 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECA: Efficient Continual Alignment for Open-Ended Image-to-Text Generation
Jun 10, 2026Incremental Learning (IL) for Open-ended Image-to-Text Generation (OpenITG) enables models to continuously generate accurate, contextually relevant text for new images while preserving previously acquired knowledge. Unlike prior studies, this paper addresses a more practical scenario in which the predominant category of visual data shifts over time as environments evolve. In this context, we introduce a new notion of continual alignment, which incrementally adapts the alignment module within pre-trained VLMs to preserve high-quality cross-modal representations. Based on this idea, we propose Efficient Continual Alignment (ECA), a novel exemplar-free IL approach for OpenITG. The key challenge is enabling the model to acquire new, task-specific features while minimizing interference with the established alignment without accessing raw data from previous tasks. To address this, ECA employs three core mechanisms: a Mixture of Query (MoQ) module that adapts task-specific query tokens, a Fisher Dynamic Expansion (FeDEx) that dynamically expands model structure based on a Fisher Information Matrix (FIM)-based metric, and an embedding dictionary with Dictionary Replay (DR) to retain past knowledge. To evaluate ECA's performance, we construct four new IL OpenITG benchmarks that better reflect real-world scenarios. Experimental results demonstrate that ECA significantly mitigates catastrophic forgetting and improves IL performance compared to baseline methods. Code and benchmarks are available at https://github.com/Snowball0823/ECA.
Understanding the Theoretical Foundations of Deep Neural Networks through Differential Equations
Mar 18, 2026Deep neural networks (DNNs) have achieved remarkable empirical success, yet the absence of a principled theoretical foundation continues to hinder their systematic development. In this survey, we present differential equations as a theoretical foundation for understanding, analyzing, and improving DNNs. We organize the discussion around three guiding questions: i) how differential equations offer a principled understanding of DNN architectures, ii) how tools from differential equations can be used to improve DNN performance in a principled way, and iii) what real-world applications benefit from grounding DNNs in differential equations. We adopt a two-fold perspective spanning the model level, which interprets the whole DNN as a differential equation, and the layer level, which models individual DNN components as differential equations. From these two perspectives, we review how this framework connects model design, theoretical analysis, and performance improvement. We further discuss real-world applications, as well as key challenges and opportunities for future research.
WestWorld: A Knowledge-Encoded Scalable Trajectory World Model for Diverse Robotic Systems
Mar 15, 2026Trajectory world models play a crucial role in robotic dynamics learning, planning, and control. While recent works have explored trajectory world models for diverse robotic systems, they struggle to scale to a large number of distinct system dynamics and overlook domain knowledge of physical structures. To address these limitations, we introduce WestWorld, a knoWledge-Encoded Scalable Trajectory World model for diverse robotic systems. To tackle the scalability challenge, we propose a novel system-aware Mixture-of-Experts (Sys-MoE) that dynamically combines and routes specialized experts for different robotic systems via a learnable system embedding. To further enhance zero-shot generalization, we incorporate domain knowledge of robot physical structures by introducing a structural embedding that aligns trajectory representations with morphological information. After pretraining on 89 complex environments spanning diverse morphologies across both simulation and real-world settings, WestWorld achieves significant improvements over competitive baselines in zero- and few-shot trajectory prediction. Additionally, it shows strong scalability across a wide range of robotic environments and significantly improves performance on downstream model-based control for different robots. Finally, we deploy our model on a real-world Unitree Go1, where it demonstrates stable locomotion performance (see our demo on the website: https://westworldrobot.github.io/). The code will be available upon publication.
ODESteer: A Unified ODE-Based Steering Framework for LLM Alignment
Feb 19, 2026Activation steering, or representation engineering, offers a lightweight approach to align large language models (LLMs) by manipulating their internal activations at inference time. However, current methods suffer from two key limitations: \textit{(i)} the lack of a unified theoretical framework for guiding the design of steering directions, and \textit{(ii)} an over-reliance on \textit{one-step steering} that fail to capture complex patterns of activation distributions. In this work, we propose a unified ordinary differential equations (ODEs)-based \textit{theoretical} framework for activation steering in LLM alignment. We show that conventional activation addition can be interpreted as a first-order approximation to the solution of an ODE. Based on this ODE perspective, identifying a steering direction becomes equivalent to designing a \textit{barrier function} from control theory. Derived from this framework, we introduce ODESteer, a kind of ODE-based steering guided by barrier functions, which shows \textit{empirical} advancement in LLM alignment. ODESteer identifies steering directions by defining the barrier function as the log-density ratio between positive and negative activations, and employs it to construct an ODE for \textit{multi-step and adaptive} steering. Compared to state-of-the-art activation steering methods, ODESteer achieves consistent empirical improvements on diverse LLM alignment benchmarks, a notable $5.7\%$ improvement over TruthfulQA, $2.5\%$ over UltraFeedback, and $2.4\%$ over RealToxicityPrompts. Our work establishes a principled new view of activation steering in LLM alignment by unifying its theoretical foundations via ODEs, and validating it empirically through the proposed ODESteer method.
