 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Green(er) World for A.I
Jan 27, 2023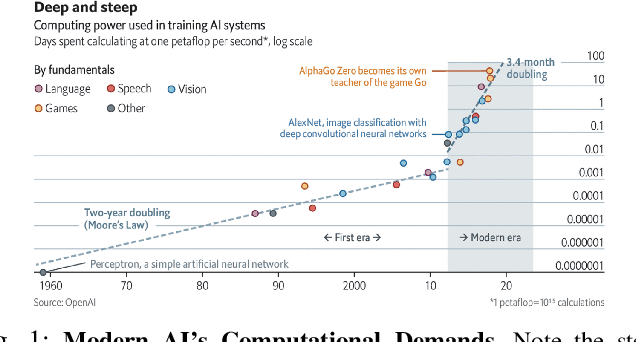
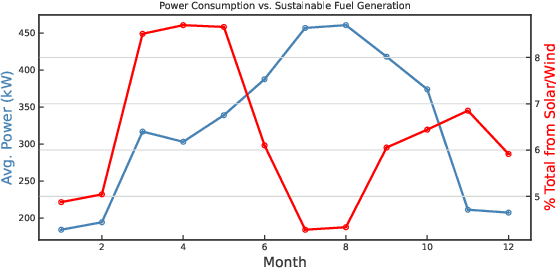
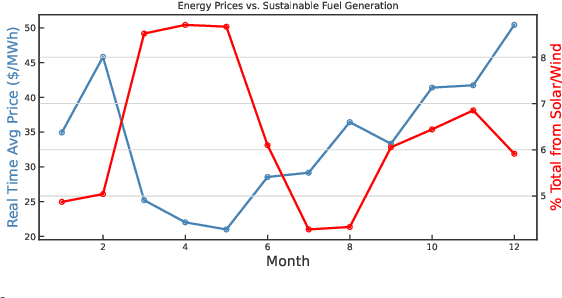
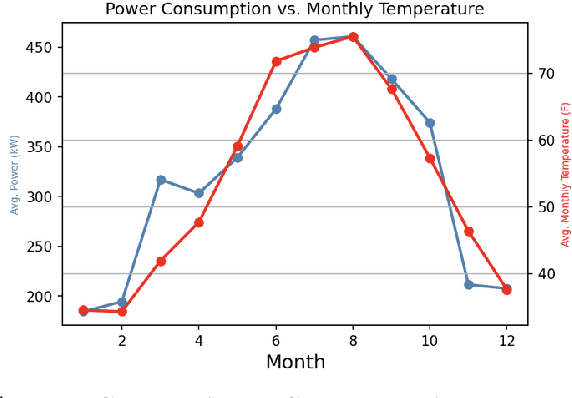
As research and practice in artificial intelligence (A.I.) grow in leaps and bounds, the resources necessary to sustain and support their operations also grow at an increasing pace. While innovations and applications from A.I. have brought significant advances, from applications to vision and natural language to improvements to fields like medical imaging and materials engineering, their costs should not be neglected. As we embrace a world with ever-increasing amounts of data as well as research and development of A.I. applications, we are sure to face an ever-mounting energy footprint to sustain these computational budgets, data storage needs, and more. But, is this sustainable and, more importantly, what kind of setting is best positioned to nurture such sustainable A.I. in both research and practice? In this paper, we outline our outlook for Green A.I. -- a more sustainable, energy-efficient and energy-aware ecosystem for developing A.I. across the research, computing, and practitioner communities alike -- and the steps required to arrive there. We present a bird's eye view of various areas for potential changes and improvements from the ground floor of AI's operational and hardware optimizations for datacenters/HPCs to the current incentive structures in the world of A.I. research and practice, and more. We hope these points will spur further discussion, and action, on some of these issues and their potential solutions.
