 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
Oct 09, 2025Large Language Models (LLMs) pose a new paradigm of modeling and computation for information tasks. Recommendation systems are a critical application domain poised to benefit significantly from the sequence modeling capabilities and world knowledge inherent in these large models. In this paper, we introduce PLUM, a framework designed to adapt pre-trained LLMs for industry-scale recommendation tasks. PLUM consists of item tokenization using Semantic IDs, continued pre-training (CPT) on domain-specific data, and task-specific fine-tuning for recommendation objectives. For fine-tuning, we focus particularly on generative retrieval, where the model is directly trained to generate Semantic IDs of recommended items based on user context. We conduct comprehensive experiments on large-scale internal video recommendation datasets. Our results demonstrate that PLUM achieves substantial improvements for retrieval compared to a heavily-optimized production model built with large embedding tables. We also present a scaling study for the model's retrieval performance, our learnings about CPT, a few enhancements to Semantic IDs, along with an overview of the training and inference methods that enable launching this framework to billions of users in YouTube.
Three-dimensional attention Transformer for state evaluation in real-time strategy games
Jan 07, 2025



Situation assessment in Real-Time Strategy (RTS) games is crucial for understanding decision-making in complex adversarial environments. However, existing methods remain limited in processing multi-dimensional feature information and temporal dependencies. Here we propose a tri-dimensional Space-Time-Feature Transformer (TSTF Transformer) architecture, which efficiently models battlefield situations through three independent but cascaded modules: spatial attention, temporal attention, and feature attention. On a dataset comprising 3,150 adversarial experiments, the 8-layer TSTF Transformer demonstrates superior performance: achieving 58.7% accuracy in the early game (~4% progress), significantly outperforming the conventional Timesformer's 41.8%; reaching 97.6% accuracy in the mid-game (~40% progress) while maintaining low performance variation (standard deviation 0.114). Meanwhile, this architecture requires fewer parameters (4.75M) compared to the baseline model (5.54M). Our study not only provides new insights into situation assessment in RTS games but also presents an innovative paradigm for Transformer-based multi-dimensional temporal modeling.
Online Reinforcement Learning-Based Dynamic Adaptive Evaluation Function for Real-Time Strategy Tasks
Jan 07, 2025
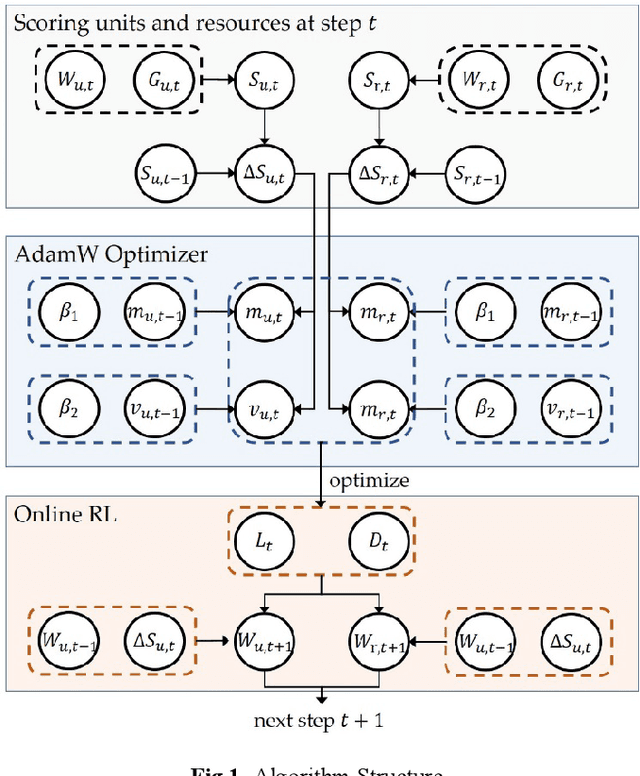
