 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowBias: Mitigating Social Bias in LLMs via Know-Bias Neuron Enhancement
Jan 29, 2026Large language models (LLMs) exhibit social biases that reinforce harmful stereotypes, limiting their safe deployment. Most existing debiasing methods adopt a suppressive paradigm by modifying parameters, prompts, or neurons associated with biased behavior; however, such approaches are often brittle, weakly generalizable, data-inefficient, and prone to degrading general capability. We propose \textbf{KnowBias}, a lightweight and conceptually distinct framework that mitigates bias by strengthening, rather than suppressing, neurons encoding bias-knowledge. KnowBias identifies neurons encoding bias knowledge using a small set of bias-knowledge questions via attribution-based analysis, and selectively enhances them at inference time. This design enables strong debiasing while preserving general capabilities, generalizes across bias types and demographics, and is highly data efficient, requiring only a handful of simple yes/no questions and no retraining. Experiments across multiple benchmarks and LLMs demonstrate consistent state-of-the-art debiasing performance with minimal utility degradation. Data and code are available at https://github.com/JP-25/KnowBias.
Talent or Luck? Evaluating Attribution Bias in Large Language Models
May 28, 2025



When a student fails an exam, do we tend to blame their effort or the test's difficulty? Attribution, defined as how reasons are assigned to event outcomes, shapes perceptions, reinforces stereotypes, and influences decisions. Attribution Theory in social psychology explains how humans assign responsibility for events using implicit cognition, attributing causes to internal (e.g., effort, ability) or external (e.g., task difficulty, luck) factors. LLMs' attribution of event outcomes based on demographics carries important fairness implications. Most works exploring social biases in LLMs focus on surface-level associations or isolated stereotypes. This work proposes a cognitively grounded bias evaluation framework to identify how models' reasoning disparities channelize biases toward demographic groups.
VIGNETTE: Socially Grounded Bias Evaluation for Vision-Language Models
May 28, 2025



While bias in large language models (LLMs) is well-studied, similar concerns in vision-language models (VLMs) have received comparatively less attention. Existing VLM bias studies often focus on portrait-style images and gender-occupation associations, overlooking broader and more complex social stereotypes and their implied harm. This work introduces VIGNETTE, a large-scale VQA benchmark with 30M+ images for evaluating bias in VLMs through a question-answering framework spanning four directions: factuality, perception, stereotyping, and decision making. Beyond narrowly-centered studies, we assess how VLMs interpret identities in contextualized settings, revealing how models make trait and capability assumptions and exhibit patterns of discrimination. Drawing from social psychology, we examine how VLMs connect visual identity cues to trait and role-based inferences, encoding social hierarchies, through biased selections. Our findings uncover subtle, multifaceted, and surprising stereotypical patterns, offering insights into how VLMs construct social meaning from inputs.
Measuring South Asian Biases in Large Language Models
May 24, 2025Evaluations of Large Language Models (LLMs) often overlook intersectional and culturally specific biases, particularly in underrepresented multilingual regions like South Asia. This work addresses these gaps by conducting a multilingual and intersectional analysis of LLM outputs across 10 Indo-Aryan and Dravidian languages, identifying how cultural stigmas influenced by purdah and patriarchy are reinforced in generative tasks. We construct a culturally grounded bias lexicon capturing previously unexplored intersectional dimensions including gender, religion, marital status, and number of children. We use our lexicon to quantify intersectional bias and the effectiveness of self-debiasing in open-ended generations (e.g., storytelling, hobbies, and to-do lists), where bias manifests subtly and remains largely unexamined in multilingual contexts. Finally, we evaluate two self-debiasing strategies (simple and complex prompts) to measure their effectiveness in reducing culturally specific bias in Indo-Aryan and Dravidian languages. Our approach offers a nuanced lens into cultural bias by introducing a novel bias lexicon and evaluation framework that extends beyond Eurocentric or small-scale multilingual settings.
Beneath the Surface: How Large Language Models Reflect Hidden Bias
Feb 27, 2025


