 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Speech Separation via Bottleneck Iterative Network
Jul 09, 2025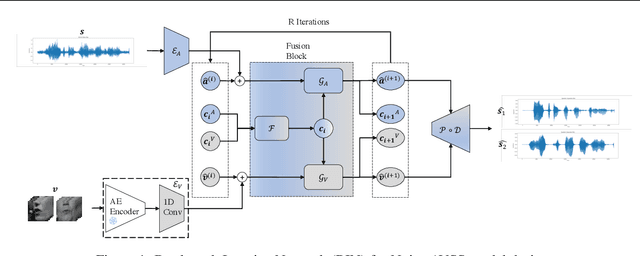
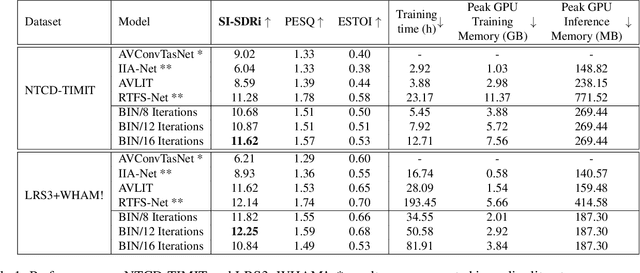
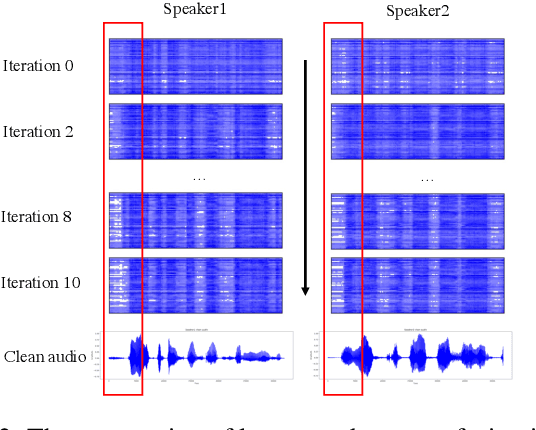
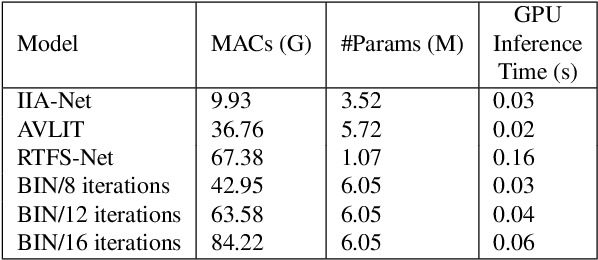
Integration of information from non-auditory cues can significantly improve the performance of speech-separation models. Often such models use deep modality-specific networks to obtain unimodal features, and risk being too costly or lightweight but lacking capacity. In this work, we present an iterative representation refinement approach called Bottleneck Iterative Network (BIN), a technique that repeatedly progresses through a lightweight fusion block, while bottlenecking fusion representations by fusion tokens. This helps improve the capacity of the model, while avoiding major increase in model size and balancing between the model performance and training cost. We test BIN on challenging noisy audio-visual speech separation tasks, and show that our approach consistently outperforms state-of-the-art benchmark models with respect to SI-SDRi on NTCD-TIMIT and LRS3+WHAM! datasets, while simultaneously achieving a reduction of more than 50% in training and GPU inference time across nearly all settings.
SuoiAI: Building a Dataset for Aquatic Invertebrates in Vietnam
Apr 21, 2025
Understanding and monitoring aquatic biodiversity is critical for ecological health and conservation efforts. This paper proposes SuoiAI, an end-to-end pipeline for building a dataset of aquatic invertebrates in Vietnam and employing machine learning (ML) techniques for species classification. We outline the methods for data collection, annotation, and model training, focusing on reducing annotation effort through semi-supervised learning and leveraging state-of-the-art object detection and classification models. Our approach aims to overcome challenges such as data scarcity, fine-grained classification, and deployment in diverse environmental conditions.
