 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBranching Out: Broadening AI Measurement and Evaluation with Measurement Trees
Sep 30, 2025This paper introduces \textit{measurement trees}, a novel class of metrics designed to combine various constructs into an interpretable multi-level representation of a measurand. Unlike conventional metrics that yield single values, vectors, surfaces, or categories, measurement trees produce a hierarchical directed graph in which each node summarizes its children through user-defined aggregation methods. In response to recent calls to expand the scope of AI system evaluation, measurement trees enhance metric transparency and facilitate the integration of heterogeneous evidence, including, e.g., agentic, business, energy-efficiency, sociotechnical, or security signals. We present definitions and examples, demonstrate practical utility through a large-scale measurement exercise, and provide accompanying open-source Python code. By operationalizing a transparent approach to measurement of complex constructs, this work offers a principled foundation for broader and more interpretable AI evaluation.
Pre-trained Speech Processing Models Contain Human-Like Biases that Propagate to Speech Emotion Recognition
Oct 29, 2023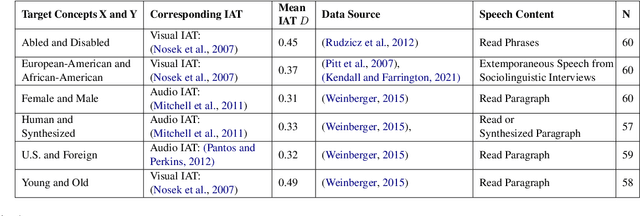
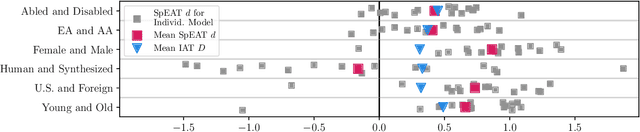
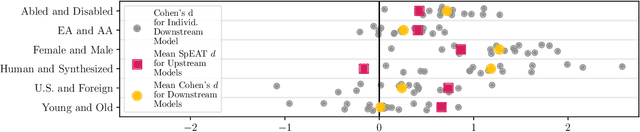
Previous work has established that a person's demographics and speech style affect how well speech processing models perform for them. But where does this bias come from? In this work, we present the Speech Embedding Association Test (SpEAT), a method for detecting bias in one type of model used for many speech tasks: pre-trained models. The SpEAT is inspired by word embedding association tests in natural language processing, which quantify intrinsic bias in a model's representations of different concepts, such as race or valence (something's pleasantness or unpleasantness) and capture the extent to which a model trained on large-scale socio-cultural data has learned human-like biases. Using the SpEAT, we test for six types of bias in 16 English speech models (including 4 models also trained on multilingual data), which come from the wav2vec 2.0, HuBERT, WavLM, and Whisper model families. We find that 14 or more models reveal positive valence (pleasantness) associations with abled people over disabled people, with European-Americans over African-Americans, with females over males, with U.S. accented speakers over non-U.S. accented speakers, and with younger people over older people. Beyond establishing that pre-trained speech models contain these biases, we also show that they can have real world effects. We compare biases found in pre-trained models to biases in downstream models adapted to the task of Speech Emotion Recognition (SER) and find that in 66 of the 96 tests performed (69%), the group that is more associated with positive valence as indicated by the SpEAT also tends to be predicted as speaking with higher valence by the downstream model. Our work provides evidence that, like text and image-based models, pre-trained speech based-models frequently learn human-like biases. Our work also shows that bias found in pre-trained models can propagate to the downstream task of SER.