* 8 pages, published in 2022 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW)
An Evaluation of Low Overhead Time Series Preprocessing Techniques for Downstream Machine Learning
Sep 12, 2022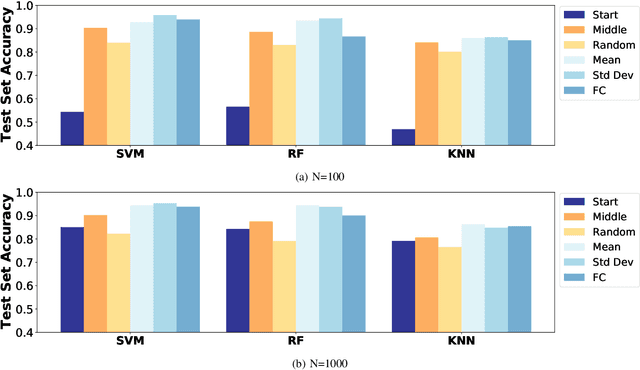
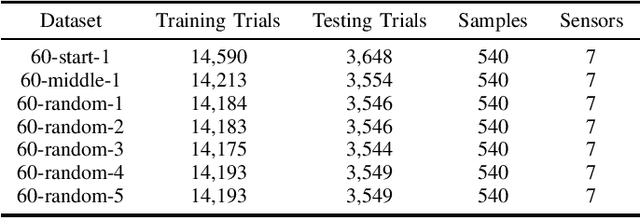
In this paper we address the application of pre-processing techniques to multi-channel time series data with varying lengths, which we refer to as the alignment problem, for downstream machine learning. The misalignment of multi-channel time series data may occur for a variety of reasons, such as missing data, varying sampling rates, or inconsistent collection times. We consider multi-channel time series data collected from the MIT SuperCloud High Performance Computing (HPC) center, where different job start times and varying run times of HPC jobs result in misaligned data. This misalignment makes it challenging to build AI/ML approaches for tasks such as compute workload classification. Building on previous supervised classification work with the MIT SuperCloud Dataset, we address the alignment problem via three broad, low overhead approaches: sampling a fixed subset from a full time series, performing summary statistics on a full time series, and sampling a subset of coefficients from time series mapped to the frequency domain. Our best performing models achieve a classification accuracy greater than 95%, outperforming previous approaches to multi-channel time series classification with the MIT SuperCloud Dataset by 5%. These results indicate our low overhead approaches to solving the alignment problem, in conjunction with standard machine learning techniques, are able to achieve high levels of classification accuracy, and serve as a baseline for future approaches to addressing the alignment problem, such as kernel methods.
The MIT Supercloud Workload Classification Challenge
Apr 13, 2022

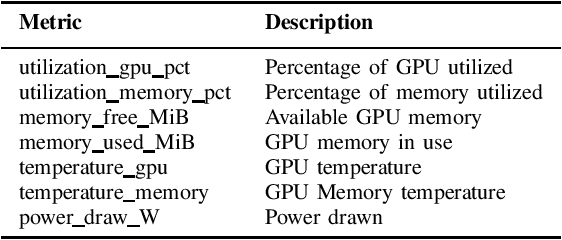
High-Performance Computing (HPC) centers and cloud providers support an increasingly diverse set of applications on heterogenous hardware. As Artificial Intelligence (AI) and Machine Learning (ML) workloads have become an increasingly larger share of the compute workloads, new approaches to optimized resource usage, allocation, and deployment of new AI frameworks are needed. By identifying compute workloads and their utilization characteristics, HPC systems may be able to better match available resources with the application demand. By leveraging datacenter instrumentation, it may be possible to develop AI-based approaches that can identify workloads and provide feedback to researchers and datacenter operators for improving operational efficiency. To enable this research, we released the MIT Supercloud Dataset, which provides detailed monitoring logs from the MIT Supercloud cluster. This dataset includes CPU and GPU usage by jobs, memory usage, and file system logs. In this paper, we present a workload classification challenge based on this dataset. We introduce a labelled dataset that can be used to develop new approaches to workload classification and present initial results based on existing approaches. The goal of this challenge is to foster algorithmic innovations in the analysis of compute workloads that can achieve higher accuracy than existing methods. Data and code will be made publicly available via the Datacenter Challenge website : https://dcc.mit.edu.