Masks and Mimicry: Strategic Obfuscation and Impersonation Attacks on Authorship Verification
Mar 24, 2025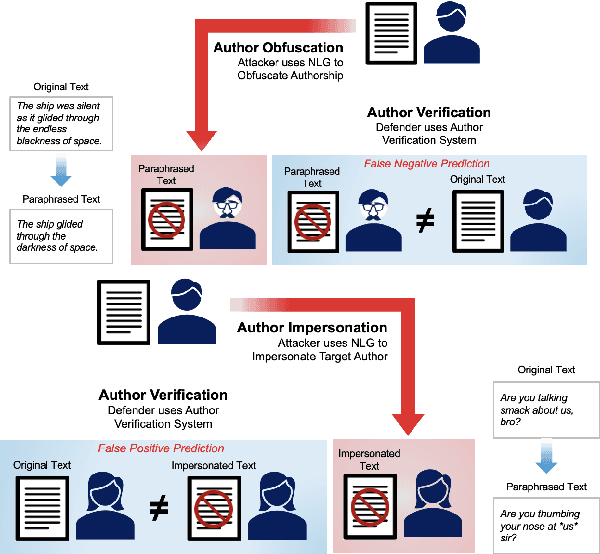

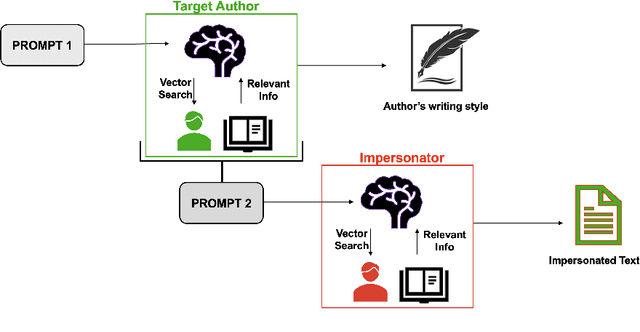
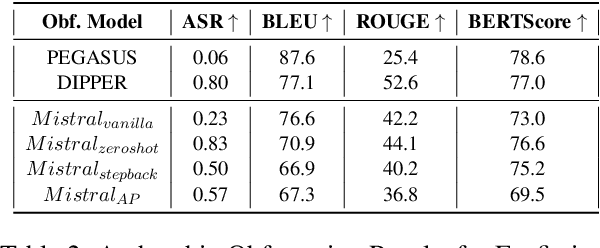
The increasing use of Artificial Intelligence (AI) technologies, such as Large Language Models (LLMs) has led to nontrivial improvements in various tasks, including accurate authorship identification of documents. However, while LLMs improve such defense techniques, they also simultaneously provide a vehicle for malicious actors to launch new attack vectors. To combat this security risk, we evaluate the adversarial robustness of authorship models (specifically an authorship verification model) to potent LLM-based attacks. These attacks include untargeted methods - \textit{authorship obfuscation} and targeted methods - \textit{authorship impersonation}. For both attacks, the objective is to mask or mimic the writing style of an author while preserving the original texts' semantics, respectively. Thus, we perturb an accurate authorship verification model, and achieve maximum attack success rates of 92\% and 78\% for both obfuscation and impersonation attacks, respectively.
