 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Dense Retrieval with Embeddings from Relevance Feedback
Oct 28, 2024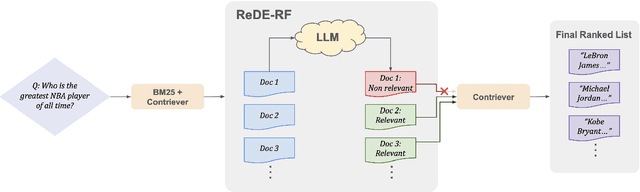
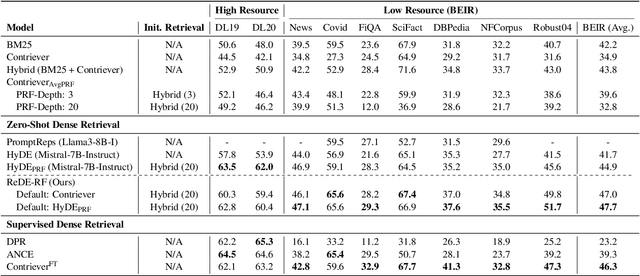

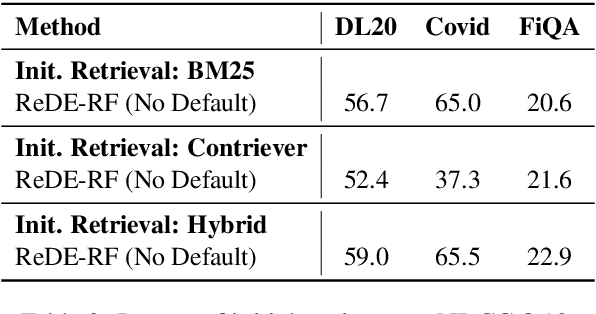
Building effective dense retrieval systems remains difficult when relevance supervision is not available. Recent work has looked to overcome this challenge by using a Large Language Model (LLM) to generate hypothetical documents that can be used to find the closest real document. However, this approach relies solely on the LLM to have domain-specific knowledge relevant to the query, which may not be practical. Furthermore, generating hypothetical documents can be inefficient as it requires the LLM to generate a large number of tokens for each query. To address these challenges, we introduce Real Document Embeddings from Relevance Feedback (ReDE-RF). Inspired by relevance feedback, ReDE-RF proposes to re-frame hypothetical document generation as a relevance estimation task, using an LLM to select which documents should be used for nearest neighbor search. Through this re-framing, the LLM no longer needs domain-specific knowledge but only needs to judge what is relevant. Additionally, relevance estimation only requires the LLM to output a single token, thereby improving search latency. Our experiments show that ReDE-RF consistently surpasses state-of-the-art zero-shot dense retrieval methods across a wide range of low-resource retrieval datasets while also making significant improvements in latency per-query.
