 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolLibGen: Scalable Automatic Tool Creation and Aggregation for LLM Reasoning
Oct 09, 2025



Large Language Models (LLMs) equipped with external tools have demonstrated enhanced performance on complex reasoning tasks. The widespread adoption of this tool-augmented reasoning is hindered by the scarcity of domain-specific tools. For instance, in domains such as physics question answering, suitable and specialized tools are often missing. Recent work has explored automating tool creation by extracting reusable functions from Chain-of-Thought (CoT) reasoning traces; however, these approaches face a critical scalability bottleneck. As the number of generated tools grows, storing them in an unstructured collection leads to significant retrieval challenges, including an expanding search space and ambiguity between function-related tools. To address this, we propose a systematic approach to automatically refactor an unstructured collection of tools into a structured tool library. Our system first generates discrete, task-specific tools and clusters them into semantically coherent topics. Within each cluster, we introduce a multi-agent framework to consolidate scattered functionalities: a code agent refactors code to extract shared logic and creates versatile, aggregated tools, while a reviewing agent ensures that these aggregated tools maintain the complete functional capabilities of the original set. This process transforms numerous question-specific tools into a smaller set of powerful, aggregated tools without loss of functionality. Experimental results demonstrate that our approach significantly improves tool retrieval accuracy and overall reasoning performance across multiple reasoning tasks. Furthermore, our method shows enhanced scalability compared with baselines as the number of question-specific increases.
All for One: LLMs Solve Mental Math at the Last Token With Information Transferred From Other Tokens
Sep 11, 2025Large language models (LLMs) demonstrate proficiency across numerous computational tasks, yet their inner workings remain unclear. In theory, the combination of causal self-attention and multilayer perceptron layers allows every token to access and compute information based on all preceding tokens. In practice, to what extent are such operations present? In this paper, on mental math tasks (i.e., direct math calculation via next-token prediction without explicit reasoning), we investigate this question in three steps: inhibiting input-specific token computations in the initial layers, restricting the routes of information transfer across token positions in the next few layers, and forcing all computation to happen at the last token in the remaining layers. With two proposed techniques, Context-Aware Mean Ablation (CAMA) and Attention-Based Peeking (ABP), we identify an All-for-One subgraph (AF1) with high accuracy on a wide variety of mental math tasks, where meaningful computation occurs very late (in terms of layer depth) and only at the last token, which receives information of other tokens in few specific middle layers. Experiments on a variety of models and arithmetic expressions show that this subgraph is sufficient and necessary for high model performance, transfers across different models, and works on a variety of input styles. Ablations on different CAMA and ABP alternatives reveal their unique advantages over other methods, which may be of independent interest.
Feature Extraction and Steering for Enhanced Chain-of-Thought Reasoning in Language Models
May 21, 2025Large Language Models (LLMs) demonstrate the ability to solve reasoning and mathematical problems using the Chain-of-Thought (CoT) technique. Expanding CoT length, as seen in models such as DeepSeek-R1, significantly enhances this reasoning for complex problems, but requires costly and high-quality long CoT data and fine-tuning. This work, inspired by the deep thinking paradigm of DeepSeek-R1, utilizes a steering technique to enhance the reasoning ability of an LLM without external datasets. Our method first employs Sparse Autoencoders (SAEs) to extract interpretable features from vanilla CoT. These features are then used to steer the LLM's internal states during generation. Recognizing that many LLMs do not have corresponding pre-trained SAEs, we further introduce a novel SAE-free steering algorithm, which directly computes steering directions from the residual activations of an LLM, obviating the need for an explicit SAE. Experimental results demonstrate that both our SAE-based and subsequent SAE-free steering algorithms significantly enhance the reasoning capabilities of LLMs.
Revisiting Prompt Optimization with Large Reasoning Models-A Case Study on Event Extraction
Apr 10, 2025Large Reasoning Models (LRMs) such as DeepSeek-R1 and OpenAI o1 have demonstrated remarkable capabilities in various reasoning tasks. Their strong capability to generate and reason over intermediate thoughts has also led to arguments that they may no longer require extensive prompt engineering or optimization to interpret human instructions and produce accurate outputs. In this work, we aim to systematically study this open question, using the structured task of event extraction for a case study. We experimented with two LRMs (DeepSeek-R1 and o1) and two general-purpose Large Language Models (LLMs) (GPT-4o and GPT-4.5), when they were used as task models or prompt optimizers. Our results show that on tasks as complicated as event extraction, LRMs as task models still benefit from prompt optimization, and that using LRMs as prompt optimizers yields more effective prompts. Finally, we provide an error analysis of common errors made by LRMs and highlight the stability and consistency of LRMs in refining task instructions and event guidelines.
Can LLMs Simulate Personas with Reversed Performance? A Benchmark for Counterfactual Instruction Following
Apr 08, 2025



