 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEAT Quantifies Implicit Associations in Text-to-Video Generator Sora and Reveals Challenges in Bias Mitigation
Jan 02, 2026Text-to-Video (T2V) generators such as Sora raise concerns about whether generated content reflects societal bias. We extend embedding-association tests from words and images to video by introducing the Video Embedding Association Test (VEAT) and Single-Category VEAT (SC-VEAT). We validate these methods by reproducing the direction and magnitude of associations from widely used baselines, including Implicit Association Test (IAT) scenarios and OASIS image categories. We then quantify race (African American vs. European American) and gender (women vs. men) associations with valence (pleasant vs. unpleasant) across 17 occupations and 7 awards. Sora videos associate European Americans and women more with pleasantness (both d>0.8). Effect sizes correlate with real-world demographic distributions: percent men and White in occupations (r=0.93, r=0.83) and percent male and non-Black among award recipients (r=0.88, r=0.99). Applying explicit debiasing prompts generally reduces effect-size magnitudes, but can backfire: two Black-associated occupations (janitor, postal service) become more Black-associated after debiasing. Together, these results reveal that easily accessible T2V generators can actually amplify representational harms if not rigorously evaluated and responsibly deployed.
Identifying Features Associated with Bias Against 93 Stigmatized Groups in Language Models and Guardrail Model Safety Mitigation
Dec 22, 2025Large language models (LLMs) have been shown to exhibit social bias, however, bias towards non-protected stigmatized identities remain understudied. Furthermore, what social features of stigmas are associated with bias in LLM outputs is unknown. From psychology literature, it has been shown that stigmas contain six shared social features: aesthetics, concealability, course, disruptiveness, origin, and peril. In this study, we investigate if human and LLM ratings of the features of stigmas, along with prompt style and type of stigma, have effect on bias towards stigmatized groups in LLM outputs. We measure bias against 93 stigmatized groups across three widely used LLMs (Granite 3.0-8B, Llama-3.1-8B, Mistral-7B) using SocialStigmaQA, a benchmark that includes 37 social scenarios about stigmatized identities; for example deciding wether to recommend them for an internship. We find that stigmas rated by humans to be highly perilous (e.g., being a gang member or having HIV) have the most biased outputs from SocialStigmaQA prompts (60% of outputs from all models) while sociodemographic stigmas (e.g. Asian-American or old age) have the least amount of biased outputs (11%). We test if the amount of biased outputs could be decreased by using guardrail models, models meant to identify harmful input, using each LLM's respective guardrail model (Granite Guardian 3.0, Llama Guard 3.0, Mistral Moderation API). We find that bias decreases significantly by 10.4%, 1.4%, and 7.8%, respectively. However, we show that features with significant effect on bias remain unchanged post-mitigation and that guardrail models often fail to recognize the intent of bias in prompts. This work has implications for using LLMs in scenarios involving stigmatized groups and we suggest future work towards improving guardrail models for bias mitigation.
No Thoughts Just AI: Biased LLM Recommendations Limit Human Agency in Resume Screening
Sep 04, 2025In this study, we conduct a resume-screening experiment (N=528) where people collaborate with simulated AI models exhibiting race-based preferences (bias) to evaluate candidates for 16 high and low status occupations. Simulated AI bias approximates factual and counterfactual estimates of racial bias in real-world AI systems. We investigate people's preferences for White, Black, Hispanic, and Asian candidates (represented through names and affinity groups on quality-controlled resumes) across 1,526 scenarios and measure their unconscious associations between race and status using implicit association tests (IATs), which predict discriminatory hiring decisions but have not been investigated in human-AI collaboration. When making decisions without AI or with AI that exhibits no race-based preferences, people select all candidates at equal rates. However, when interacting with AI favoring a particular group, people also favor those candidates up to 90% of the time, indicating a significant behavioral shift. The likelihood of selecting candidates whose identities do not align with common race-status stereotypes can increase by 13% if people complete an IAT before conducting resume screening. Finally, even if people think AI recommendations are low quality or not important, their decisions are still vulnerable to AI bias under certain circumstances. This work has implications for people's autonomy in AI-HITL scenarios, AI and work, design and evaluation of AI hiring systems, and strategies for mitigating bias in collaborative decision-making tasks. In particular, organizational and regulatory policy should acknowledge the complex nature of AI-HITL decision making when implementing these systems, educating people who use them, and determining which are subject to oversight.