Antibody Representation Learning for Drug Discovery
Oct 05, 2022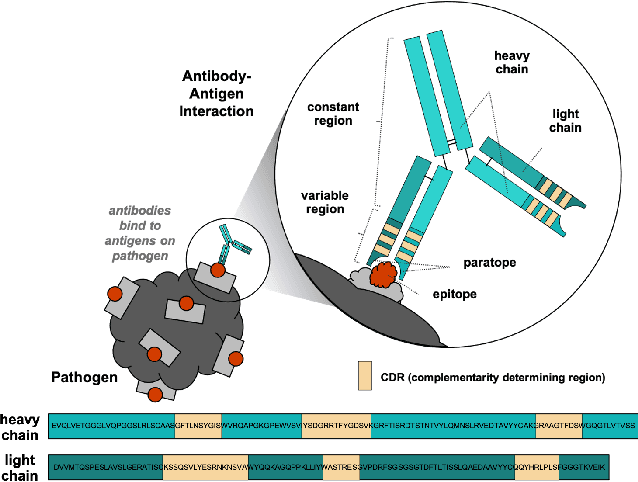
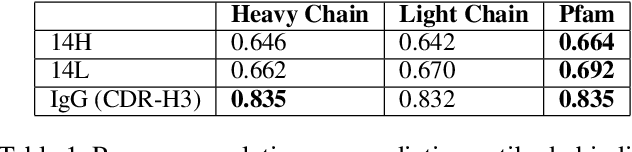
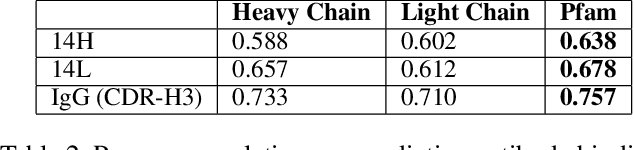
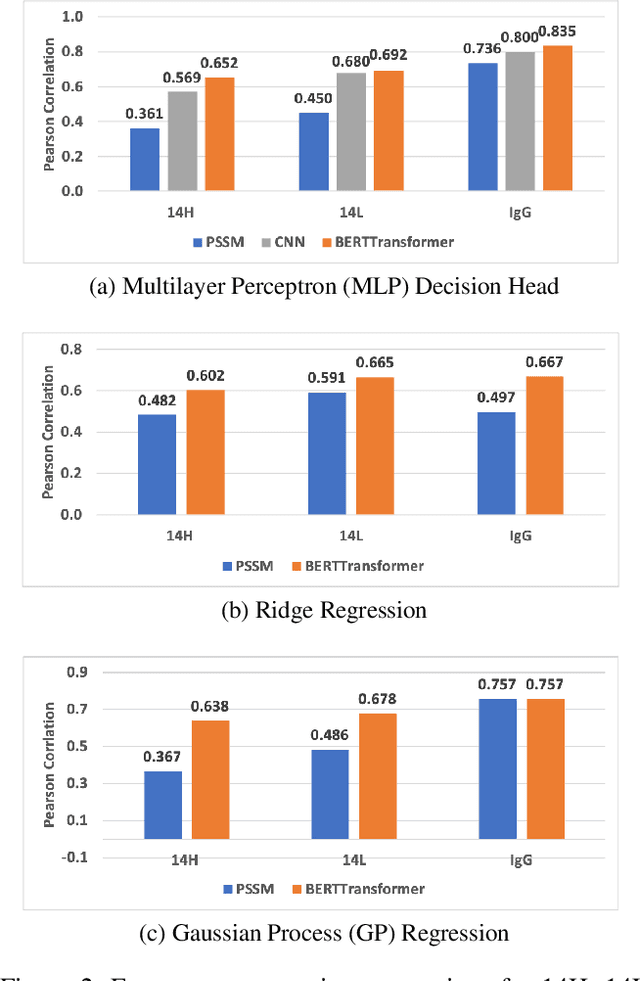
Therapeutic antibody development has become an increasingly popular approach for drug development. To date, antibody therapeutics are largely developed using large scale experimental screens of antibody libraries containing hundreds of millions of antibody sequences. The high cost and difficulty of developing therapeutic antibodies create a pressing need for computational methods to predict antibody properties and create bespoke designs. However, the relationship between antibody sequence and activity is a complex physical process and traditional iterative design approaches rely on large scale assays and random mutagenesis. Deep learning methods have emerged as a promising way to learn antibody property predictors, but predicting antibody properties and target-specific activities depends critically on the choice of antibody representations and data linking sequences to properties is often limited. Existing works have not yet investigated the value, limitations and opportunities of these methods in application to antibody-based drug discovery. In this paper, we present results on a novel SARS-CoV-2 antibody binding dataset and an additional benchmark dataset. We compare three classes of models: conventional statistical sequence models, supervised learning on each dataset independently, and fine-tuning an antibody specific pre-trained language model. Experimental results suggest that self-supervised pretraining of feature representation consistently offers significant improvement in over previous approaches. We also investigate the impact of data size on the model performance, and discuss challenges and opportunities that the machine learning community can address to advance in silico engineering and design of therapeutic antibodies.