Extending Explainable Boosting Machines to Scientific Image Data
May 25, 2023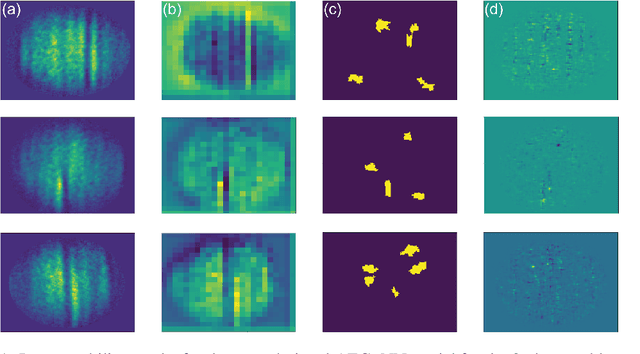
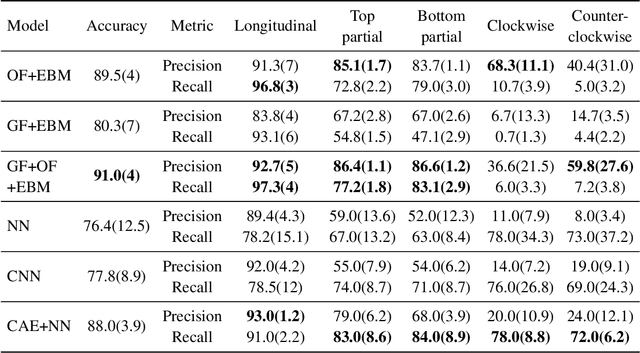
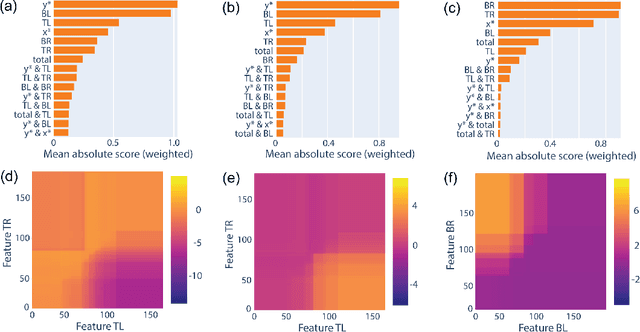
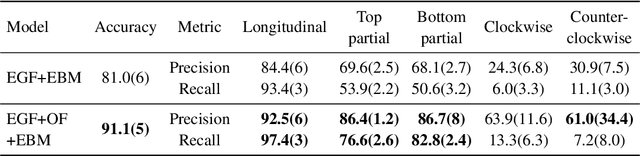
As the deployment of computer vision technology becomes increasingly common in applications of consequence such as medicine or science, the need for explanations of the system output has become a focus of great concern. Unfortunately, many state-of-the-art computer vision models are opaque, making their use challenging from an explanation standpoint, and current approaches to explaining these opaque models have stark limitations and have been the subject of serious criticism. In contrast, Explainable Boosting Machines (EBMs) are a class of models that are easy to interpret and achieve performance on par with the very best-performing models, however, to date EBMs have been limited solely to tabular data. Driven by the pressing need for interpretable models in science, we propose the use of EBMs for scientific image data. Inspired by an important application underpinning the development of quantum technologies, we apply EBMs to cold-atom soliton image data, and, in doing so, demonstrate EBMs for image data for the first time. To tabularize the image data we employ Gabor Wavelet Transform-based techniques that preserve the spatial structure of the data. We show that our approach provides better explanations than other state-of-the-art explainability methods for images.
The 2022 NIST Language Recognition Evaluation
Feb 28, 2023



In 2022, the U.S. National Institute of Standards and Technology (NIST) conducted the latest Language Recognition Evaluation (LRE) in an ongoing series administered by NIST since 1996 to foster research in language recognition and to measure state-of-the-art technology. Similar to previous LREs, LRE22 focused on conversational telephone speech (CTS) and broadcast narrowband speech (BNBS) data. LRE22 also introduced new evaluation features, such as an emphasis on African languages, including low resource languages, and a test set consisting of segments containing between 3s and 35s of speech randomly sampled and extracted from longer recordings. A total of 21 research organizations, forming 16 teams, participated in this 3-month long evaluation and made a total of 65 valid system submissions to be evaluated. This paper presents an overview of LRE22 and an analysis of system performance over different evaluation conditions. The evaluation results suggest that Oromo and Tigrinya are easier to detect while Xhosa and Zulu are more challenging. A greater confusability is seen for some language pairs. When speech duration increased, system performance significantly increased up to a certain duration, and then a diminishing return on system performance is observed afterward.
