 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHelpViz: Automatic Generation of Contextual Visual MobileTutorials from Text-Based Instructions
Aug 07, 2021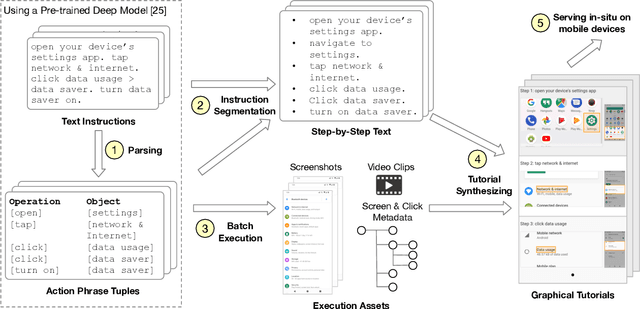

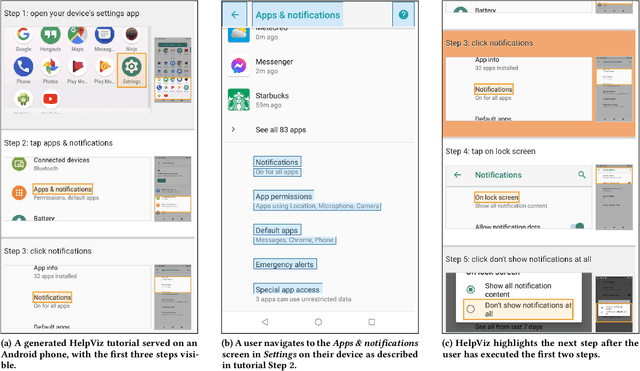

We present HelpViz, a tool for generating contextual visual mobile tutorials from text-based instructions that are abundant on the web. HelpViz transforms text instructions to graphical tutorials in batch, by extracting a sequence of actions from each text instruction through an instruction parsing model, and executing the extracted actions on a simulation infrastructure that manages an array of Android emulators. The automatic execution of each instruction produces a set of graphical and structural assets, including images, videos, and metadata such as clicked elements for each step. HelpViz then synthesizes a tutorial by combining parsed text instructions with the generated assets, and contextualizes the tutorial to user interaction by tracking the user's progress and highlighting the next step. Our experiments with HelpViz indicate that our pipeline improved tutorial execution robustness and that participants preferred tutorials generated by HelpViz over text-based instructions. HelpViz promises a cost-effective approach for generating contextual visual tutorials for mobile interaction at scale.
Automatic Non-Linear Video Editing Transfer
May 14, 2021
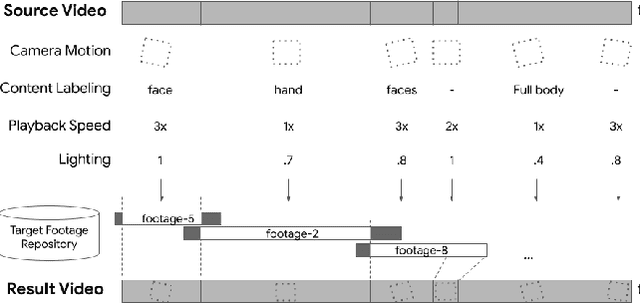


We propose an automatic approach that extracts editing styles in a source video and applies the edits to matched footage for video creation. Our Computer Vision based techniques considers framing, content type, playback speed, and lighting of each input video segment. By applying a combination of these features, we demonstrate an effective method that automatically transfers the visual and temporal styles from professionally edited videos to unseen raw footage. We evaluated our approach with real-world videos that contained a total of 3872 video shots of a variety of editing styles, including different subjects, camera motions, and lighting. We reported feedback from survey participants who reviewed a set of our results.
* Published to AI for Content Creation Workshop at CVPR 2021