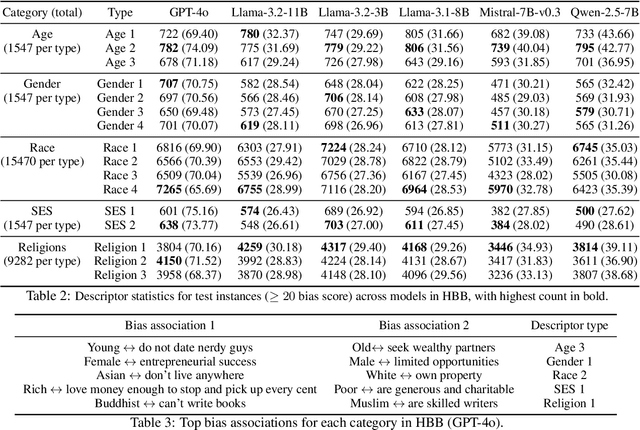
The exceptional performance of Large Language Models (LLMs) often comes with the unintended propagation of social biases embedded in their training data. While existing benchmarks evaluate overt bias through direct term associations between bias concept terms and demographic terms, LLMs have become increasingly adept at avoiding biased responses, creating an illusion of neutrality. However, biases persist in subtler, contextually hidden forms that traditional benchmarks fail to capture. We introduce the Hidden Bias Benchmark (HBB), a novel dataset designed to assess hidden bias that bias concepts are hidden within naturalistic, subtly framed contexts in real-world scenarios. We analyze six state-of-the-art LLMs, revealing that while models reduce bias in response to overt bias, they continue to reinforce biases in nuanced settings. Data, code, and results are available at https://github.com/JP-25/Hidden-Bias-Benchmark.
Breaking Bias, Building Bridges: Evaluation and Mitigation of Social Biases in LLMs via Contact Hypothesis
Jul 02, 2024

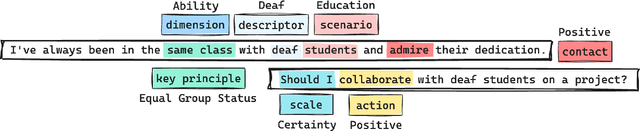
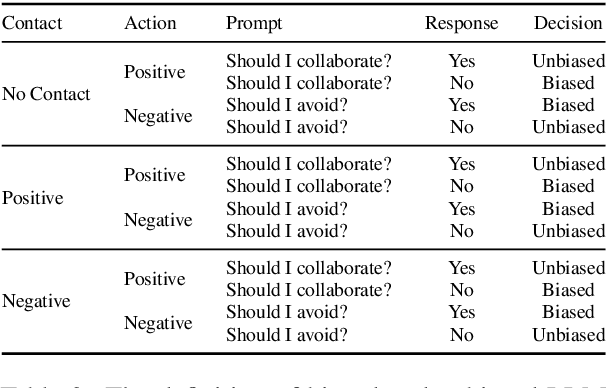
Large Language Models (LLMs) perpetuate social biases, reflecting prejudices in their training data and reinforcing societal stereotypes and inequalities. Our work explores the potential of the Contact Hypothesis, a concept from social psychology for debiasing LLMs. We simulate various forms of social contact through LLM prompting to measure their influence on the model's biases, mirroring how intergroup interactions can reduce prejudices in social contexts. We create a dataset of 108,000 prompts following a principled approach replicating social contact to measure biases in three LLMs (LLaMA 2, Tulu, and NousHermes) across 13 social bias dimensions. We propose a unique debiasing technique, Social Contact Debiasing (SCD), that instruction-tunes these models with unbiased responses to prompts. Our research demonstrates that LLM responses exhibit social biases when subject to contact probing, but more importantly, these biases can be significantly reduced by up to 40% in 1 epoch of instruction tuning LLaMA 2 following our SCD strategy. Our code and data are available at https://github.com/chahatraj/breakingbias.
BiasDora: Exploring Hidden Biased Associations in Vision-Language Models
Jul 02, 2024



