 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating LLM Hallucinations with Knowledge Graphs: A Case Study
Apr 16, 2025High-stakes domains like cyber operations need responsible and trustworthy AI methods. While large language models (LLMs) are becoming increasingly popular in these domains, they still suffer from hallucinations. This research paper provides learning outcomes from a case study with LinkQ, an open-source natural language interface that was developed to combat hallucinations by forcing an LLM to query a knowledge graph (KG) for ground-truth data during question-answering (QA). We conduct a quantitative evaluation of LinkQ using a well-known KGQA dataset, showing that the system outperforms GPT-4 but still struggles with certain question categories - suggesting that alternative query construction strategies will need to be investigated in future LLM querying systems. We discuss a qualitative study of LinkQ with two domain experts using a real-world cybersecurity KG, outlining these experts' feedback, suggestions, perceived limitations, and future opportunities for systems like LinkQ.
Don't Just Translate, Agitate: Using Large Language Models as Devil's Advocates for AI Explanations
Apr 16, 2025This position paper highlights a growing trend in Explainable AI (XAI) research where Large Language Models (LLMs) are used to translate outputs from explainability techniques, like feature-attribution weights, into a natural language explanation. While this approach may improve accessibility or readability for users, recent findings suggest that translating into human-like explanations does not necessarily enhance user understanding and may instead lead to overreliance on AI systems. When LLMs summarize XAI outputs without surfacing model limitations, uncertainties, or inconsistencies, they risk reinforcing the illusion of interpretability rather than fostering meaningful transparency. We argue that - instead of merely translating XAI outputs - LLMs should serve as constructive agitators, or devil's advocates, whose role is to actively interrogate AI explanations by presenting alternative interpretations, potential biases, training data limitations, and cases where the model's reasoning may break down. In this role, LLMs can facilitate users in engaging critically with AI systems and generated explanations, with the potential to reduce overreliance caused by misinterpreted or specious explanations.
Masks and Mimicry: Strategic Obfuscation and Impersonation Attacks on Authorship Verification
Mar 24, 2025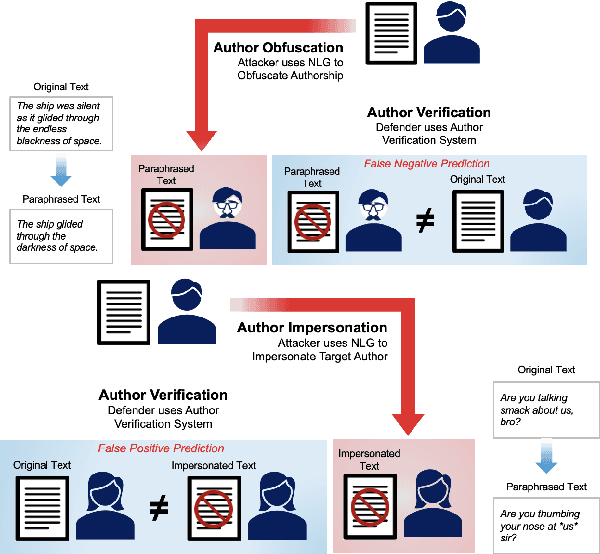