The MIT Supercloud Dataset
Aug 04, 2021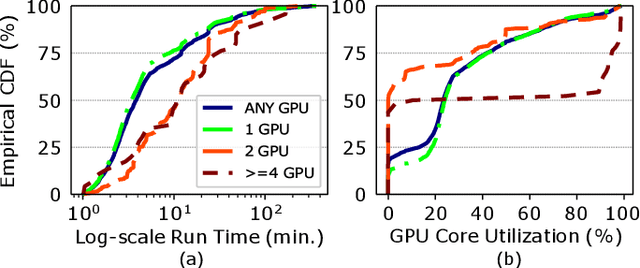
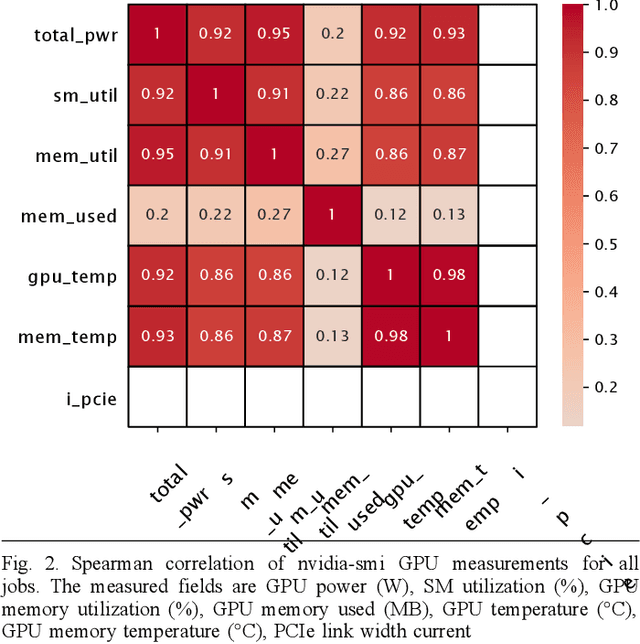
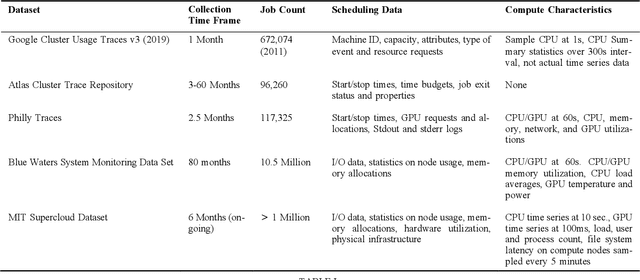

Artificial intelligence (AI) and Machine learning (ML) workloads are an increasingly larger share of the compute workloads in traditional High-Performance Computing (HPC) centers and commercial cloud systems. This has led to changes in deployment approaches of HPC clusters and the commercial cloud, as well as a new focus on approaches to optimized resource usage, allocations and deployment of new AI frame- works, and capabilities such as Jupyter notebooks to enable rapid prototyping and deployment. With these changes, there is a need to better understand cluster/datacenter operations with the goal of developing improved scheduling policies, identifying inefficiencies in resource utilization, energy/power consumption, failure prediction, and identifying policy violations. In this paper we introduce the MIT Supercloud Dataset which aims to foster innovative AI/ML approaches to the analysis of large scale HPC and datacenter/cloud operations. We provide detailed monitoring logs from the MIT Supercloud system, which include CPU and GPU usage by jobs, memory usage, file system logs, and physical monitoring data. This paper discusses the details of the dataset, collection methodology, data availability, and discusses potential challenge problems being developed using this data. Datasets and future challenge announcements will be available via https://dcc.mit.edu.