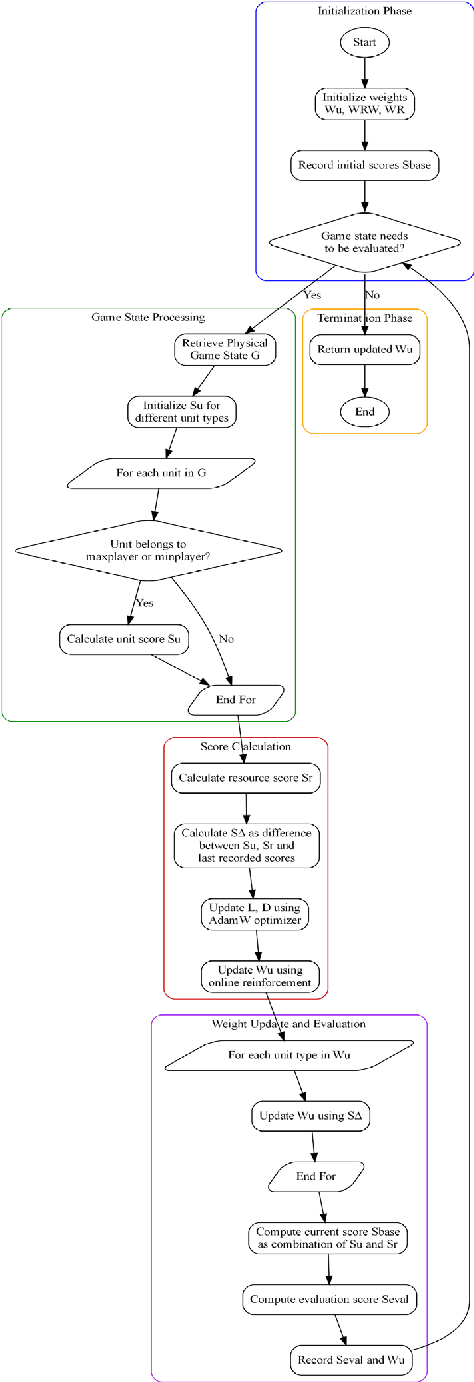
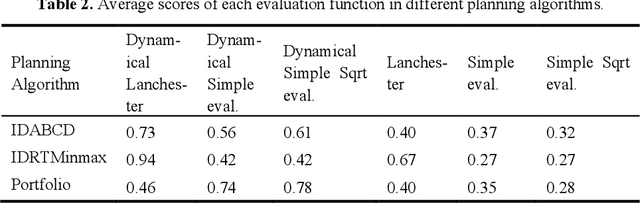
Effective evaluation of real-time strategy tasks requires adaptive mechanisms to cope with dynamic and unpredictable environments. This study proposes a method to improve evaluation functions for real-time responsiveness to battle-field situation changes, utilizing an online reinforcement learning-based dynam-ic weight adjustment mechanism within the real-time strategy game. Building on traditional static evaluation functions, the method employs gradient descent in online reinforcement learning to update weights dynamically, incorporating weight decay techniques to ensure stability. Additionally, the AdamW optimizer is integrated to adjust the learning rate and decay rate of online reinforcement learning in real time, further reducing the dependency on manual parameter tun-ing. Round-robin competition experiments demonstrate that this method signifi-cantly enhances the application effectiveness of the Lanchester combat model evaluation function, Simple evaluation function, and Simple Sqrt evaluation function in planning algorithms including IDABCD, IDRTMinimax, and Port-folio AI. The method achieves a notable improvement in scores, with the en-hancement becoming more pronounced as the map size increases. Furthermore, the increase in evaluation function computation time induced by this method is kept below 6% for all evaluation functions and planning algorithms. The pro-posed dynamic adaptive evaluation function demonstrates a promising approach for real-time strategy task evaluation.
STT: Stateful Tracking with Transformers for Autonomous Driving
Apr 30, 2024Tracking objects in three-dimensional space is critical for autonomous driving. To ensure safety while driving, the tracker must be able to reliably track objects across frames and accurately estimate their states such as velocity and acceleration in the present. Existing works frequently focus on the association task while either neglecting the model performance on state estimation or deploying complex heuristics to predict the states. In this paper, we propose STT, a Stateful Tracking model built with Transformers, that can consistently track objects in the scenes while also predicting their states accurately. STT consumes rich appearance, geometry, and motion signals through long term history of detections and is jointly optimized for both data association and state estimation tasks. Since the standard tracking metrics like MOTA and MOTP do not capture the combined performance of the two tasks in the wider spectrum of object states, we extend them with new metrics called S-MOTA and MOTPS that address this limitation. STT achieves competitive real-time performance on the Waymo Open Dataset.