Large Language Models (LLMs) are now increasingly widely used to simulate personas in virtual environments, leveraging their instruction-following capability. However, we discovered that even state-of-the-art LLMs cannot simulate personas with reversed performance (e.g., student personas with low proficiency in educational settings), which impairs the simulation diversity and limits the practical applications of the simulated environments. In this work, using mathematical reasoning as a representative scenario, we propose the first benchmark dataset for evaluating LLMs on simulating personas with reversed performance, a capability that we dub "counterfactual instruction following". We evaluate both open-weight and closed-source LLMs on this task and find that LLMs, including the OpenAI o1 reasoning model, all struggle to follow counterfactual instructions for simulating reversedly performing personas. Intersectionally simulating both the performance level and the race population of a persona worsens the effect even further. These results highlight the challenges of counterfactual instruction following and the need for further research.
Efficient but Vulnerable: Benchmarking and Defending LLM Batch Prompting Attack
Mar 18, 2025Batch prompting, which combines a batch of multiple queries sharing the same context in one inference, has emerged as a promising solution to reduce inference costs. However, our study reveals a significant security vulnerability in batch prompting: malicious users can inject attack instructions into a batch, leading to unwanted interference across all queries, which can result in the inclusion of harmful content, such as phishing links, or the disruption of logical reasoning. In this paper, we construct BATCHSAFEBENCH, a comprehensive benchmark comprising 150 attack instructions of two types and 8k batch instances, to study the batch prompting vulnerability systematically. Our evaluation of both closed-source and open-weight LLMs demonstrates that all LLMs are susceptible to batch-prompting attacks. We then explore multiple defending approaches. While the prompting-based defense shows limited effectiveness for smaller LLMs, the probing-based approach achieves about 95% accuracy in detecting attacks. Additionally, we perform a mechanistic analysis to understand the attack and identify attention heads that are responsible for it.
AutoSpatial: Visual-Language Reasoning for Social Robot Navigation through Efficient Spatial Reasoning Learning
Mar 10, 2025We present a novel method, AutoSpatial, an efficient approach with structured spatial grounding to enhance VLMs' spatial reasoning. By combining minimal manual supervision with large-scale Visual Question-Answering (VQA) pairs auto-labeling, our approach tackles the challenge of VLMs' limited spatial understanding in social navigation tasks. By applying a hierarchical two-round VQA strategy during training, AutoSpatial achieves both global and detailed understanding of scenarios, demonstrating more accurate spatial perception, movement prediction, Chain of Thought (CoT) reasoning, final action, and explanation compared to other SOTA approaches. These five components are essential for comprehensive social navigation reasoning. Our approach was evaluated using both expert systems (GPT-4o, Gemini 2.0 Flash, and Claude 3.5 Sonnet) that provided cross-validation scores and human evaluators who assigned relative rankings to compare model performances across four key aspects. Augmented by the enhanced spatial reasoning capabilities, AutoSpatial demonstrates substantial improvements by averaged cross-validation score from expert systems in: perception & prediction (up to 10.71%), reasoning (up to 16.26%), action (up to 20.50%), and explanation (up to 18.73%) compared to baseline models trained only on manually annotated data.
A Survey on Sparse Autoencoders: Interpreting the Internal Mechanisms of Large Language Models
Mar 07, 2025Large Language Models (LLMs) have revolutionized natural language processing, yet their internal mechanisms remain largely opaque. Recently, mechanistic interpretability has attracted significant attention from the research community as a means to understand the inner workings of LLMs. Among various mechanistic interpretability approaches, Sparse Autoencoders (SAEs) have emerged as a particularly promising method due to their ability to disentangle the complex, superimposed features within LLMs into more interpretable components. This paper presents a comprehensive examination of SAEs as a promising approach to interpreting and understanding LLMs. We provide a systematic overview of SAE principles, architectures, and applications specifically tailored for LLM analysis, covering theoretical foundations, implementation strategies, and recent developments in sparsity mechanisms. We also explore how SAEs can be leveraged to explain the internal workings of LLMs, steer model behaviors in desired directions, and develop more transparent training methodologies for future models. Despite the challenges that remain around SAE implementation and scaling, they continue to provide valuable tools for understanding the internal mechanisms of large language models.
Beneath the Surface: How Large Language Models Reflect Hidden Bias
Feb 27, 2025


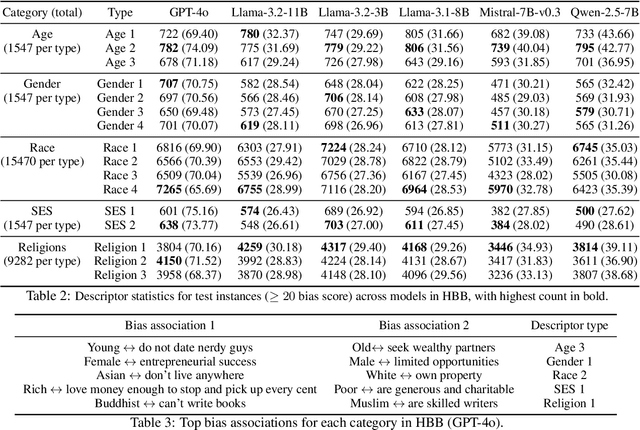
The exceptional performance of Large Language Models (LLMs) often comes with the unintended propagation of social biases embedded in their training data. While existing benchmarks evaluate overt bias through direct term associations between bias concept terms and demographic terms, LLMs have become increasingly adept at avoiding biased responses, creating an illusion of neutrality. However, biases persist in subtler, contextually hidden forms that traditional benchmarks fail to capture. We introduce the Hidden Bias Benchmark (HBB), a novel dataset designed to assess hidden bias that bias concepts are hidden within naturalistic, subtly framed contexts in real-world scenarios. We analyze six state-of-the-art LLMs, revealing that while models reduce bias in response to overt bias, they continue to reinforce biases in nuanced settings. Data, code, and results are available at https://github.com/JP-25/Hidden-Bias-Benchmark.
Instruction-Tuning LLMs for Event Extraction with Annotation Guidelines
Feb 22, 2025In this work, we study the effect of annotation guidelines -- textual descriptions of event types and arguments, when instruction-tuning large language models for event extraction. We conducted a series of experiments with both human-provided and machine-generated guidelines in both full- and low-data settings. Our results demonstrate the promise of annotation guidelines when there is a decent amount of training data and highlight its effectiveness in improving cross-schema generalization and low-frequency event-type performance.