A Wearable Device Dataset for Mental Health Assessment Using Laser Doppler Flowmetry and Fluorescence Spectroscopy Sensors
Feb 03, 2025



In this study, we introduce a novel method to predict mental health by building machine learning models for a non-invasive wearable device equipped with Laser Doppler Flowmetry (LDF) and Fluorescence Spectroscopy (FS) sensors. Besides, we present the corresponding dataset to predict mental health, e.g. depression, anxiety, and stress levels via the DAS-21 questionnaire. To our best knowledge, this is the world's largest and the most generalized dataset ever collected for both LDF and FS studies. The device captures cutaneous blood microcirculation parameters, and wavelet analysis of the LDF signal extracts key rhythmic oscillations. The dataset, collected from 132 volunteers aged 18-94 from 19 countries, explores relationships between physiological features, demographics, lifestyle habits, and health conditions. We employed a variety of machine learning methods to classify stress detection, in which LightGBM is identified as the most effective model for stress detection, achieving a ROC AUC of 0.7168 and a PR AUC of 0.8852. In addition, we also incorporated Explainable Artificial Intelligence (XAI) techniques into our analysis to investigate deeper insights into the model's predictions. Our results suggest that females, younger individuals and those with a higher Body Mass Index (BMI) or heart rate have a greater likelihood of experiencing mental health conditions like stress and anxiety. All related code and data are published online: https://github.com/leduckhai/Wearable_LDF-FS.
Adaptive Prompting for Continual Relation Extraction: A Within-Task Variance Perspective
Dec 12, 2024



To address catastrophic forgetting in Continual Relation Extraction (CRE), many current approaches rely on memory buffers to rehearse previously learned knowledge while acquiring new tasks. Recently, prompt-based methods have emerged as potent alternatives to rehearsal-based strategies, demonstrating strong empirical performance. However, upon analyzing existing prompt-based approaches for CRE, we identified several critical limitations, such as inaccurate prompt selection, inadequate mechanisms for mitigating forgetting in shared parameters, and suboptimal handling of cross-task and within-task variances. To overcome these challenges, we draw inspiration from the relationship between prefix-tuning and mixture of experts, proposing a novel approach that employs a prompt pool for each task, capturing variations within each task while enhancing cross-task variances. Furthermore, we incorporate a generative model to consolidate prior knowledge within shared parameters, eliminating the need for explicit data storage. Extensive experiments validate the efficacy of our approach, demonstrating superior performance over state-of-the-art prompt-based and rehearsal-free methods in continual relation extraction.
Backdoor Attack in Prompt-Based Continual Learning
Jun 28, 2024



Prompt-based approaches offer a cutting-edge solution to data privacy issues in continual learning, particularly in scenarios involving multiple data suppliers where long-term storage of private user data is prohibited. Despite delivering state-of-the-art performance, its impressive remembering capability can become a double-edged sword, raising security concerns as it might inadvertently retain poisoned knowledge injected during learning from private user data. Following this insight, in this paper, we expose continual learning to a potential threat: backdoor attack, which drives the model to follow a desired adversarial target whenever a specific trigger is present while still performing normally on clean samples. We highlight three critical challenges in executing backdoor attacks on incremental learners and propose corresponding solutions: (1) \emph{Transferability}: We employ a surrogate dataset and manipulate prompt selection to transfer backdoor knowledge to data from other suppliers; (2) \emph{Resiliency}: We simulate static and dynamic states of the victim to ensure the backdoor trigger remains robust during intense incremental learning processes; and (3) \emph{Authenticity}: We apply binary cross-entropy loss as an anti-cheating factor to prevent the backdoor trigger from devolving into adversarial noise. Extensive experiments across various benchmark datasets and continual learners validate our continual backdoor framework, achieving up to $100\%$ attack success rate, with further ablation studies confirming our contributions' effectiveness.
Mixture of Experts Meets Prompt-Based Continual Learning
May 23, 2024Exploiting the power of pre-trained models, prompt-based approaches stand out compared to other continual learning solutions in effectively preventing catastrophic forgetting, even with very few learnable parameters and without the need for a memory buffer. While existing prompt-based continual learning methods excel in leveraging prompts for state-of-the-art performance, they often lack a theoretical explanation for the effectiveness of prompting. This paper conducts a theoretical analysis to unravel how prompts bestow such advantages in continual learning, thus offering a new perspective on prompt design. We first show that the attention block of pre-trained models like Vision Transformers inherently encodes a special mixture of experts architecture, characterized by linear experts and quadratic gating score functions. This realization drives us to provide a novel view on prefix tuning, reframing it as the addition of new task-specific experts, thereby inspiring the design of a novel gating mechanism termed Non-linear Residual Gates (NoRGa). Through the incorporation of non-linear activation and residual connection, NoRGa enhances continual learning performance while preserving parameter efficiency. The effectiveness of NoRGa is substantiated both theoretically and empirically across diverse benchmarks and pretraining paradigms.