Accuracy and Performance Comparison of Video Action Recognition Approaches
Aug 20, 2020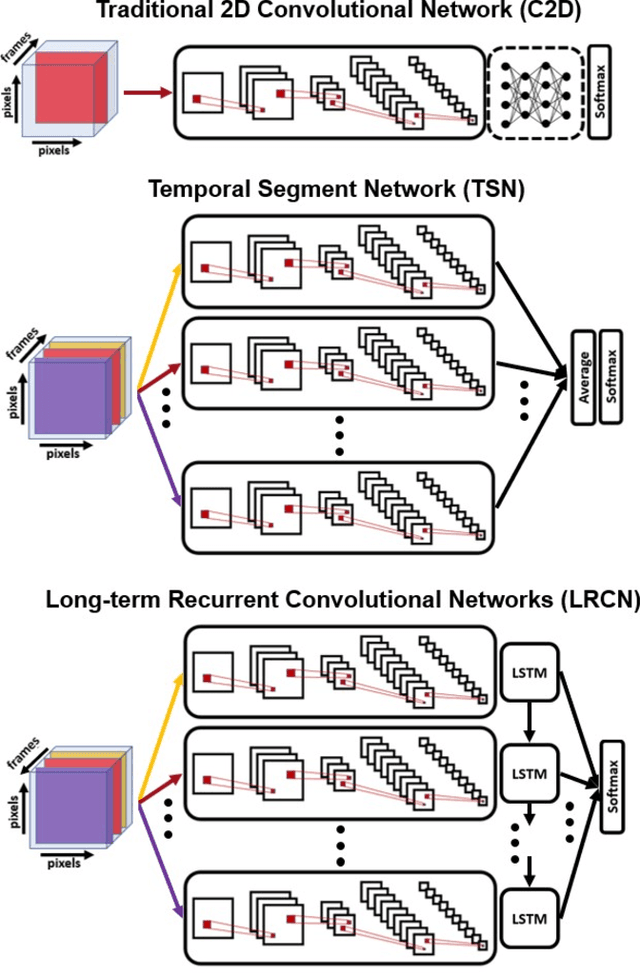
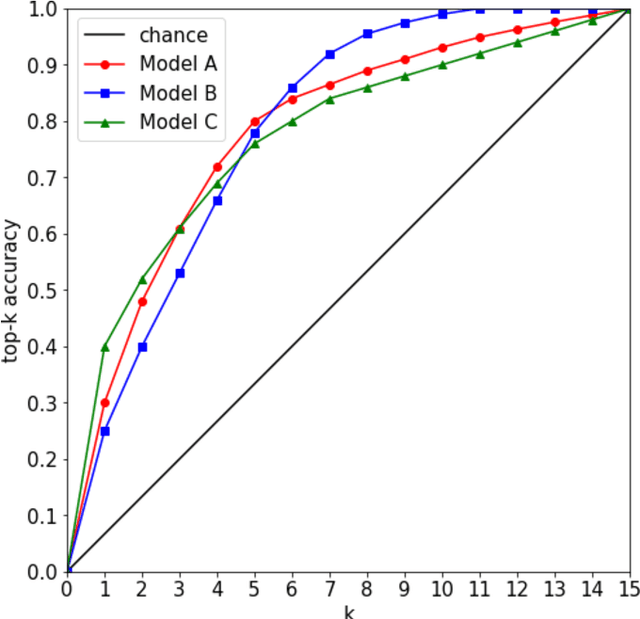
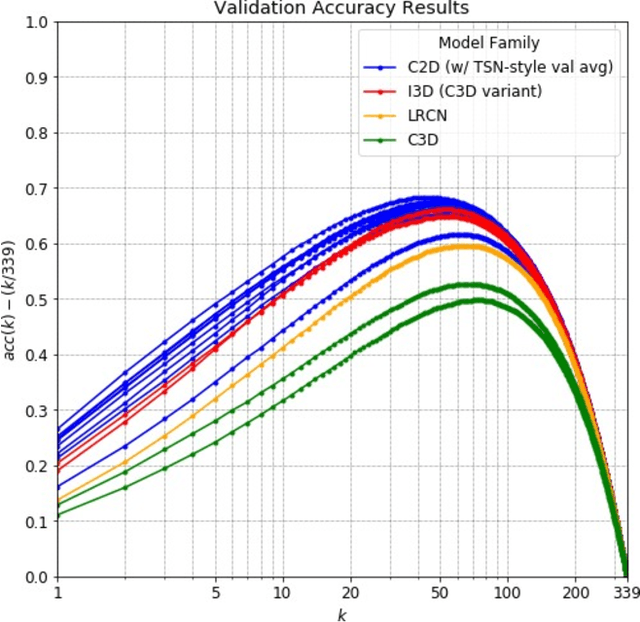
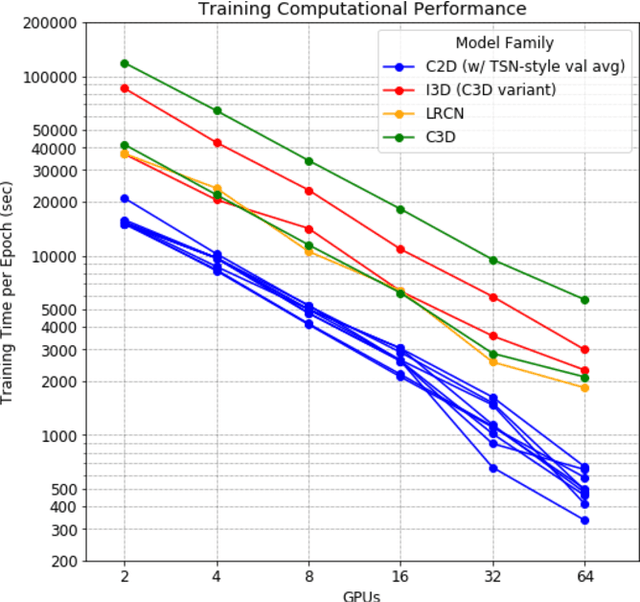
Over the past few years, there has been significant interest in video action recognition systems and models. However, direct comparison of accuracy and computational performance results remain clouded by differing training environments, hardware specifications, hyperparameters, pipelines, and inference methods. This article provides a direct comparison between fourteen off-the-shelf and state-of-the-art models by ensuring consistency in these training characteristics in order to provide readers with a meaningful comparison across different types of video action recognition algorithms. Accuracy of the models is evaluated using standard Top-1 and Top-5 accuracy metrics in addition to a proposed new accuracy metric. Additionally, we compare computational performance of distributed training from two to sixty-four GPUs on a state-of-the-art HPC system.
Benchmarking network fabrics for data distributed training of deep neural networks