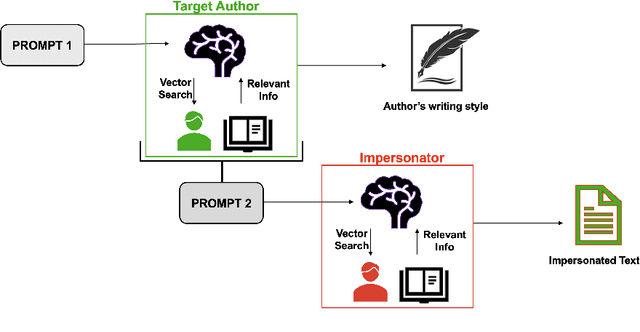
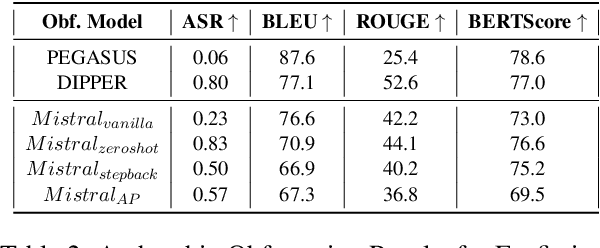
The increasing use of Artificial Intelligence (AI) technologies, such as Large Language Models (LLMs) has led to nontrivial improvements in various tasks, including accurate authorship identification of documents. However, while LLMs improve such defense techniques, they also simultaneously provide a vehicle for malicious actors to launch new attack vectors. To combat this security risk, we evaluate the adversarial robustness of authorship models (specifically an authorship verification model) to potent LLM-based attacks. These attacks include untargeted methods - \textit{authorship obfuscation} and targeted methods - \textit{authorship impersonation}. For both attacks, the objective is to mask or mimic the writing style of an author while preserving the original texts' semantics, respectively. Thus, we perturb an accurate authorship verification model, and achieve maximum attack success rates of 92\% and 78\% for both obfuscation and impersonation attacks, respectively.
More Questions than Answers? Lessons from Integrating Explainable AI into a Cyber-AI Tool
Aug 08, 2024

We share observations and challenges from an ongoing effort to implement Explainable AI (XAI) in a domain-specific workflow for cybersecurity analysts. Specifically, we briefly describe a preliminary case study on the use of XAI for source code classification, where accurate assessment and timeliness are paramount. We find that the outputs of state-of-the-art saliency explanation techniques (e.g., SHAP or LIME) are lost in translation when interpreted by people with little AI expertise, despite these techniques being marketed for non-technical users. Moreover, we find that popular XAI techniques offer fewer insights for real-time human-AI workflows when they are post hoc and too localized in their explanations. Instead, we observe that cyber analysts need higher-level, easy-to-digest explanations that can offer as little disruption as possible to their workflows. We outline unaddressed gaps in practical and effective XAI, then touch on how emerging technologies like Large Language Models (LLMs) could mitigate these existing obstacles.
A Framework for Unsupervised Classificiation and Data Mining of Tweets about Cyber Vulnerabilities
Apr 23, 2021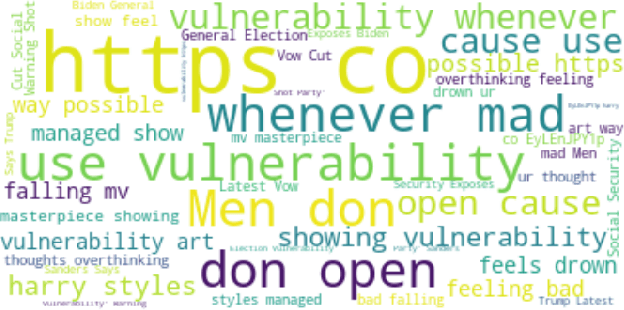


Many cyber network defense tools rely on the National Vulnerability Database (NVD) to provide timely information on known vulnerabilities that exist within systems on a given network. However, recent studies have indicated that the NVD is not always up to date, with known vulnerabilities being discussed publicly on social media platforms, like Twitter and Reddit, months before they are published to the NVD. To that end, we present a framework for unsupervised classification to filter tweets for relevance to cyber security. We consider and evaluate two unsupervised machine learning techniques for inclusion in our framework, and show that zero-shot classification using a Bidirectional and Auto-Regressive Transformers (BART) model outperforms the other technique with 83.52% accuracy and a F1 score of 83.88, allowing for accurate filtering of tweets without human intervention or labelled data for training. Additionally, we discuss different insights that can be derived from these cyber-relevant tweets, such as trending topics of tweets and the counts of Twitter mentions for Common Vulnerabilities and Exposures (CVEs), that can be used in an alert or report to augment current NVD-based risk assessment tools.