The 2021 NIST Speaker Recognition Evaluation
Apr 21, 2022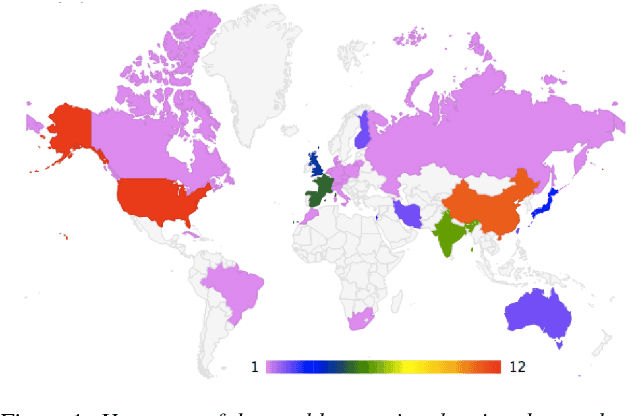
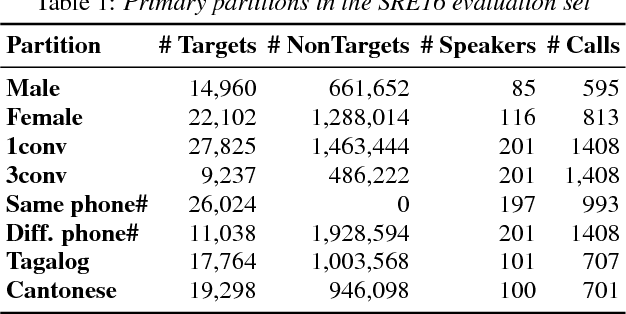
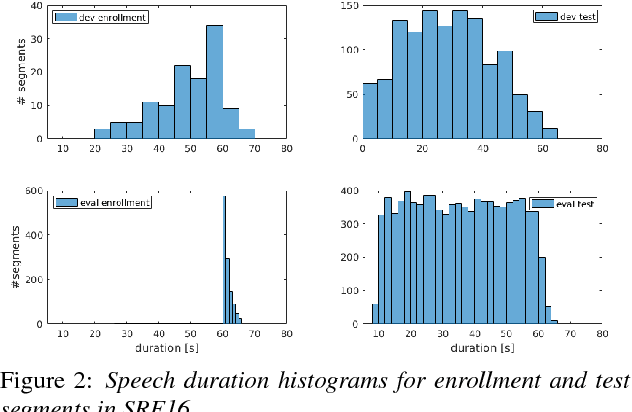
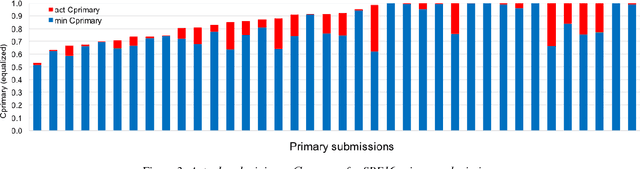
The 2021 Speaker Recognition Evaluation (SRE21) was the latest cycle of the ongoing evaluation series conducted by the U.S. National Institute of Standards and Technology (NIST) since 1996. It was the second large-scale multimodal speaker/person recognition evaluation organized by NIST (the first one being SRE19). Similar to SRE19, it featured two core evaluation tracks, namely audio and audio-visual, as well as an optional visual track. In addition to offering fixed and open training conditions, it also introduced new challenges for the community, thanks to a new multimodal (i.e., audio, video, and selfie images) and multilingual (i.e., with multilingual speakers) corpus, termed WeCanTalk, collected outside North America by the Linguistic Data Consortium (LDC). These challenges included: 1) trials (target and non-target) with enrollment and test segments originating from different domains (i.e., telephony versus video), and 2) trials (target and non-target) with enrollment and test segments spoken in different languages (i.e., cross-lingual trials). This paper presents an overview of SRE21 including the tasks, performance metric, data, evaluation protocol, results and system performance analyses. A total of 23 organizations (forming 15 teams) from academia and industry participated in SRE21 and submitted 158 valid system outputs. Evaluation results indicate: audio-visual fusion produce substantial gains in performance over audio-only or visual-only systems; top performing speaker and face recognition systems exhibited comparable performance under the matched domain conditions present in this evaluation; and, the use of complex neural network architectures (e.g., ResNet) along with angular losses with margin, data augmentation, as well as long duration fine-tuning contributed to notable performance improvements for the audio-only speaker recognition task.
