 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Impute or Not: Recommendations for Multibiometric Fusion
Aug 15, 2024Combining match scores from different biometric systems via fusion is a well-established approach to improving recognition accuracy. However, missing scores can degrade performance as well as limit the possible fusion techniques that can be applied. Imputation is a promising technique in multibiometric systems for replacing missing data. In this paper, we evaluate various score imputation approaches on three multimodal biometric score datasets, viz. NIST BSSR1, BIOCOP2008, and MIT LL Trimodal, and investigate the factors which might influence the effectiveness of imputation. Our studies reveal three key observations: (1) Imputation is preferable over not imputing missing scores, even when the fusion rule does not require complete score data. (2) Balancing the classes in the training data is crucial to mitigate negative biases in the imputation technique towards the under-represented class, even if it involves dropping a substantial number of score vectors. (3) Multivariate imputation approaches seem to be beneficial when scores between modalities are correlated, while univariate approaches seem to benefit scenarios where scores between modalities are less correlated.
The 2022 NIST Language Recognition Evaluation
Feb 28, 2023



In 2022, the U.S. National Institute of Standards and Technology (NIST) conducted the latest Language Recognition Evaluation (LRE) in an ongoing series administered by NIST since 1996 to foster research in language recognition and to measure state-of-the-art technology. Similar to previous LREs, LRE22 focused on conversational telephone speech (CTS) and broadcast narrowband speech (BNBS) data. LRE22 also introduced new evaluation features, such as an emphasis on African languages, including low resource languages, and a test set consisting of segments containing between 3s and 35s of speech randomly sampled and extracted from longer recordings. A total of 21 research organizations, forming 16 teams, participated in this 3-month long evaluation and made a total of 65 valid system submissions to be evaluated. This paper presents an overview of LRE22 and an analysis of system performance over different evaluation conditions. The evaluation results suggest that Oromo and Tigrinya are easier to detect while Xhosa and Zulu are more challenging. A greater confusability is seen for some language pairs. When speech duration increased, system performance significantly increased up to a certain duration, and then a diminishing return on system performance is observed afterward.
The 2021 NIST Speaker Recognition Evaluation
Apr 21, 2022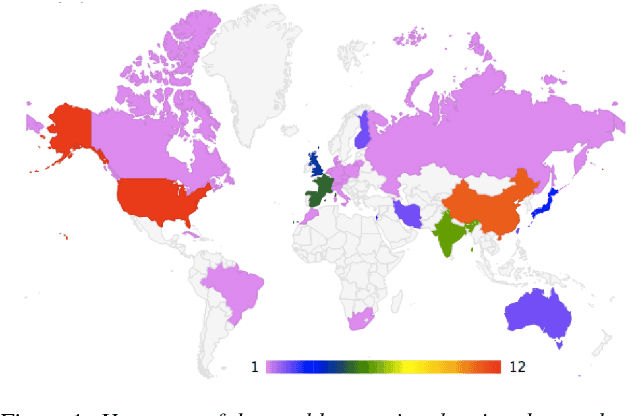
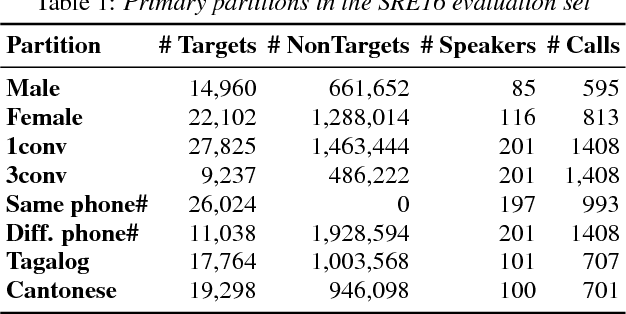
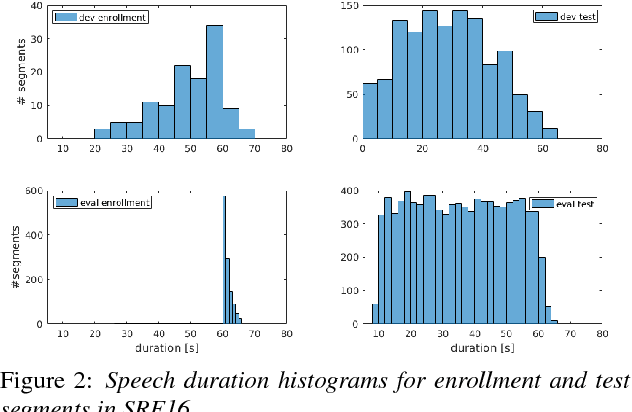
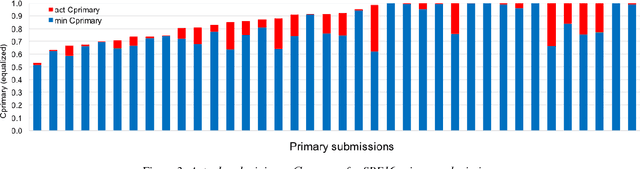
The 2021 Speaker Recognition Evaluation (SRE21) was the latest cycle of the ongoing evaluation series conducted by the U.S. National Institute of Standards and Technology (NIST) since 1996. It was the second large-scale multimodal speaker/person recognition evaluation organized by NIST (the first one being SRE19). Similar to SRE19, it featured two core evaluation tracks, namely audio and audio-visual, as well as an optional visual track. In addition to offering fixed and open training conditions, it also introduced new challenges for the community, thanks to a new multimodal (i.e., audio, video, and selfie images) and multilingual (i.e., with multilingual speakers) corpus, termed WeCanTalk, collected outside North America by the Linguistic Data Consortium (LDC). These challenges included: 1) trials (target and non-target) with enrollment and test segments originating from different domains (i.e., telephony versus video), and 2) trials (target and non-target) with enrollment and test segments spoken in different languages (i.e., cross-lingual trials). This paper presents an overview of SRE21 including the tasks, performance metric, data, evaluation protocol, results and system performance analyses. A total of 23 organizations (forming 15 teams) from academia and industry participated in SRE21 and submitted 158 valid system outputs. Evaluation results indicate: audio-visual fusion produce substantial gains in performance over audio-only or visual-only systems; top performing speaker and face recognition systems exhibited comparable performance under the matched domain conditions present in this evaluation; and, the use of complex neural network architectures (e.g., ResNet) along with angular losses with margin, data augmentation, as well as long duration fine-tuning contributed to notable performance improvements for the audio-only speaker recognition task.