A Generalizable Physics-guided Causal Model for Trajectory Prediction in Autonomous Driving
Feb 15, 2026Trajectory prediction for traffic agents is critical for safe autonomous driving. However, achieving effective zero-shot generalization in previously unseen domains remains a significant challenge. Motivated by the consistent nature of kinematics across diverse domains, we aim to incorporate domain-invariant knowledge to enhance zero-shot trajectory prediction capabilities. The key challenges include: 1) effectively extracting domain-invariant scene representations, and 2) integrating invariant features with kinematic models to enable generalized predictions. To address these challenges, we propose a novel generalizable Physics-guided Causal Model (PCM), which comprises two core components: a Disentangled Scene Encoder, which adopts intervention-based disentanglement to extract domain-invariant features from scenes, and a CausalODE Decoder, which employs a causal attention mechanism to effectively integrate kinematic models with meaningful contextual information. Extensive experiments on real-world autonomous driving datasets demonstrate our method's superior zero-shot generalization performance in unseen cities, significantly outperforming competitive baselines. The source code is released at https://github.com/ZY-Zong/Physics-guided-Causal-Model.
Towards Comprehensive Benchmarking Infrastructure for LLMs In Software Engineering
Jan 28, 2026Large language models for code are advancing fast, yet our ability to evaluate them lags behind. Current benchmarks focus on narrow tasks and single metrics, which hide critical gaps in robustness, interpretability, fairness, efficiency, and real-world usability. They also suffer from inconsistent data engineering practices, limited software engineering context, and widespread contamination issues. To understand these problems and chart a path forward, we combined an in-depth survey of existing benchmarks with insights gathered from a dedicated community workshop. We identified three core barriers to reliable evaluation: the absence of software-engineering-rich datasets, overreliance on ML-centric metrics, and the lack of standardized, reproducible data pipelines. Building on these findings, we introduce BEHELM, a holistic benchmarking infrastructure that unifies software-scenario specification with multi-metric evaluation. BEHELM provides a structured way to assess models across tasks, languages, input and output granularities, and key quality dimensions. Our goal is to reduce the overhead currently required to construct benchmarks while enabling a fair, realistic, and future-proof assessment of LLMs in software engineering.
* Short paper from bechmarking for software engineering workshop FSE2025
P3SL: Personalized Privacy-Preserving Split Learning on Heterogeneous Edge Devices
Jul 23, 2025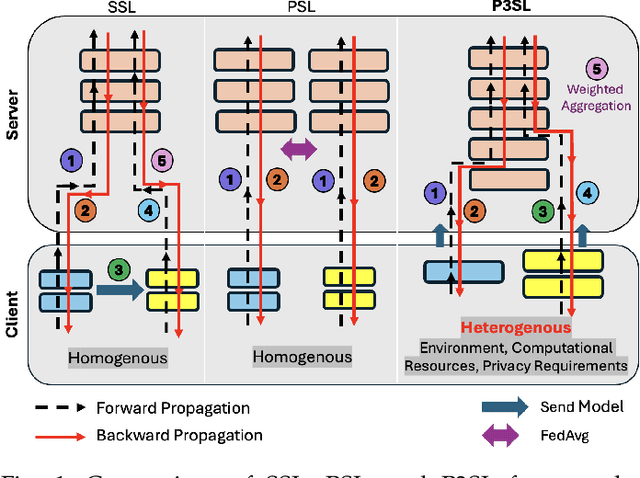

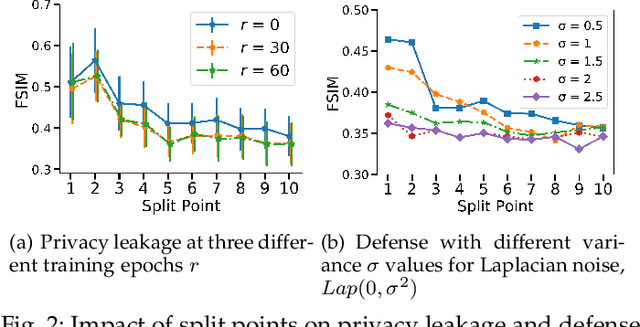
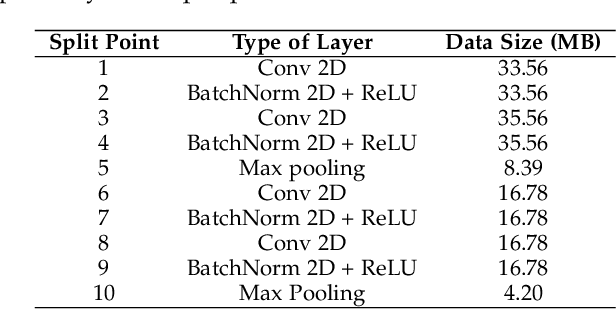
Split Learning (SL) is an emerging privacy-preserving machine learning technique that enables resource constrained edge devices to participate in model training by partitioning a model into client-side and server-side sub-models. While SL reduces computational overhead on edge devices, it encounters significant challenges in heterogeneous environments where devices vary in computing resources, communication capabilities, environmental conditions, and privacy requirements. Although recent studies have explored heterogeneous SL frameworks that optimize split points for devices with varying resource constraints, they often neglect personalized privacy requirements and local model customization under varying environmental conditions. To address these limitations, we propose P3SL, a Personalized Privacy-Preserving Split Learning framework designed for heterogeneous, resource-constrained edge device systems. The key contributions of this work are twofold. First, we design a personalized sequential split learning pipeline that allows each client to achieve customized privacy protection and maintain personalized local models tailored to their computational resources, environmental conditions, and privacy needs. Second, we adopt a bi-level optimization technique that empowers clients to determine their own optimal personalized split points without sharing private sensitive information (i.e., computational resources, environmental conditions, privacy requirements) with the server. This approach balances energy consumption and privacy leakage risks while maintaining high model accuracy. We implement and evaluate P3SL on a testbed consisting of 7 devices including 4 Jetson Nano P3450 devices, 2 Raspberry Pis, and 1 laptop, using diverse model architectures and datasets under varying environmental conditions.
