 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntibody Representation Learning for Drug Discovery
Oct 05, 2022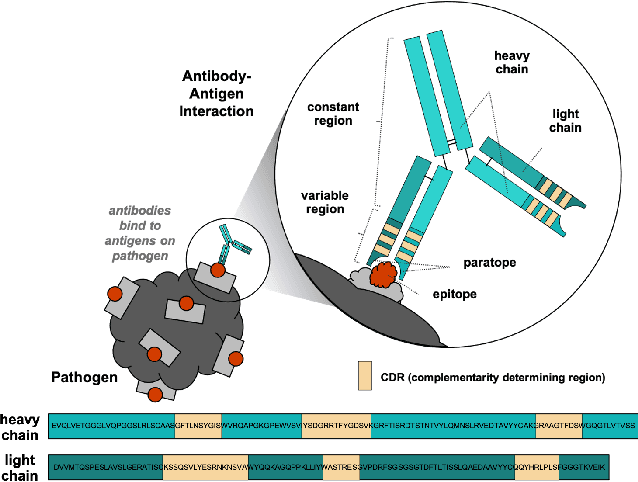
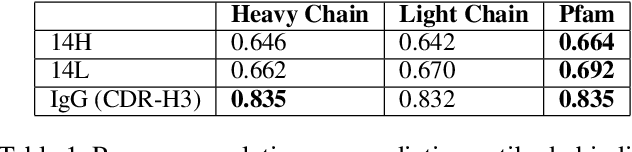
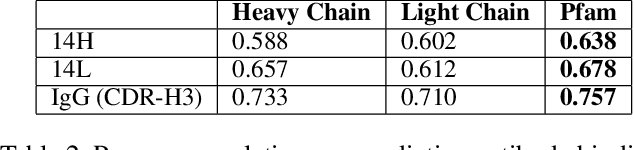
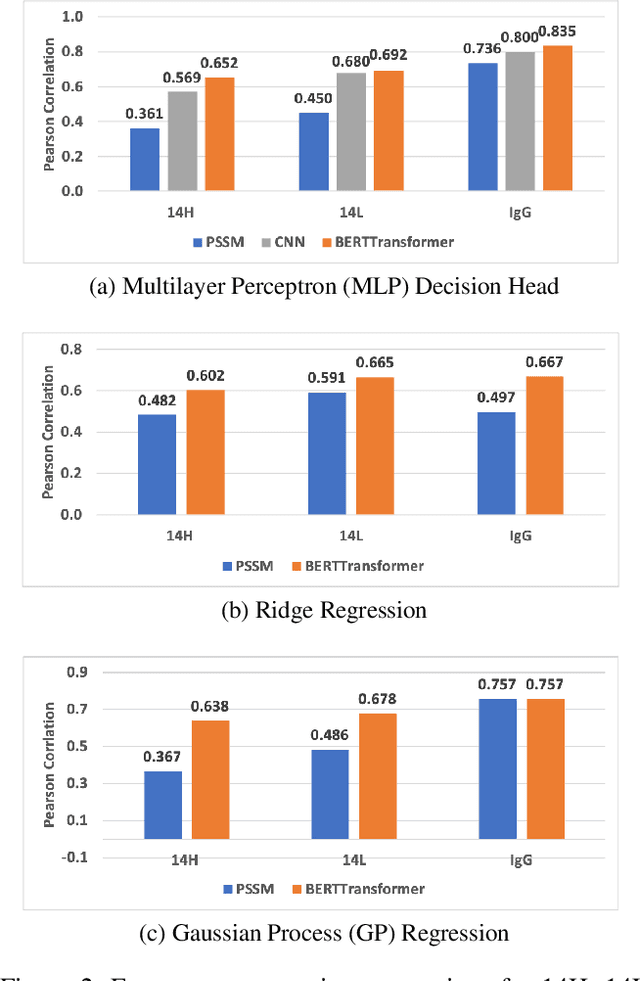
Therapeutic antibody development has become an increasingly popular approach for drug development. To date, antibody therapeutics are largely developed using large scale experimental screens of antibody libraries containing hundreds of millions of antibody sequences. The high cost and difficulty of developing therapeutic antibodies create a pressing need for computational methods to predict antibody properties and create bespoke designs. However, the relationship between antibody sequence and activity is a complex physical process and traditional iterative design approaches rely on large scale assays and random mutagenesis. Deep learning methods have emerged as a promising way to learn antibody property predictors, but predicting antibody properties and target-specific activities depends critically on the choice of antibody representations and data linking sequences to properties is often limited. Existing works have not yet investigated the value, limitations and opportunities of these methods in application to antibody-based drug discovery. In this paper, we present results on a novel SARS-CoV-2 antibody binding dataset and an additional benchmark dataset. We compare three classes of models: conventional statistical sequence models, supervised learning on each dataset independently, and fine-tuning an antibody specific pre-trained language model. Experimental results suggest that self-supervised pretraining of feature representation consistently offers significant improvement in over previous approaches. We also investigate the impact of data size on the model performance, and discuss challenges and opportunities that the machine learning community can address to advance in silico engineering and design of therapeutic antibodies.