 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed-Form Test Functions for Biophysical Sequence Optimization Algorithms
Jun 28, 2024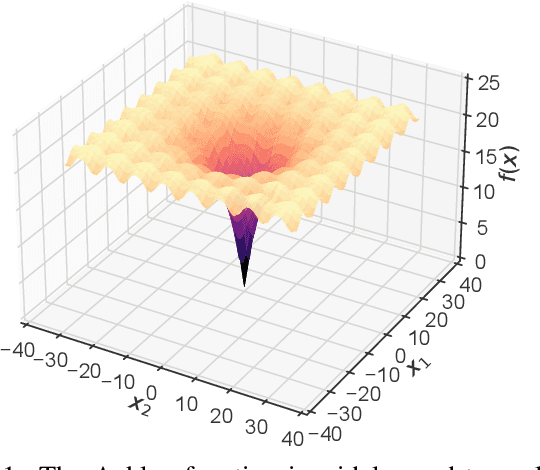
There is a growing body of work seeking to replicate the success of machine learning (ML) on domains like computer vision (CV) and natural language processing (NLP) to applications involving biophysical data. One of the key ingredients of prior successes in CV and NLP was the broad acceptance of difficult benchmarks that distilled key subproblems into approachable tasks that any junior researcher could investigate, but good benchmarks for biophysical domains are rare. This scarcity is partially due to a narrow focus on benchmarks which simulate biophysical data; we propose instead to carefully abstract biophysical problems into simpler ones with key geometric similarities. In particular we propose a new class of closed-form test functions for biophysical sequence optimization, which we call Ehrlich functions. We provide empirical results demonstrating these functions are interesting objects of study and can be non-trivial to solve with a standard genetic optimization baseline.
Great Power, Great Responsibility: Recommendations for Reducing Energy for Training Language Models
May 19, 2022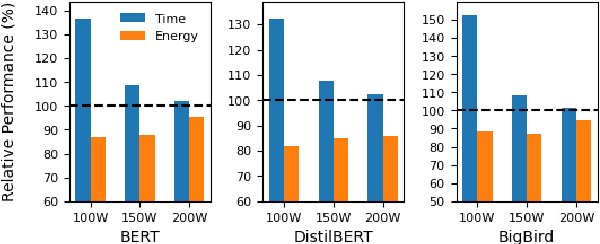
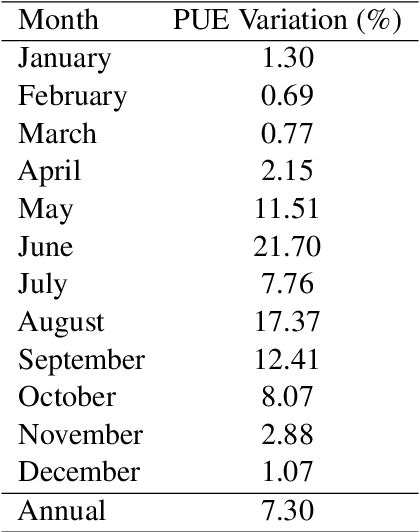
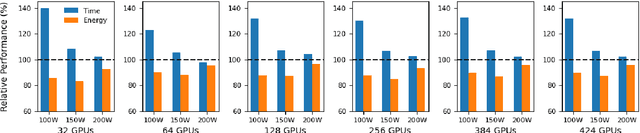
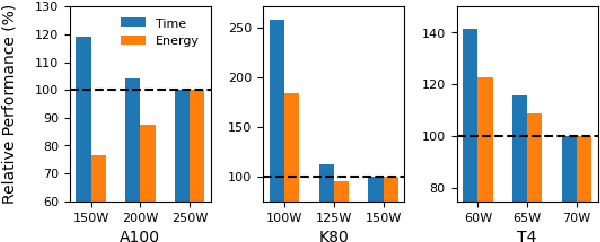
The energy requirements of current natural language processing models continue to grow at a rapid, unsustainable pace. Recent works highlighting this problem conclude there is an urgent need for methods that reduce the energy needs of NLP and machine learning more broadly. In this article, we investigate techniques that can be used to reduce the energy consumption of common NLP applications. In particular, we focus on techniques to measure energy usage and different hardware and datacenter-oriented settings that can be tuned to reduce energy consumption for training and inference for language models. We characterize the impact of these settings on metrics such as computational performance and energy consumption through experiments conducted on a high performance computing system as well as popular cloud computing platforms. These techniques can lead to significant reduction in energy consumption when training language models or their use for inference. For example, power-capping, which limits the maximum power a GPU can consume, can enable a 15\% decrease in energy usage with marginal increase in overall computation time when training a transformer-based language model.
The MIT Supercloud Workload Classification Challenge
Apr 13, 2022

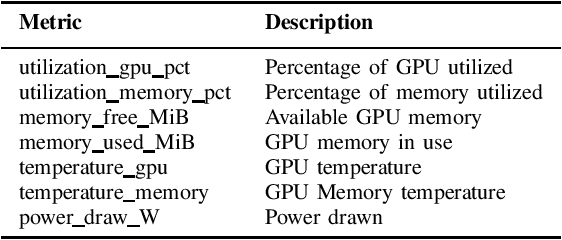
High-Performance Computing (HPC) centers and cloud providers support an increasingly diverse set of applications on heterogenous hardware. As Artificial Intelligence (AI) and Machine Learning (ML) workloads have become an increasingly larger share of the compute workloads, new approaches to optimized resource usage, allocation, and deployment of new AI frameworks are needed. By identifying compute workloads and their utilization characteristics, HPC systems may be able to better match available resources with the application demand. By leveraging datacenter instrumentation, it may be possible to develop AI-based approaches that can identify workloads and provide feedback to researchers and datacenter operators for improving operational efficiency. To enable this research, we released the MIT Supercloud Dataset, which provides detailed monitoring logs from the MIT Supercloud cluster. This dataset includes CPU and GPU usage by jobs, memory usage, and file system logs. In this paper, we present a workload classification challenge based on this dataset. We introduce a labelled dataset that can be used to develop new approaches to workload classification and present initial results based on existing approaches. The goal of this challenge is to foster algorithmic innovations in the analysis of compute workloads that can achieve higher accuracy than existing methods. Data and code will be made publicly available via the Datacenter Challenge website : https://dcc.mit.edu.
Automatic Non-Linear Video Editing Transfer
May 14, 2021
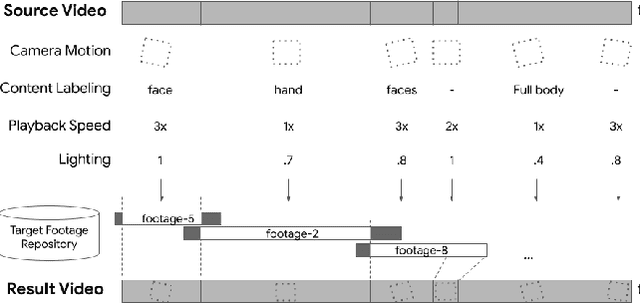


We propose an automatic approach that extracts editing styles in a source video and applies the edits to matched footage for video creation. Our Computer Vision based techniques considers framing, content type, playback speed, and lighting of each input video segment. By applying a combination of these features, we demonstrate an effective method that automatically transfers the visual and temporal styles from professionally edited videos to unseen raw footage. We evaluated our approach with real-world videos that contained a total of 3872 video shots of a variety of editing styles, including different subjects, camera motions, and lighting. We reported feedback from survey participants who reviewed a set of our results.
* Published to AI for Content Creation Workshop at CVPR 2021