectural designs: i) Lyapunov-like reward, and ii) residual control (i.e., integration of physics-model-based control and data-driven control). The concurrent physical reward and residual control empower the Phy-DRL the (mathematically) provable safety and stability guarantees. Through experiments on the inverted pendulum, we show that the Phy-DRL features guaranteed safety and stability and enhanced robustness, while offering remarkably accelerated training and enlarged reward.