Statistical Advantages of Perturbing Cosine Router in Sparse Mixture of Experts
May 23, 2024



The cosine router in sparse Mixture of Experts (MoE) has recently emerged as an attractive alternative to the conventional linear router. Indeed, the cosine router demonstrates favorable performance in image and language tasks and exhibits better ability to mitigate the representation collapse issue, which often leads to parameter redundancy and limited representation potentials. Despite its empirical success, a comprehensive analysis of the cosine router in sparse MoE has been lacking. Considering the least square estimation of the cosine routing sparse MoE, we demonstrate that due to the intrinsic interaction of the model parameters in the cosine router via some partial differential equations, regardless of the structures of the experts, the estimation rates of experts and model parameters can be as slow as $\mathcal{O}(1/\log^{\tau}(n))$ where $\tau > 0$ is some constant and $n$ is the sample size. Surprisingly, these pessimistic non-polynomial convergence rates can be circumvented by the widely used technique in practice to stabilize the cosine router -- simply adding noises to the $\mathbb{L}_{2}$ norms in the cosine router, which we refer to as \textit{perturbed cosine router}. Under the strongly identifiable settings of the expert functions, we prove that the estimation rates for both the experts and model parameters under the perturbed cosine routing sparse MoE are significantly improved to polynomial rates. Finally, we conduct extensive simulation studies in both synthetic and real data settings to empirically validate our theoretical results.
Causal Reasoning through Two Layers of Cognition for Improving Generalization in Visual Question Answering
Oct 09, 2023Generalization in Visual Question Answering (VQA) requires models to answer questions about images with contexts beyond the training distribution. Existing attempts primarily refine unimodal aspects, overlooking enhancements in multimodal aspects. Besides, diverse interpretations of the input lead to various modes of answer generation, highlighting the role of causal reasoning between interpreting and answering steps in VQA. Through this lens, we propose Cognitive pathways VQA (CopVQA) improving the multimodal predictions by emphasizing causal reasoning factors. CopVQA first operates a pool of pathways that capture diverse causal reasoning flows through interpreting and answering stages. Mirroring human cognition, we decompose the responsibility of each stage into distinct experts and a cognition-enabled component (CC). The two CCs strategically execute one expert for each stage at a time. Finally, we prioritize answer predictions governed by pathways involving both CCs while disregarding answers produced by either CC, thereby emphasizing causal reasoning and supporting generalization. Our experiments on real-life and medical data consistently verify that CopVQA improves VQA performance and generalization across baselines and domains. Notably, CopVQA achieves a new state-of-the-art (SOTA) on PathVQA dataset and comparable accuracy to the current SOTA on VQA-CPv2, VQAv2, and VQA RAD, with one-fourth of the model size.
Causal Inference in Gene Regulatory Networks with GFlowNet: Towards Scalability in Large Systems
Oct 05, 2023


Understanding causal relationships within Gene Regulatory Networks (GRNs) is essential for unraveling the gene interactions in cellular processes. However, causal discovery in GRNs is a challenging problem for multiple reasons including the existence of cyclic feedback loops and uncertainty that yields diverse possible causal structures. Previous works in this area either ignore cyclic dynamics (assume acyclic structure) or struggle with scalability. We introduce Swift-DynGFN as a novel framework that enhances causal structure learning in GRNs while addressing scalability concerns. Specifically, Swift-DynGFN exploits gene-wise independence to boost parallelization and to lower computational cost. Experiments on real single-cell RNA velocity and synthetic GRN datasets showcase the advancement in learning causal structure in GRNs and scalability in larger systems.