 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring and Mitigating Hallucinations in Vision-Language Dataset Generation for Remote Sensing
Jan 24, 2025



Vision language models have achieved impressive results across various fields. However, adoption in remote sensing remains limited, largely due to the scarcity of paired image-text data. To bridge this gap, synthetic caption generation has gained interest, traditionally relying on rule-based methods that use metadata or bounding boxes. While these approaches provide some description, they often lack the depth needed to capture complex wide-area scenes. Large language models (LLMs) offer a promising alternative for generating more descriptive captions, yet they can produce generic outputs and are prone to hallucination. In this paper, we propose a new method to enhance vision-language datasets for remote sensing by integrating maps as external data sources, enabling the generation of detailed, context-rich captions. Additionally, we present methods to measure and mitigate hallucinations in LLM-generated text. We introduce fMoW-mm, a multimodal dataset incorporating satellite imagery, maps, metadata, and text annotations. We demonstrate its effectiveness for automatic target recognition in few-shot settings, achieving superior performance compared to other vision-language remote sensing datasets.
Bidirectional Captioning for Clinically Accurate and Interpretable Models
Oct 30, 2023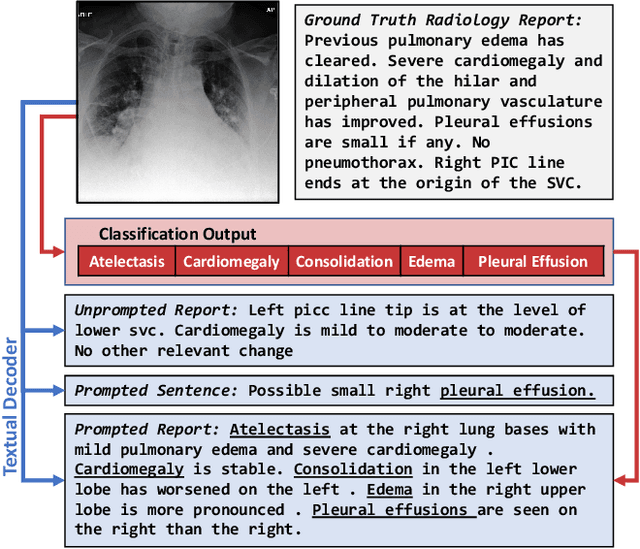
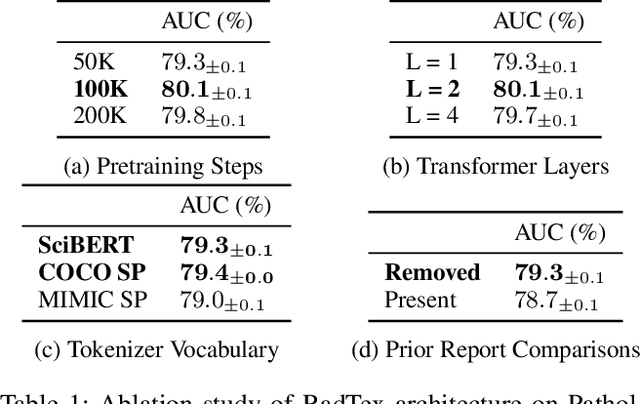
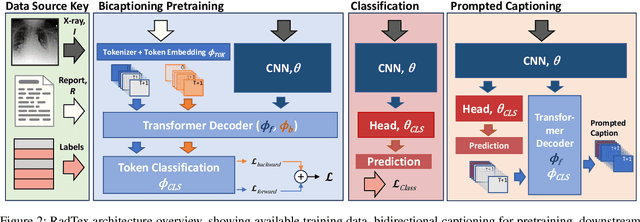
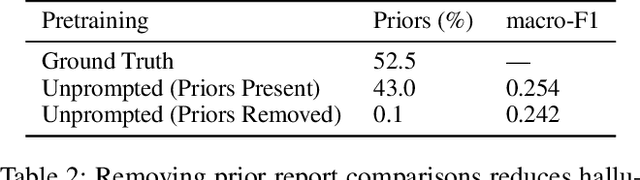
Vision-language pretraining has been shown to produce high-quality visual encoders which transfer efficiently to downstream computer vision tasks. While generative language models have gained widespread attention, image captioning has thus far been mostly overlooked as a form of cross-modal pretraining in favor of contrastive learning, especially in medical image analysis. In this paper, we experiment with bidirectional captioning of radiology reports as a form of pretraining and compare the quality and utility of learned embeddings with those from contrastive pretraining methods. We optimize a CNN encoder, transformer decoder architecture named RadTex for the radiology domain. Results show that not only does captioning pretraining yield visual encoders that are competitive with contrastive pretraining (CheXpert competition multi-label AUC of 89.4%), but also that our transformer decoder is capable of generating clinically relevant reports (captioning macro-F1 score of 0.349 using CheXpert labeler) and responding to prompts with targeted, interactive outputs.