Aug 18, 2020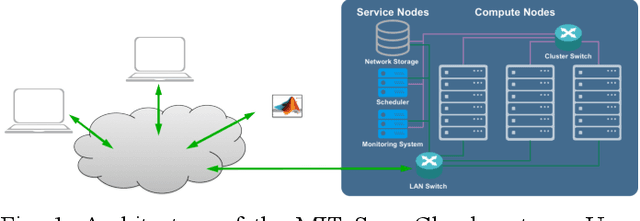
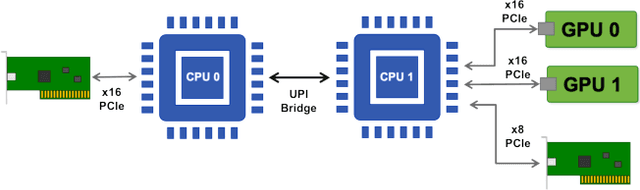
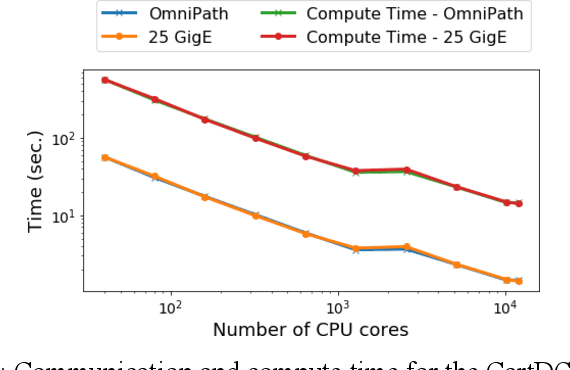

Artificial Intelligence/Machine Learning applications require the training of complex models on large amounts of labelled data. The large computational requirements for training deep models have necessitated the development of new methods for faster training. One such approach is the data parallel approach, where the training data is distributed across multiple compute nodes. This approach is simple to implement and supported by most of the commonly used machine learning frameworks. The data parallel approach leverages MPI for communicating gradients across all nodes. In this paper, we examine the effects of using different physical hardware interconnects and network-related software primitives for enabling data distributed deep learning. We compare the effect of using GPUDirect and NCCL on Ethernet and OmniPath fabrics. Our results show that using Ethernet-based networking in shared HPC systems does not have a significant effect on the training times for commonly used deep neural network architectures or traditional HPC applications such as Computational Fluid Dynamics.