 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre ChatGPT and Other Similar Systems the Modern Lernaean Hydras of AI?
Jun 15, 2023The rise of Generative Artificial Intelligence systems (``AI systems'') has created unprecedented social engagement. AI code generation systems provide responses (output) to questions or requests by accessing the vast library of open-source code created by developers over decades. However, they do so by allegedly stealing the open-source code stored in virtual libraries, known as repositories. How all this happens and whether there is a solution short of years of litigation that can protect innovation is the focus of this article. We also peripherally touch upon the array of issues raised by the relationship between AI and copyright. Looking ahead, we propose the following: (a) immediate changes to the licenses for open-source code created by developers that will allow access and/or use of any open-source code to humans only; (b) we suggest revisions to the Massachusetts Institute of Technology (``MIT'') license so that AI systems procure appropriate licenses from open-source code developers, which we believe will harmonize standards and build social consensus for the benefit of all of humanity rather than profit-driven centers of innovation; (c) We call for urgent legislative action to protect the future of AI systems while also promoting innovation; and (d) we propose that there is a shift in the burden of proof to AI systems in obfuscation cases.
An Evaluation of Low Overhead Time Series Preprocessing Techniques for Downstream Machine Learning
Sep 12, 2022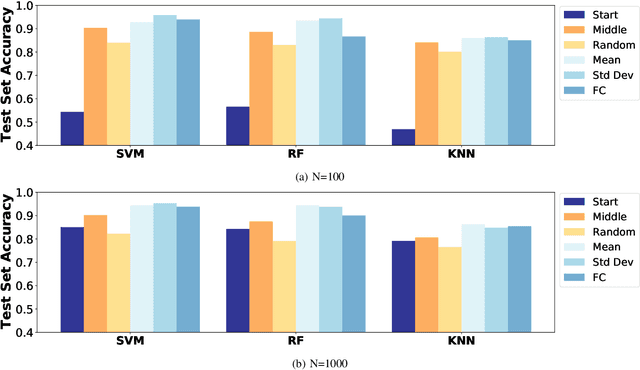
In this paper we address the application of pre-processing techniques to multi-channel time series data with varying lengths, which we refer to as the alignment problem, for downstream machine learning. The misalignment of multi-channel time series data may occur for a variety of reasons, such as missing data, varying sampling rates, or inconsistent collection times. We consider multi-channel time series data collected from the MIT SuperCloud High Performance Computing (HPC) center, where different job start times and varying run times of HPC jobs result in misaligned data. This misalignment makes it challenging to build AI/ML approaches for tasks such as compute workload classification. Building on previous supervised classification work with the MIT SuperCloud Dataset, we address the alignment problem via three broad, low overhead approaches: sampling a fixed subset from a full time series, performing summary statistics on a full time series, and sampling a subset of coefficients from time series mapped to the frequency domain. Our best performing models achieve a classification accuracy greater than 95%, outperforming previous approaches to multi-channel time series classification with the MIT SuperCloud Dataset by 5%. These results indicate our low overhead approaches to solving the alignment problem, in conjunction with standard machine learning techniques, are able to achieve high levels of classification accuracy, and serve as a baseline for future approaches to addressing the alignment problem, such as kernel methods.
Developing a Series of AI Challenges for the United States Department of the Air Force
Jul 14, 2022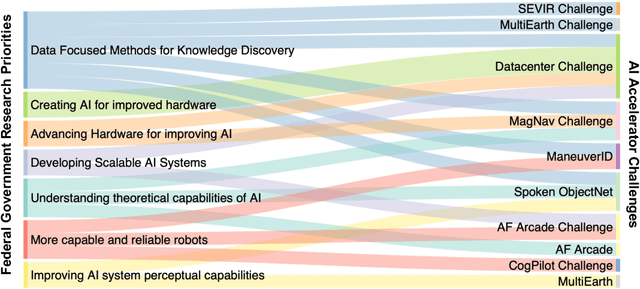

Through a series of federal initiatives and orders, the U.S. Government has been making a concerted effort to ensure American leadership in AI. These broad strategy documents have influenced organizations such as the United States Department of the Air Force (DAF). The DAF-MIT AI Accelerator is an initiative between the DAF and MIT to bridge the gap between AI researchers and DAF mission requirements. Several projects supported by the DAF-MIT AI Accelerator are developing public challenge problems that address numerous Federal AI research priorities. These challenges target priorities by making large, AI-ready datasets publicly available, incentivizing open-source solutions, and creating a demand signal for dual use technologies that can stimulate further research. In this article, we describe these public challenges being developed and how their application contributes to scientific advances.
The MIT Supercloud Workload Classification Challenge
Apr 13, 2022

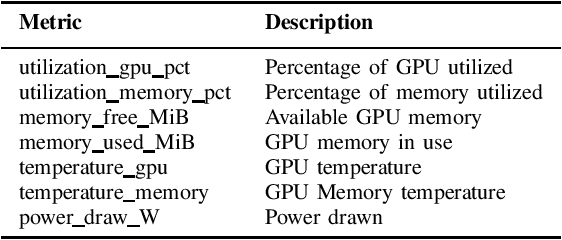
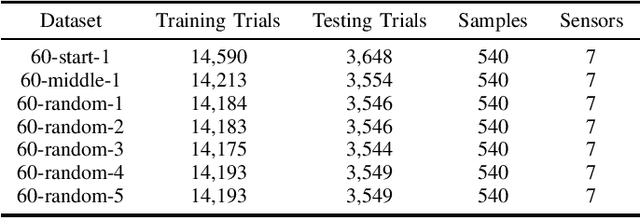
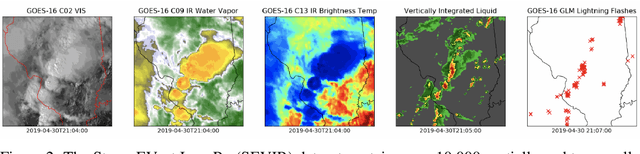
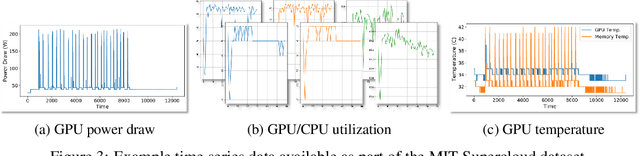
High-Performance Computing (HPC) centers and cloud providers support an increasingly diverse set of applications on heterogenous hardware. As Artificial Intelligence (AI) and Machine Learning (ML) workloads have become an increasingly larger share of the compute workloads, new approaches to optimized resource usage, allocation, and deployment of new AI frameworks are needed. By identifying compute workloads and their utilization characteristics, HPC systems may be able to better match available resources with the application demand. By leveraging datacenter instrumentation, it may be possible to develop AI-based approaches that can identify workloads and provide feedback to researchers and datacenter operators for improving operational efficiency. To enable this research, we released the MIT Supercloud Dataset, which provides detailed monitoring logs from the MIT Supercloud cluster. This dataset includes CPU and GPU usage by jobs, memory usage, and file system logs. In this paper, we present a workload classification challenge based on this dataset. We introduce a labelled dataset that can be used to develop new approaches to workload classification and present initial results based on existing approaches. The goal of this challenge is to foster algorithmic innovations in the analysis of compute workloads that can achieve higher accuracy than existing methods. Data and code will be made publicly available via the Datacenter Challenge website : https://dcc.mit.edu.