MultiEarth 2023 -- Multimodal Learning for Earth and Environment Workshop and Challenge
Jun 07, 2023

The Multimodal Learning for Earth and Environment Workshop (MultiEarth 2023) is the second annual CVPR workshop aimed at the monitoring and analysis of the health of Earth ecosystems by leveraging the vast amount of remote sensing data that is continuously being collected. The primary objective of this workshop is to bring together the Earth and environmental science communities as well as the multimodal representation learning communities to explore new ways of harnessing technological advancements in support of environmental monitoring. The MultiEarth Workshop also seeks to provide a common benchmark for processing multimodal remote sensing information by organizing public challenges focused on monitoring the Amazon rainforest. These challenges include estimating deforestation, detecting forest fires, translating synthetic aperture radar (SAR) images to the visible domain, and projecting environmental trends. This paper presents the challenge guidelines, datasets, and evaluation metrics. Our challenge website is available at https://sites.google.com/view/rainforest-challenge/multiearth-2023.
RadTex: Learning Efficient Radiograph Representations from Text Reports
Aug 05, 2022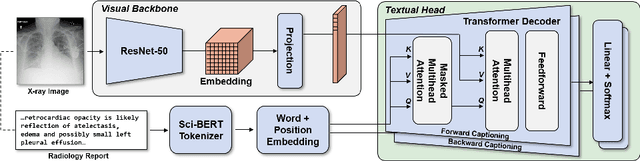
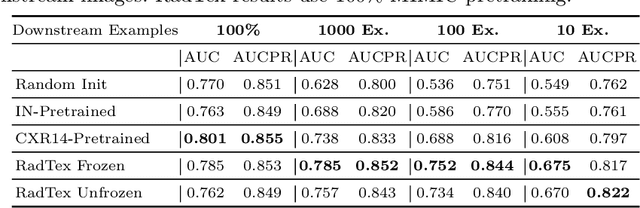
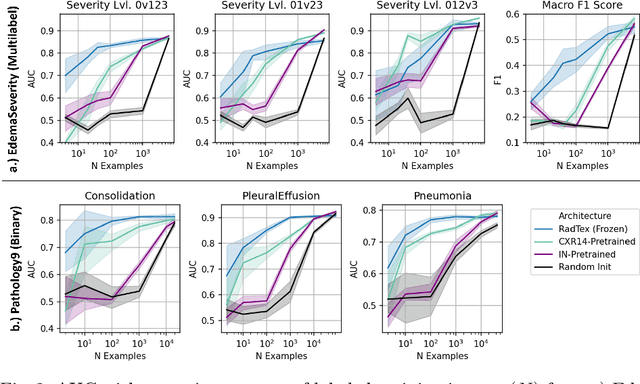
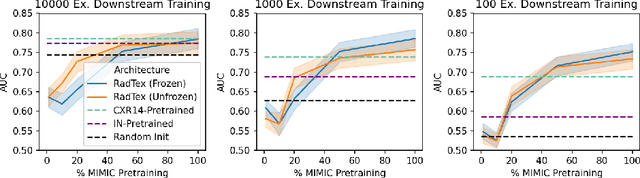
Automated analysis of chest radiography using deep learning has tremendous potential to enhance the clinical diagnosis of diseases in patients. However, deep learning models typically require large amounts of annotated data to achieve high performance -- often an obstacle to medical domain adaptation. In this paper, we build a data-efficient learning framework that utilizes radiology reports to improve medical image classification performance with limited labeled data (fewer than 1000 examples). Specifically, we examine image-captioning pretraining to learn high-quality medical image representations that train on fewer examples. Following joint pretraining of a convolutional encoder and transformer decoder, we transfer the learned encoder to various classification tasks. Averaged over 9 pathologies, we find that our model achieves higher classification performance than ImageNet-supervised and in-domain supervised pretraining when labeled training data is limited.