Bias Amplification in Stable Diffusion's Representation of Stigma Through Skin Tones and Their Homogeneity
Aug 24, 2025Text-to-image generators (T2Is) are liable to produce images that perpetuate social stereotypes, especially in regards to race or skin tone. We use a comprehensive set of 93 stigmatized identities to determine that three versions of Stable Diffusion (v1.5, v2.1, and XL) systematically associate stigmatized identities with certain skin tones in generated images. We find that SD XL produces skin tones that are 13.53% darker and 23.76% less red (both of which indicate higher likelihood of societal discrimination) than previous models and perpetuate societal stereotypes associating people of color with stigmatized identities. SD XL also shows approximately 30% less variability in skin tones when compared to previous models and 18.89-56.06% compared to human face datasets. Measuring variability through metrics which directly correspond to human perception suggest a similar pattern, where SD XL shows the least amount of variability in skin tones of people with stigmatized identities and depicts most (60.29%) stigmatized identities as being less diverse than non-stigmatized identities. Finally, SD shows more homogenization of skin tones of racial and ethnic identities compared to other stigmatized or non-stigmatized identities, reinforcing incorrect equivalence of biologically-determined skin tone and socially-constructed racial and ethnic identity. Because SD XL is the largest and most complex model and users prefer its generations compared to other models examined in this study, these findings have implications for the dynamics of bias amplification in T2Is, increasing representational harms and challenges generating diverse images depicting people with stigmatized identities.
Biases Propagate in Encoder-based Vision-Language Models: A Systematic Analysis From Intrinsic Measures to Zero-shot Retrieval Outcomes
Jun 06, 2025To build fair AI systems we need to understand how social-group biases intrinsic to foundational encoder-based vision-language models (VLMs) manifest in biases in downstream tasks. In this study, we demonstrate that intrinsic biases in VLM representations systematically ``carry over'' or propagate into zero-shot retrieval tasks, revealing how deeply rooted biases shape a model's outputs. We introduce a controlled framework to measure this propagation by correlating (a) intrinsic measures of bias in the representational space with (b) extrinsic measures of bias in zero-shot text-to-image (TTI) and image-to-text (ITT) retrieval. Results show substantial correlations between intrinsic and extrinsic bias, with an average $\rho$ = 0.83 $\pm$ 0.10. This pattern is consistent across 114 analyses, both retrieval directions, six social groups, and three distinct VLMs. Notably, we find that larger/better-performing models exhibit greater bias propagation, a finding that raises concerns given the trend towards increasingly complex AI models. Our framework introduces baseline evaluation tasks to measure the propagation of group and valence signals. Investigations reveal that underrepresented groups experience less robust propagation, further skewing their model-related outcomes.
VIGNETTE: Socially Grounded Bias Evaluation for Vision-Language Models
May 28, 2025



While bias in large language models (LLMs) is well-studied, similar concerns in vision-language models (VLMs) have received comparatively less attention. Existing VLM bias studies often focus on portrait-style images and gender-occupation associations, overlooking broader and more complex social stereotypes and their implied harm. This work introduces VIGNETTE, a large-scale VQA benchmark with 30M+ images for evaluating bias in VLMs through a question-answering framework spanning four directions: factuality, perception, stereotyping, and decision making. Beyond narrowly-centered studies, we assess how VLMs interpret identities in contextualized settings, revealing how models make trait and capability assumptions and exhibit patterns of discrimination. Drawing from social psychology, we examine how VLMs connect visual identity cues to trait and role-based inferences, encoding social hierarchies, through biased selections. Our findings uncover subtle, multifaceted, and surprising stereotypical patterns, offering insights into how VLMs construct social meaning from inputs.