The NIST CTS Speaker Recognition Challenge
Apr 21, 2022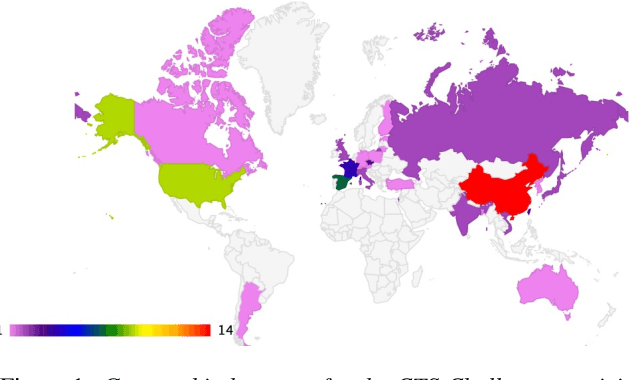
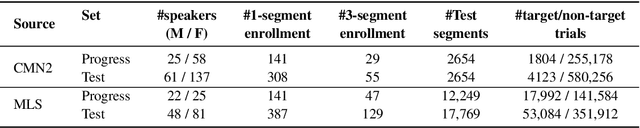
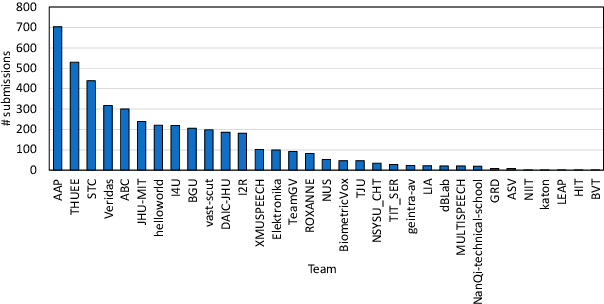
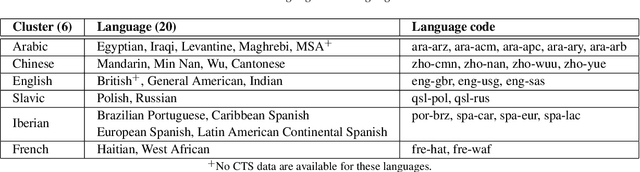
The US National Institute of Standards and Technology (NIST) has been conducting a second iteration of the CTS challenge since August 2020. The current iteration of the CTS Challenge is a leaderboard-style speaker recognition evaluation using telephony data extracted from the unexposed portions of the Call My Net 2 (CMN2) and Multi-Language Speech (MLS) corpora collected by the LDC. The CTS Challenge is currently organized in a similar manner to the SRE19 CTS Challenge, offering only an open training condition using two evaluation subsets, namely Progress and Test. Unlike in the SRE19 Challenge, no training or development set was initially released, and NIST has publicly released the leaderboards on both subsets for the CTS Challenge. Which subset (i.e., Progress or Test) a trial belongs to is unknown to challenge participants, and each system submission needs to contain outputs for all of the trials. The CTS Challenge has also served, and will continue to do so, as a prerequisite for entrance to the regular SREs (such as SRE21). Since August 2020, a total of 53 organizations (forming 33 teams) from academia and industry have participated in the CTS Challenge and submitted more than 4400 valid system outputs. This paper presents an overview of the evaluation and several analyses of system performance for some primary conditions in the CTS Challenge. The CTS Challenge results thus far indicate remarkable improvements in performance due to 1) speaker embeddings extracted using large-scale and complex neural network architectures such as ResNets along with angular margin losses for speaker embedding extraction, 2) extensive data augmentation, 3) the use of large amounts of in-house proprietary data from a large number of labeled speakers, 4) long-duration fine-tuning.