SAR-to-EO Image Translation with Multi-Conditional Adversarial Networks
Jul 26, 2022



This paper explores the use of multi-conditional adversarial networks for SAR-to-EO image translation. Previous methods condition adversarial networks only on the input SAR. We show that incorporating multiple complementary modalities such as Google maps and IR can further improve SAR-to-EO image translation especially on preserving sharp edges of manmade objects. We demonstrate effectiveness of our approach on a diverse set of datasets including SEN12MS, DFC2020, and SpaceNet6. Our experimental results suggest that additional information provided by complementary modalities improves the performance of SAR-to-EO image translation compared to the models trained on paired SAR and EO data only. To best of our knowledge, our approach is the first to leverage multiple modalities for improving SAR-to-EO image translation performance.
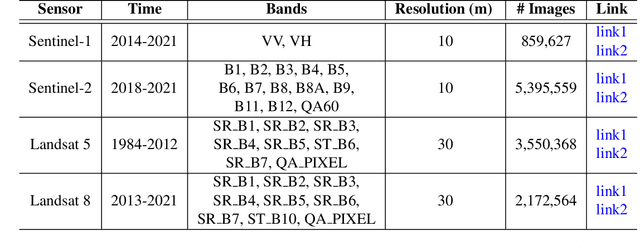
Developing a Series of AI Challenges for the United States Department of the Air Force
Jul 14, 2022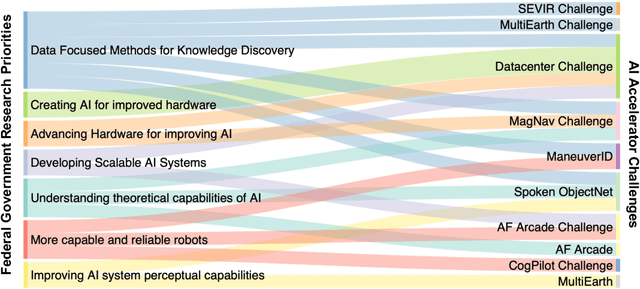

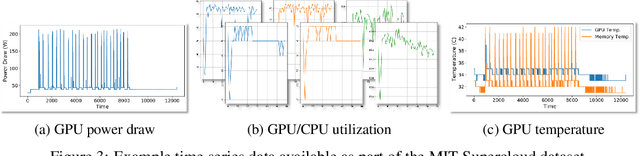
Through a series of federal initiatives and orders, the U.S. Government has been making a concerted effort to ensure American leadership in AI. These broad strategy documents have influenced organizations such as the United States Department of the Air Force (DAF). The DAF-MIT AI Accelerator is an initiative between the DAF and MIT to bridge the gap between AI researchers and DAF mission requirements. Several projects supported by the DAF-MIT AI Accelerator are developing public challenge problems that address numerous Federal AI research priorities. These challenges target priorities by making large, AI-ready datasets publicly available, incentivizing open-source solutions, and creating a demand signal for dual use technologies that can stimulate further research. In this article, we describe these public challenges being developed and how their application contributes to scientific advances.
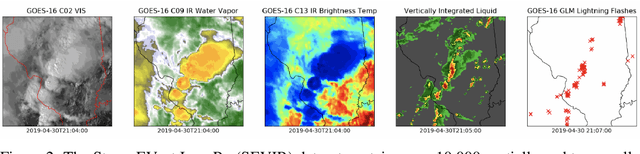
MultiEarth 2022 -- Multimodal Learning for Earth and Environment Workshop and Challenge
Apr 27, 2022


The Multimodal Learning for Earth and Environment Challenge (MultiEarth 2022) will be the first competition aimed at the monitoring and analysis of deforestation in the Amazon rainforest at any time and in any weather conditions. The goal of the Challenge is to provide a common benchmark for multimodal information processing and to bring together the earth and environmental science communities as well as multimodal representation learning communities to compare the relative merits of the various multimodal learning methods to deforestation estimation under well-defined and strictly comparable conditions. MultiEarth 2022 will have three sub-challenges: 1) matrix completion, 2) deforestation estimation, and 3) image-to-image translation. This paper presents the challenge guidelines, datasets, and evaluation metrics for the three sub-challenges. Our challenge website is available at https://sites.google.com/view/rainforest-challenge.