Explore the vulnerability of black-box models via diffusion models
Jun 09, 2025



Recent advancements in diffusion models have enabled high-fidelity and photorealistic image generation across diverse applications. However, these models also present security and privacy risks, including copyright violations, sensitive information leakage, and the creation of harmful or offensive content that could be exploited maliciously. In this study, we uncover a novel security threat where an attacker leverages diffusion model APIs to generate synthetic images, which are then used to train a high-performing substitute model. This enables the attacker to execute model extraction and transfer-based adversarial attacks on black-box classification models with minimal queries, without needing access to the original training data. The generated images are sufficiently high-resolution and diverse to train a substitute model whose outputs closely match those of the target model. Across the seven benchmarks, including CIFAR and ImageNet subsets, our method shows an average improvement of 27.37% over state-of-the-art methods while using just 0.01 times of the query budget, achieving a 98.68% success rate in adversarial attacks on the target model.
Neural Probabilistic Circuits: Enabling Compositional and Interpretable Predictions through Logical Reasoning
Jan 13, 2025



End-to-end deep neural networks have achieved remarkable success across various domains but are often criticized for their lack of interpretability. While post hoc explanation methods attempt to address this issue, they often fail to accurately represent these black-box models, resulting in misleading or incomplete explanations. To overcome these challenges, we propose an inherently transparent model architecture called Neural Probabilistic Circuits (NPCs), which enable compositional and interpretable predictions through logical reasoning. In particular, an NPC consists of two modules: an attribute recognition model, which predicts probabilities for various attributes, and a task predictor built on a probabilistic circuit, which enables logical reasoning over recognized attributes to make class predictions. To train NPCs, we introduce a three-stage training algorithm comprising attribute recognition, circuit construction, and joint optimization. Moreover, we theoretically demonstrate that an NPC's error is upper-bounded by a linear combination of the errors from its modules. To further demonstrate the interpretability of NPC, we provide both the most probable explanations and the counterfactual explanations. Empirical results on four benchmark datasets show that NPCs strike a balance between interpretability and performance, achieving results competitive even with those of end-to-end black-box models while providing enhanced interpretability.
Hybrid Memory Replay: Blending Real and Distilled Data for Class Incremental Learning
Oct 20, 2024



Incremental learning (IL) aims to acquire new knowledge from current tasks while retaining knowledge learned from previous tasks. Replay-based IL methods store a set of exemplars from previous tasks in a buffer and replay them when learning new tasks. However, there is usually a size-limited buffer that cannot store adequate real exemplars to retain the knowledge of previous tasks. In contrast, data distillation (DD) can reduce the exemplar buffer's size, by condensing a large real dataset into a much smaller set of more information-compact synthetic exemplars. Nevertheless, DD's performance gain on IL quickly vanishes as the number of synthetic exemplars grows. To overcome the weaknesses of real-data and synthetic-data buffers, we instead optimize a hybrid memory including both types of data. Specifically, we propose an innovative modification to DD that distills synthetic data from a sliding window of checkpoints in history (rather than checkpoints on multiple training trajectories). Conditioned on the synthetic data, we then optimize the selection of real exemplars to provide complementary improvement to the DD objective. The optimized hybrid memory combines the strengths of synthetic and real exemplars, effectively mitigating catastrophic forgetting in Class IL (CIL) when the buffer size for exemplars is limited. Notably, our method can be seamlessly integrated into most existing replay-based CIL models. Extensive experiments across multiple benchmarks demonstrate that our method significantly outperforms existing replay-based baselines.