Pedestrian Crossing Action Recognition and Trajectory Prediction with 3D Human Keypoints
Jun 01, 2023



Accurate understanding and prediction of human behaviors are critical prerequisites for autonomous vehicles, especially in highly dynamic and interactive scenarios such as intersections in dense urban areas. In this work, we aim at identifying crossing pedestrians and predicting their future trajectories. To achieve these goals, we not only need the context information of road geometry and other traffic participants but also need fine-grained information of the human pose, motion and activity, which can be inferred from human keypoints. In this paper, we propose a novel multi-task learning framework for pedestrian crossing action recognition and trajectory prediction, which utilizes 3D human keypoints extracted from raw sensor data to capture rich information on human pose and activity. Moreover, we propose to apply two auxiliary tasks and contrastive learning to enable auxiliary supervisions to improve the learned keypoints representation, which further enhances the performance of major tasks. We validate our approach on a large-scale in-house dataset, as well as a public benchmark dataset, and show that our approach achieves state-of-the-art performance on a wide range of evaluation metrics. The effectiveness of each model component is validated in a detailed ablation study.
Automatic Non-Linear Video Editing Transfer
May 14, 2021
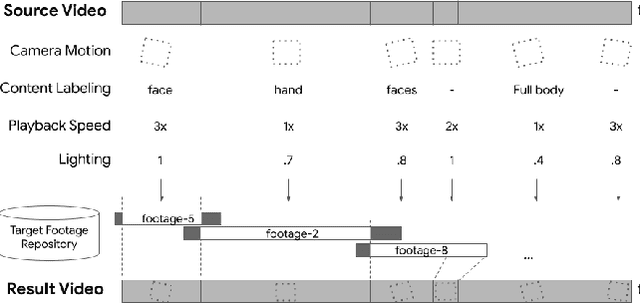


We propose an automatic approach that extracts editing styles in a source video and applies the edits to matched footage for video creation. Our Computer Vision based techniques considers framing, content type, playback speed, and lighting of each input video segment. By applying a combination of these features, we demonstrate an effective method that automatically transfers the visual and temporal styles from professionally edited videos to unseen raw footage. We evaluated our approach with real-world videos that contained a total of 3872 video shots of a variety of editing styles, including different subjects, camera motions, and lighting. We reported feedback from survey participants who reviewed a set of our results.
* Published to AI for Content Creation Workshop at CVPR 2021
Regularizing Generative Adversarial Networks under Limited Data
Apr 07, 2021
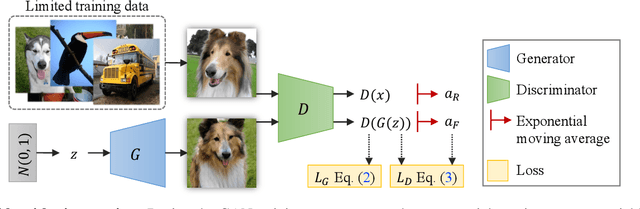
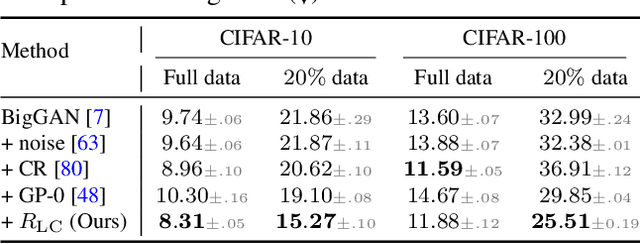
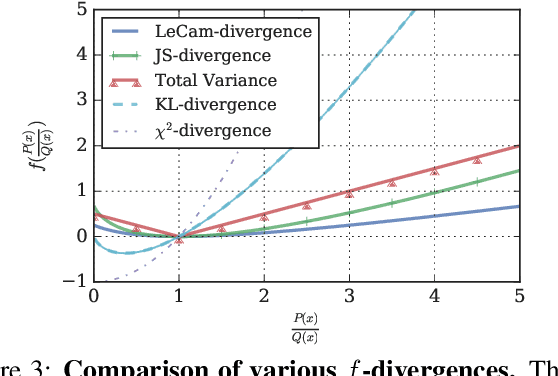
Recent years have witnessed the rapid progress of generative adversarial networks (GANs). However, the success of the GAN models hinges on a large amount of training data. This work proposes a regularization approach for training robust GAN models on limited data. We theoretically show a connection between the regularized loss and an f-divergence called LeCam-divergence, which we find is more robust under limited training data. Extensive experiments on several benchmark datasets demonstrate that the proposed regularization scheme 1) improves the generalization performance and stabilizes the learning dynamics of GAN models under limited training data, and 2) complements the recent data augmentation methods. These properties facilitate training GAN models to achieve state-of-the-art performance when only limited training data of the ImageNet benchmark is available.