The NIST CTS Speaker Recognition Challenge
Apr 21, 2022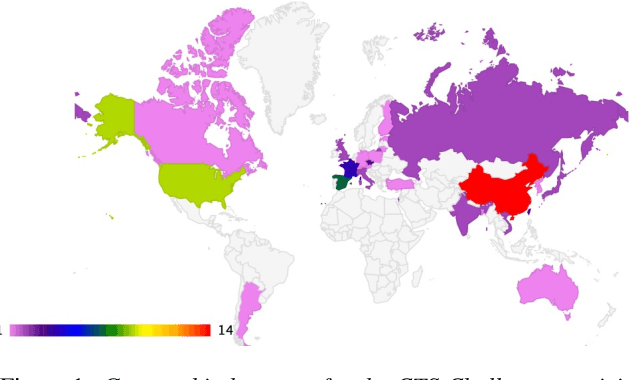
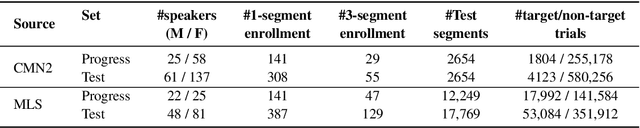
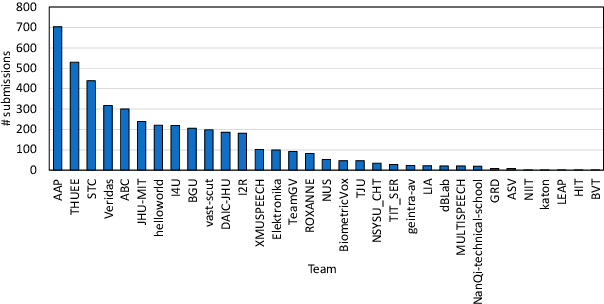
The US National Institute of Standards and Technology (NIST) has been conducting a second iteration of the CTS challenge since August 2020. The current iteration of the CTS Challenge is a leaderboard-style speaker recognition evaluation using telephony data extracted from the unexposed portions of the Call My Net 2 (CMN2) and Multi-Language Speech (MLS) corpora collected by the LDC. The CTS Challenge is currently organized in a similar manner to the SRE19 CTS Challenge, offering only an open training condition using two evaluation subsets, namely Progress and Test. Unlike in the SRE19 Challenge, no training or development set was initially released, and NIST has publicly released the leaderboards on both subsets for the CTS Challenge. Which subset (i.e., Progress or Test) a trial belongs to is unknown to challenge participants, and each system submission needs to contain outputs for all of the trials. The CTS Challenge has also served, and will continue to do so, as a prerequisite for entrance to the regular SREs (such as SRE21). Since August 2020, a total of 53 organizations (forming 33 teams) from academia and industry have participated in the CTS Challenge and submitted more than 4400 valid system outputs. This paper presents an overview of the evaluation and several analyses of system performance for some primary conditions in the CTS Challenge. The CTS Challenge results thus far indicate remarkable improvements in performance due to 1) speaker embeddings extracted using large-scale and complex neural network architectures such as ResNets along with angular margin losses for speaker embedding extraction, 2) extensive data augmentation, 3) the use of large amounts of in-house proprietary data from a large number of labeled speakers, 4) long-duration fine-tuning.
Machine-learning enhanced dark soliton detection in Bose-Einstein condensates
Jan 14, 2021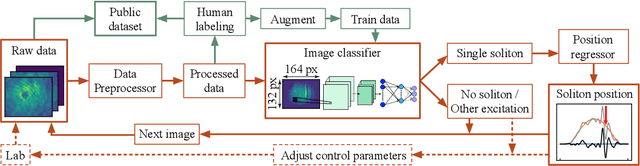

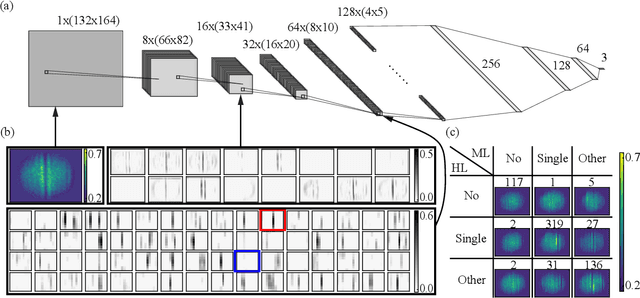

Most data in cold-atom experiments comes from images, the analysis of which is limited by our preconceptions of the patterns that could be present in the data. We focus on the well-defined case of detecting dark solitons -- appearing as local density depletions in a BEC -- using a methodology that is extensible to the general task of pattern recognition in images of cold atoms. Studying soliton dynamics over a wide range of parameters requires the analysis of large datasets, making the existing human-inspection-based methodology a significant bottleneck. Here we describe an automated classification and positioning system for identifying localized excitations in atomic Bose-Einstein condensates (BECs) utilizing deep convolutional neural networks to eliminate the need for human image examination. Furthermore, we openly publish our labeled dataset of dark solitons, the first of its kind, for further machine learning research.