Multimodal Representation Learning via Maximization of Local Mutual Information
Mar 08, 2021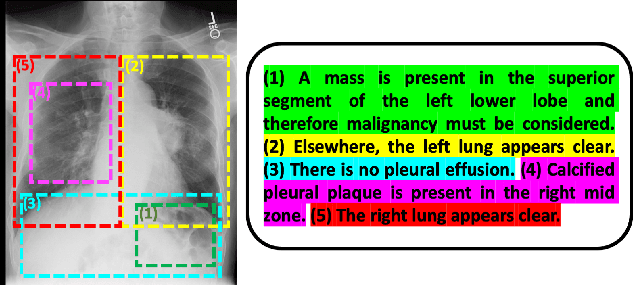
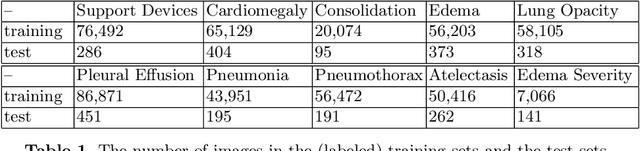
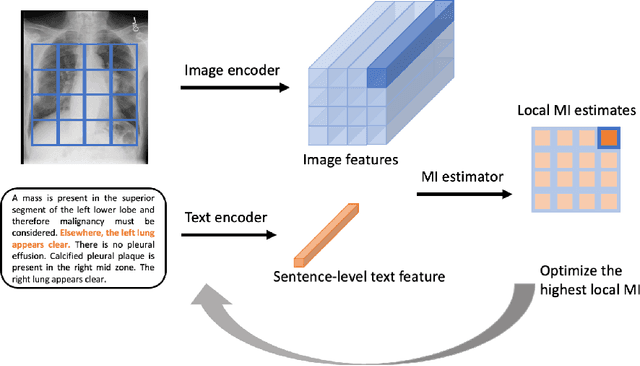
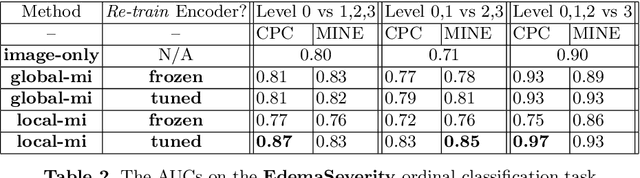
We propose and demonstrate a representation learning approach by maximizing the mutual information between local features of images and text. The goal of this approach is to learn useful image representations by taking advantage of the rich information contained in the free text that describes the findings in the image. Our method learns image and text encoders by encouraging the resulting representations to exhibit high local mutual information. We make use of recent advances in mutual information estimation with neural network discriminators. We argue that, typically, the sum of local mutual information is a lower bound on the global mutual information. Our experimental results in the downstream image classification tasks demonstrate the advantages of using local features for image-text representation learning.