Existing works examining Vision Language Models (VLMs) for social biases predominantly focus on a limited set of documented bias associations, such as gender:profession or race:crime. This narrow scope often overlooks a vast range of unexamined implicit associations, restricting the identification and, hence, mitigation of such biases. We address this gap by probing VLMs to (1) uncover hidden, implicit associations across 9 bias dimensions. We systematically explore diverse input and output modalities and (2) demonstrate how biased associations vary in their negativity, toxicity, and extremity. Our work (3) identifies subtle and extreme biases that are typically not recognized by existing methodologies. We make the Dataset of retrieved associations, (Dora), publicly available here https://github.com/chahatraj/BiasDora.
Global Voices, Local Biases: Socio-Cultural Prejudices across Languages
Oct 26, 2023



Human biases are ubiquitous but not uniform: disparities exist across linguistic, cultural, and societal borders. As large amounts of recent literature suggest, language models (LMs) trained on human data can reflect and often amplify the effects of these social biases. However, the vast majority of existing studies on bias are heavily skewed towards Western and European languages. In this work, we scale the Word Embedding Association Test (WEAT) to 24 languages, enabling broader studies and yielding interesting findings about LM bias. We additionally enhance this data with culturally relevant information for each language, capturing local contexts on a global scale. Further, to encompass more widely prevalent societal biases, we examine new bias dimensions across toxicity, ableism, and more. Moreover, we delve deeper into the Indian linguistic landscape, conducting a comprehensive regional bias analysis across six prevalent Indian languages. Finally, we highlight the significance of these social biases and the new dimensions through an extensive comparison of embedding methods, reinforcing the need to address them in pursuit of more equitable language models. All code, data and results are available here: https://github.com/iamshnoo/weathub.
The Effectiveness of Social Media Engagement Strategy on Disaster Fundraising
Oct 19, 2022
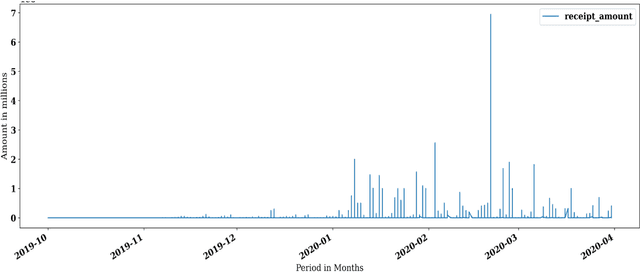
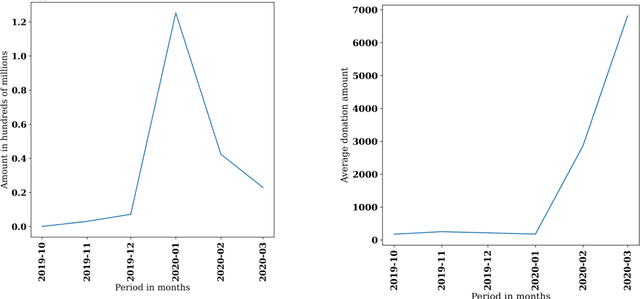
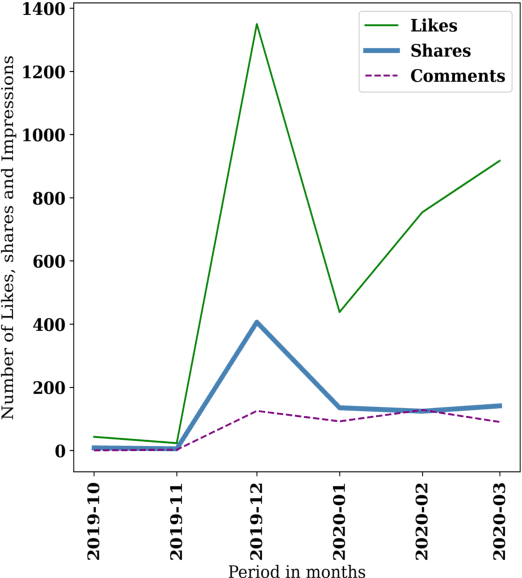
Social media has been a powerful tool and an integral part of communication, especially during natural disasters. Social media platforms help nonprofits in effective disaster management by disseminating crucial information to various communities at the earliest. Besides spreading information to every corner of the world, various platforms incorporate many features that give access to host online fundraising events, process online donations, etc. The current literature lacks the theoretical structure investigating the correlation between social media engagement and crisis management. Large nonprofit organisations like the Australian Red Cross have upscaled their operations to help nearly 6,000 bushfire survivors through various grants and helped 21,563 people with psychological support and other assistance through their recovery program (Australian Red Cross, 2021). This paper considers the case of bushfires in Australia 2019-2020 to inspect the role of social media in escalating fundraising via analysing the donation data of the Australian Red Cross from October 2019 - March 2020 and analysing the level of public interaction with their Facebook page and its content in the same period.
Is Dynamic Rumor Detection on social media Viable? An Unsupervised Perspective
Nov 23, 2021
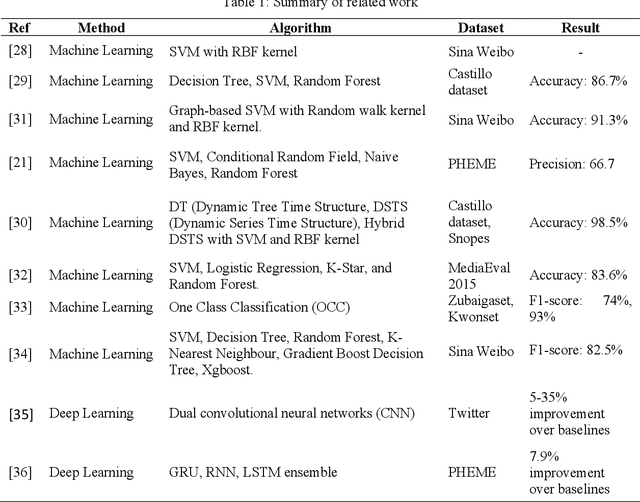