Developing a Series of AI Challenges for the United States Department of the Air Force
Jul 14, 2022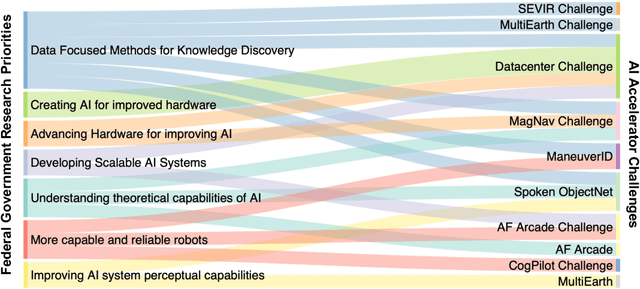

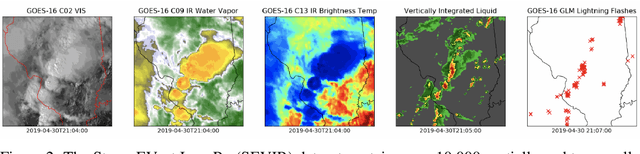
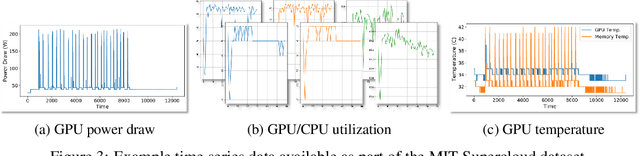
Through a series of federal initiatives and orders, the U.S. Government has been making a concerted effort to ensure American leadership in AI. These broad strategy documents have influenced organizations such as the United States Department of the Air Force (DAF). The DAF-MIT AI Accelerator is an initiative between the DAF and MIT to bridge the gap between AI researchers and DAF mission requirements. Several projects supported by the DAF-MIT AI Accelerator are developing public challenge problems that address numerous Federal AI research priorities. These challenges target priorities by making large, AI-ready datasets publicly available, incentivizing open-source solutions, and creating a demand signal for dual use technologies that can stimulate further research. In this article, we describe these public challenges being developed and how their application contributes to scientific advances.
A Framework for Unsupervised Classificiation and Data Mining of Tweets about Cyber Vulnerabilities
Apr 23, 2021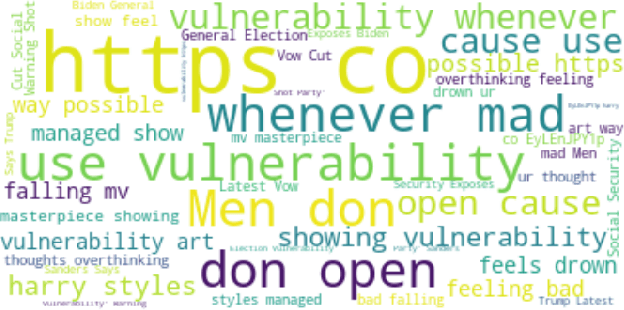


Many cyber network defense tools rely on the National Vulnerability Database (NVD) to provide timely information on known vulnerabilities that exist within systems on a given network. However, recent studies have indicated that the NVD is not always up to date, with known vulnerabilities being discussed publicly on social media platforms, like Twitter and Reddit, months before they are published to the NVD. To that end, we present a framework for unsupervised classification to filter tweets for relevance to cyber security. We consider and evaluate two unsupervised machine learning techniques for inclusion in our framework, and show that zero-shot classification using a Bidirectional and Auto-Regressive Transformers (BART) model outperforms the other technique with 83.52% accuracy and a F1 score of 83.88, allowing for accurate filtering of tweets without human intervention or labelled data for training. Additionally, we discuss different insights that can be derived from these cyber-relevant tweets, such as trending topics of tweets and the counts of Twitter mentions for Common Vulnerabilities and Exposures (CVEs), that can be used in an alert or report to augment current NVD-based risk assessment tools.