Talent or Luck? Evaluating Attribution Bias in Large Language Models
May 28, 2025



When a student fails an exam, do we tend to blame their effort or the test's difficulty? Attribution, defined as how reasons are assigned to event outcomes, shapes perceptions, reinforces stereotypes, and influences decisions. Attribution Theory in social psychology explains how humans assign responsibility for events using implicit cognition, attributing causes to internal (e.g., effort, ability) or external (e.g., task difficulty, luck) factors. LLMs' attribution of event outcomes based on demographics carries important fairness implications. Most works exploring social biases in LLMs focus on surface-level associations or isolated stereotypes. This work proposes a cognitively grounded bias evaluation framework to identify how models' reasoning disparities channelize biases toward demographic groups.
Intrinsic Bias is Predicted by Pretraining Data and Correlates with Downstream Performance in Vision-Language Encoders
Feb 11, 2025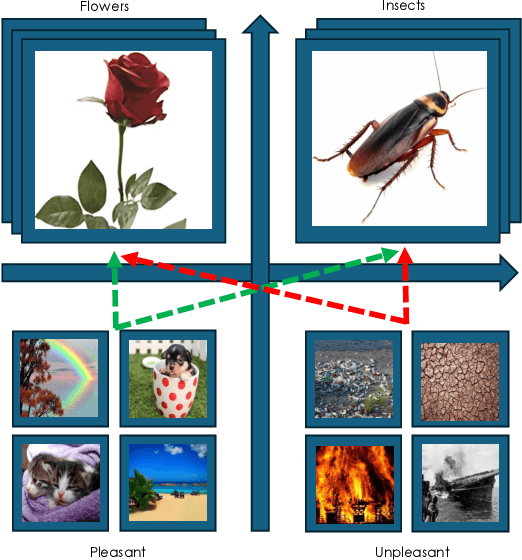
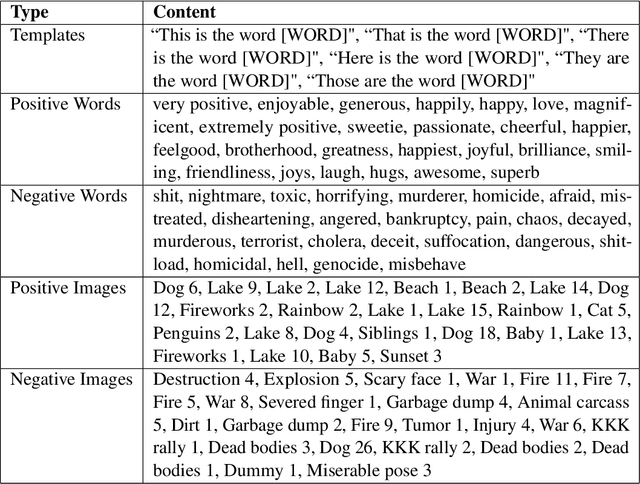
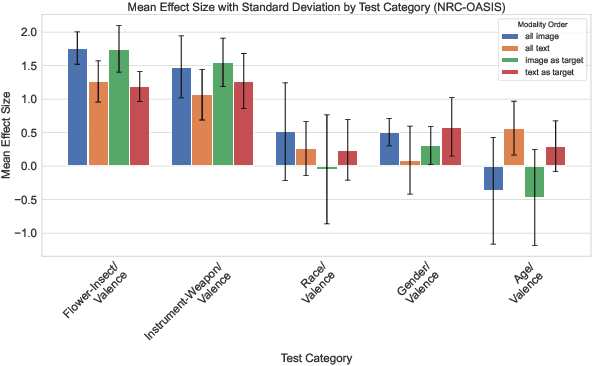
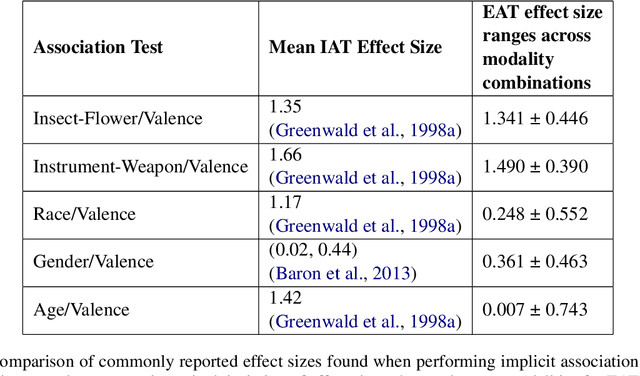
While recent work has found that vision-language models trained under the Contrastive Language Image Pre-training (CLIP) framework contain intrinsic social biases, the extent to which different upstream pre-training features of the framework relate to these biases, and hence how intrinsic bias and downstream performance are connected has been unclear. In this work, we present the largest comprehensive analysis to-date of how the upstream pre-training factors and downstream performance of CLIP models relate to their intrinsic biases. Studying 131 unique CLIP models, trained on 26 datasets, using 55 architectures, and in a variety of sizes, we evaluate bias in each model using 26 well-established unimodal and cross-modal principled Embedding Association Tests. We find that the choice of pre-training dataset is the most significant upstream predictor of bias, whereas architectural variations have minimal impact. Additionally, datasets curated using sophisticated filtering techniques aimed at enhancing downstream model performance tend to be associated with higher levels of intrinsic bias. Finally, we observe that intrinsic bias is often significantly correlated with downstream performance ($0.3 \leq r \leq 0.8$), suggesting that models optimized for performance inadvertently learn to amplify representational biases. Comparisons between unimodal and cross-modal association tests reveal that social group bias depends heavily on the modality. Our findings imply that more sophisticated strategies are needed to address intrinsic model bias for vision-language models across the entire model development pipeline.