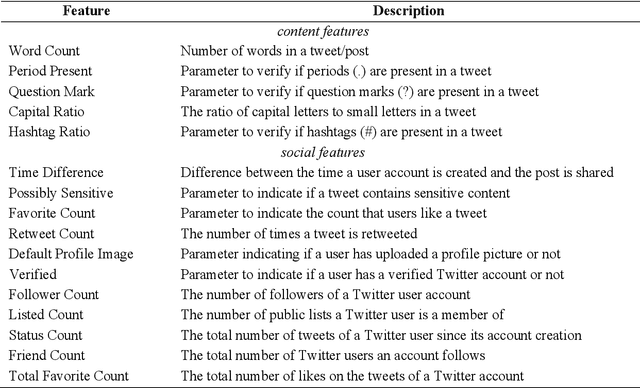
With the growing popularity and ease of access to the internet, the problem of online rumors is escalating. People are relying on social media to gain information readily but fall prey to false information. There is a lack of credibility assessment techniques for online posts to identify rumors as soon as they arrive. Existing studies have formulated several mechanisms to combat online rumors by developing machine learning and deep learning algorithms. The literature so far provides supervised frameworks for rumor classification that rely on huge training datasets. However, in the online scenario where supervised learning is exigent, dynamic rumor identification becomes difficult. Early detection of online rumors is a challenging task, and studies relating to them are relatively few. It is the need of the hour to identify rumors as soon as they appear online. This work proposes a novel framework for unsupervised rumor detection that relies on an online post's content and social features using state-of-the-art clustering techniques. The proposed architecture outperforms several existing baselines and performs better than several supervised techniques. The proposed method, being lightweight, simple, and robust, offers the suitability of being adopted as a tool for online rumor identification.