Adversarial Learning of Semantic Relevance in Text to Image Synthesis
Dec 12, 2018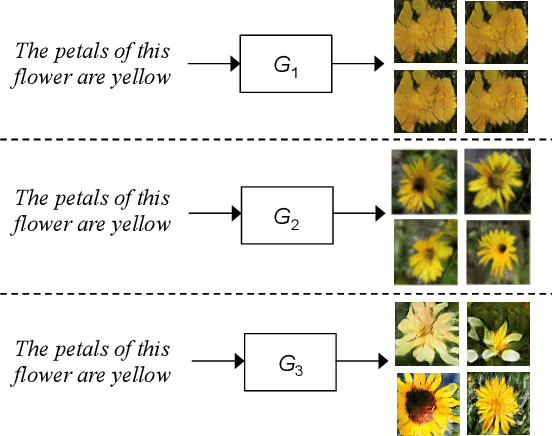
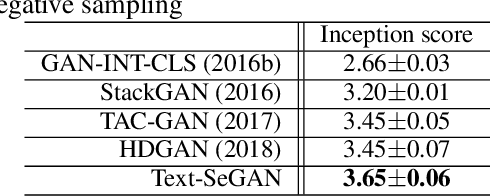
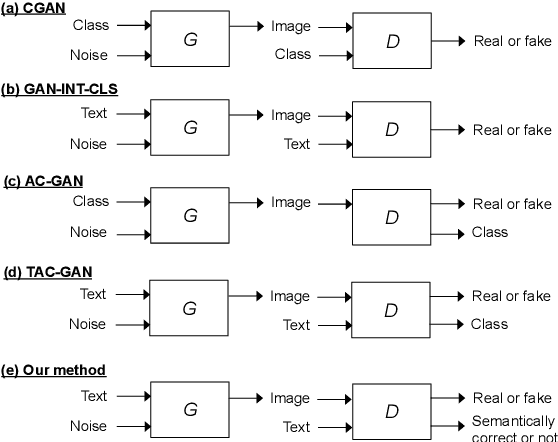
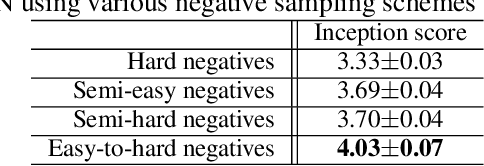
We describe a new approach that improves the training of generative adversarial nets (GANs) for synthesizing diverse images from a text input. Our approach is based on the conditional version of GANs and expands on previous work leveraging an auxiliary task in the discriminator. Our generated images are not limited to certain classes and do not suffer from mode collapse while semantically matching the text input. A key to our training methods is how to form positive and negative training examples with respect to the class label of a given image. Instead of selecting random training examples, we perform negative sampling based on the semantic distance from a positive example in the class. We evaluate our approach using the Oxford-102 flower dataset, adopting the inception score and multi-scale structural similarity index (MS-SSIM) metrics to assess discriminability and diversity of the generated images. The empirical results indicate greater diversity in the generated images, especially when we gradually select more negative training examples closer to a positive example in the semantic space.
Language Modeling by Clustering with Word Embeddings for Text Readability Assessment
Sep 05, 2017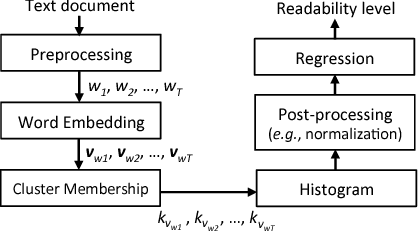
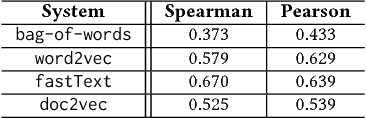
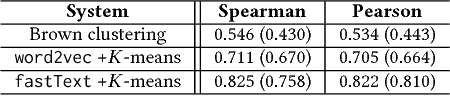
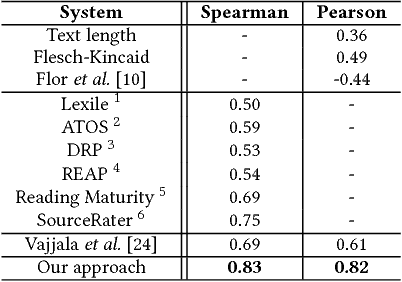
We present a clustering-based language model using word embeddings for text readability prediction. Presumably, an Euclidean semantic space hypothesis holds true for word embeddings whose training is done by observing word co-occurrences. We argue that clustering with word embeddings in the metric space should yield feature representations in a higher semantic space appropriate for text regression. Also, by representing features in terms of histograms, our approach can naturally address documents of varying lengths. An empirical evaluation using the Common Core Standards corpus reveals that the features formed on our clustering-based language model significantly improve the previously known results for the same corpus in readability prediction. We also evaluate the task of sentence matching based on semantic relatedness using the Wiki-SimpleWiki corpus and find that our features lead to superior matching performance.