Text as Neural Operator: Image Manipulation by Text Instruction
Aug 12, 2020
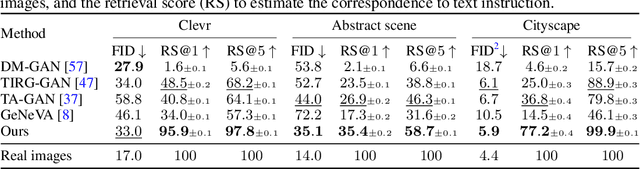
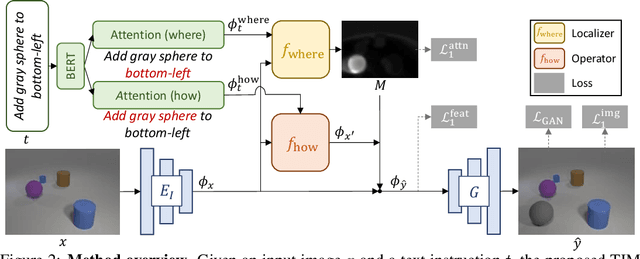
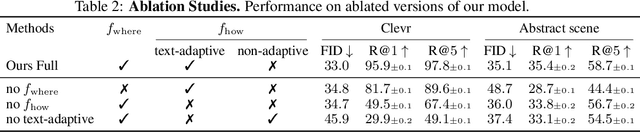
In this paper, we study a new task that allows users to edit an input image using language instructions. In this image generation task, the inputs are a reference image and a text instruction that describes desired modifications to the input image. We propose a GAN-based method to tackle this problem. The key idea is to treat language as neural operators to locally modify the image feature. To this end, our model decomposes the generation process into finding where (spatial region) and how (text operators) to apply modifications. We show that the proposed model performs favorably against recent baselines on three datasets.
RetrieveGAN: Image Synthesis via Differentiable Patch Retrieval
Jul 16, 2020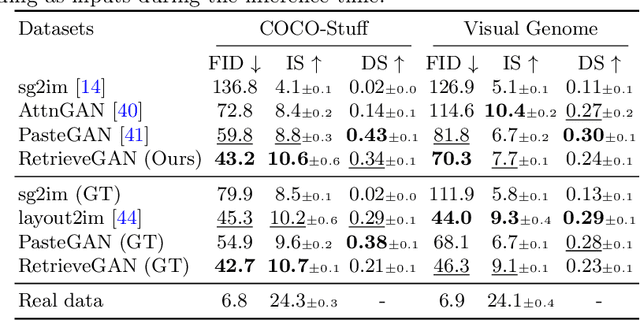
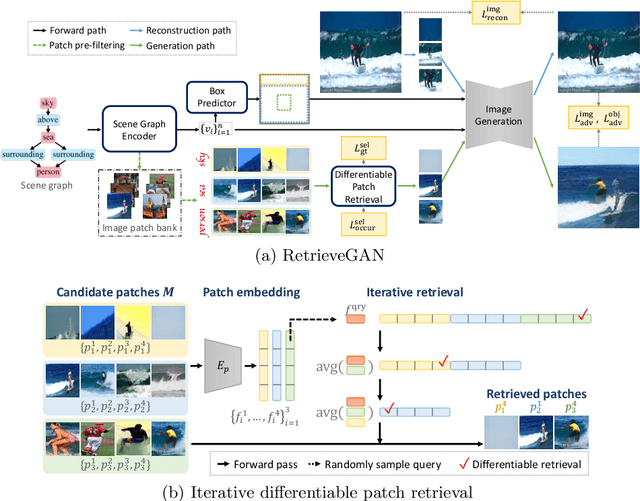

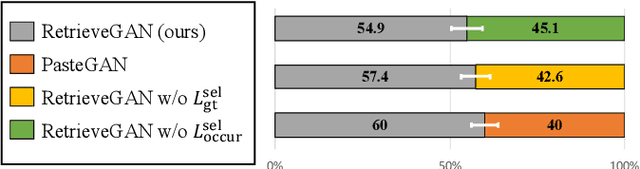
Image generation from scene description is a cornerstone technique for the controlled generation, which is beneficial to applications such as content creation and image editing. In this work, we aim to synthesize images from scene description with retrieved patches as reference. We propose a differentiable retrieval module. With the differentiable retrieval module, we can (1) make the entire pipeline end-to-end trainable, enabling the learning of better feature embedding for