 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudy on LLMs for Promptagator-Style Dense Retriever Training
Oct 02, 2025Promptagator demonstrated that Large Language Models (LLMs) with few-shot prompts can be used as task-specific query generators for fine-tuning domain-specialized dense retrieval models. However, the original Promptagator approach relied on proprietary and large-scale LLMs which users may not have access to or may be prohibited from using with sensitive data. In this work, we study the impact of open-source LLMs at accessible scales ($\leq$14B parameters) as an alternative. Our results demonstrate that open-source LLMs as small as 3B parameters can serve as effective Promptagator-style query generators. We hope our work will inform practitioners with reliable alternatives for synthetic data generation and give insights to maximize fine-tuning results for domain-specific applications.
Don't "Overthink" Passage Reranking: Is Reasoning Truly Necessary?
May 22, 2025With the growing success of reasoning models across complex natural language tasks, researchers in the Information Retrieval (IR) community have begun exploring how similar reasoning capabilities can be integrated into passage rerankers built on Large Language Models (LLMs). These methods typically employ an LLM to produce an explicit, step-by-step reasoning process before arriving at a final relevance prediction. But, does reasoning actually improve reranking accuracy? In this paper, we dive deeper into this question, studying the impact of the reasoning process by comparing reasoning-based pointwise rerankers (ReasonRR) to standard, non-reasoning pointwise rerankers (StandardRR) under identical training conditions, and observe that StandardRR generally outperforms ReasonRR. Building on this observation, we then study the importance of reasoning to ReasonRR by disabling its reasoning process (ReasonRR-NoReason), and find that ReasonRR-NoReason is surprisingly more effective than ReasonRR. Examining the cause of this result, our findings reveal that reasoning-based rerankers are limited by the LLM's reasoning process, which pushes it toward polarized relevance scores and thus fails to consider the partial relevance of passages, a key factor for the accuracy of pointwise rerankers.
Zero-Shot Dense Retrieval with Embeddings from Relevance Feedback
Oct 28, 2024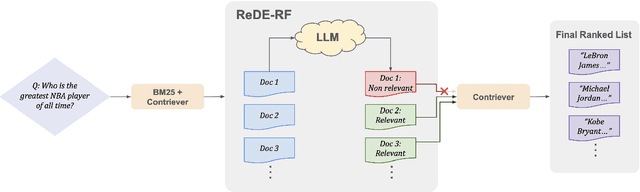
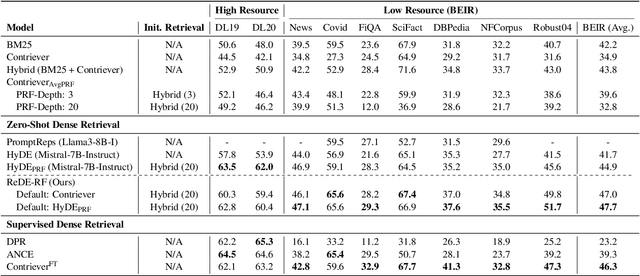

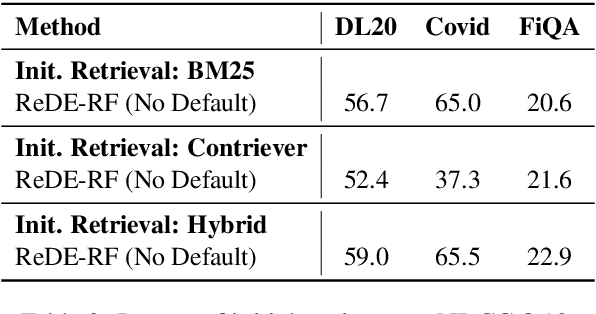
Building effective dense retrieval systems remains difficult when relevance supervision is not available. Recent work has looked to overcome this challenge by using a Large Language Model (LLM) to generate hypothetical documents that can be used to find the closest real document. However, this approach relies solely on the LLM to have domain-specific knowledge relevant to the query, which may not be practical. Furthermore, generating hypothetical documents can be inefficient as it requires the LLM to generate a large number of tokens for each query. To address these challenges, we introduce Real Document Embeddings from Relevance Feedback (ReDE-RF). Inspired by relevance feedback, ReDE-RF proposes to re-frame hypothetical document generation as a relevance estimation task, using an LLM to select which documents should be used for nearest neighbor search. Through this re-framing, the LLM no longer needs domain-specific knowledge but only needs to judge what is relevant. Additionally, relevance estimation only requires the LLM to output a single token, thereby improving search latency. Our experiments show that ReDE-RF consistently surpasses state-of-the-art zero-shot dense retrieval methods across a wide range of low-resource retrieval datasets while also making significant improvements in latency per-query.