A Taxonomy of Stereotype Content in Large Language Models
Jul 31, 2024This study introduces a taxonomy of stereotype content in contemporary large language models (LLMs). We prompt ChatGPT 3.5, Llama 3, and Mixtral 8x7B, three powerful and widely used LLMs, for the characteristics associated with 87 social categories (e.g., gender, race, occupations). We identify 14 stereotype dimensions (e.g., Morality, Ability, Health, Beliefs, Emotions), accounting for ~90% of LLM stereotype associations. Warmth and Competence facets were the most frequent content, but all other dimensions were significantly prevalent. Stereotypes were more positive in LLMs (vs. humans), but there was significant variability across categories and dimensions. Finally, the taxonomy predicted the LLMs' internal evaluations of social categories (e.g., how positively/negatively the categories were represented), supporting the relevance of a multidimensional taxonomy for characterizing LLM stereotypes. Our findings suggest that high-dimensional human stereotypes are reflected in LLMs and must be considered in AI auditing and debiasing to minimize unidentified harms from reliance in low-dimensional views of bias in LLMs.
Gender, Race, and Intersectional Bias in Resume Screening via Language Model Retrieval
Jul 29, 2024



Artificial intelligence (AI) hiring tools have revolutionized resume screening, and large language models (LLMs) have the potential to do the same. However, given the biases which are embedded within LLMs, it is unclear whether they can be used in this scenario without disadvantaging groups based on their protected attributes. In this work, we investigate the possibilities of using LLMs in a resume screening setting via a document retrieval framework that simulates job candidate selection. Using that framework, we then perform a resume audit study to determine whether a selection of Massive Text Embedding (MTE) models are biased in resume screening scenarios. We simulate this for nine occupations, using a collection of over 500 publicly available resumes and 500 job descriptions. We find that the MTEs are biased, significantly favoring White-associated names in 85.1\% of cases and female-associated names in only 11.1\% of cases, with a minority of cases showing no statistically significant differences. Further analyses show that Black males are disadvantaged in up to 100\% of cases, replicating real-world patterns of bias in employment settings, and validate three hypotheses of intersectionality. We also find an impact of document length as well as the corpus frequency of names in the selection of resumes. These findings have implications for widely used AI tools that are automating employment, fairness, and tech policy.