retrieval; (2) encourage the selection of mutually compatible patches with additional objective functions. We conduct extensive quantitative and qualitative experiments to demonstrate that the proposed method can generate realistic and diverse images, where the retrieved patches are reasonable and mutually compatible.
Neural Design Network: Graphic Layout Generation with Constraints
Dec 19, 2019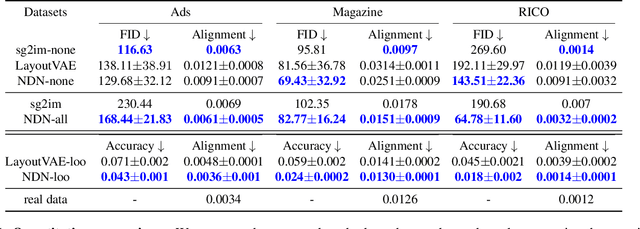
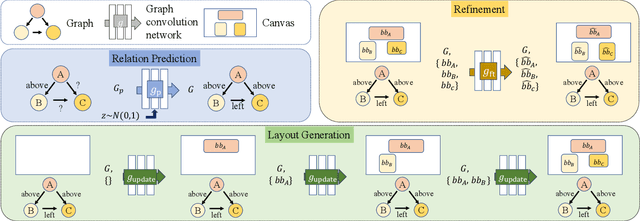
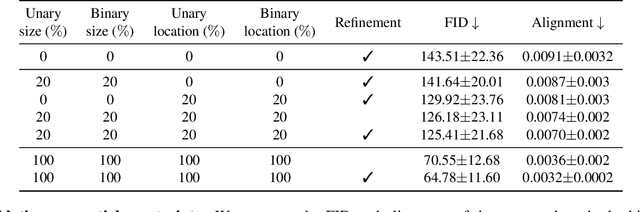
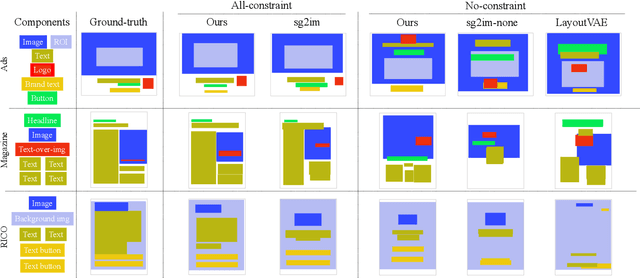
Graphic design is essential for visual communication with layouts being fundamental to composing attractive designs. Layout generation differs from pixel-level image synthesis and is unique in terms of the requirement of mutual relations among the desired components. We propose a method for design layout generation that can satisfy user-specified constraints. The proposed neural design network (NDN) consists of three modules. The first module predicts a graph with complete relations from a graph with user-specified relations. The second module generates a layout from the predicted graph. Finally, the third module fine-tunes the predicted layout. Quantitative and qualitative experiments demonstrate that the generated layouts are visually similar to real design layouts. We also construct real designs based on predicted layouts for a better understanding of the visual quality. Finally, we demonstrate a practical application on layout recommendation.