 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExternal Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
STT: Stateful Tracking with Transformers for Autonomous Driving
Apr 30, 2024Tracking objects in three-dimensional space is critical for autonomous driving. To ensure safety while driving, the tracker must be able to reliably track objects across frames and accurately estimate their states such as velocity and acceleration in the present. Existing works frequently focus on the association task while either neglecting the model performance on state estimation or deploying complex heuristics to predict the states. In this paper, we propose STT, a Stateful Tracking model built with Transformers, that can consistently track objects in the scenes while also predicting their states accurately. STT consumes rich appearance, geometry, and motion signals through long term history of detections and is jointly optimized for both data association and state estimation tasks. Since the standard tracking metrics like MOTA and MOTP do not capture the combined performance of the two tasks in the wider spectrum of object states, we extend them with new metrics called S-MOTA and MOTPS that address this limitation. STT achieves competitive real-time performance on the Waymo Open Dataset.
Towards the Better Ranking Consistency: A Multi-task Learning Framework for Early Stage Ads Ranking
Jul 12, 2023



Dividing ads ranking system into retrieval, early, and final stages is a common practice in large scale ads recommendation to balance the efficiency and accuracy. The early stage ranking often uses efficient models to generate candidates out of a set of retrieved ads. The candidates are then fed into a more computationally intensive but accurate final stage ranking system to produce the final ads recommendation. As the early and final stage ranking use different features and model architectures because of system constraints, a serious ranking consistency issue arises where the early stage has a low ads recall, i.e., top ads in the final stage are ranked low in the early stage. In order to pass better ads from the early to the final stage ranking, we propose a multi-task learning framework for early stage ranking to capture multiple final stage ranking components (i.e. ads clicks and ads quality events) and their task relations. With our multi-task learning framework, we can not only achieve serving cost saving from the model consolidation, but also improve the ads recall and ranking consistency. In the online A/B testing, our framework achieves significantly higher click-through rate (CTR), conversion rate (CVR), total value and better ads-quality (e.g. reduced ads cross-out rate) in a large scale industrial ads ranking system.
Learnability and Complexity of Quantum Samples
Oct 22, 2020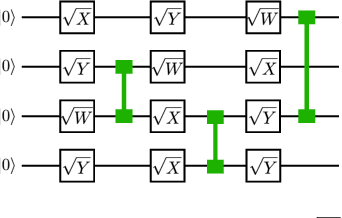
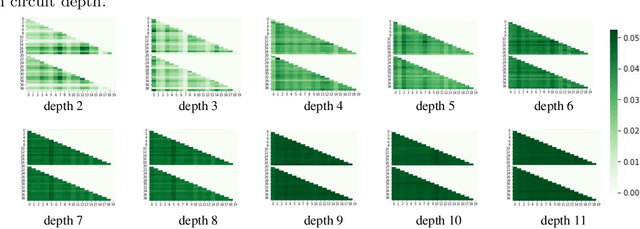
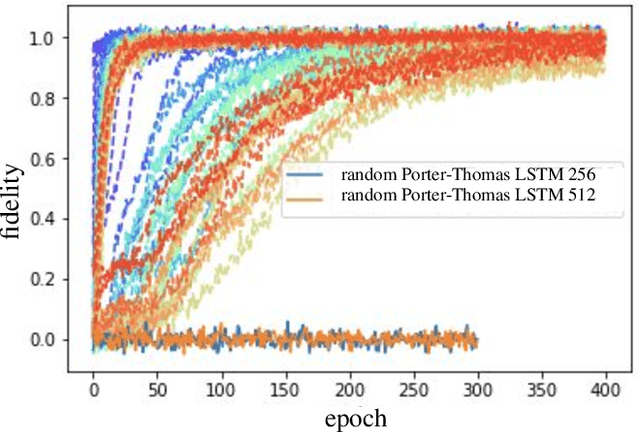
Given a quantum circuit, a quantum computer can sample the output distribution exponentially faster in the number of bits than classical computers. A similar exponential separation has yet to be established in generative models through quantum sample learning: given samples from an n-qubit computation, can we learn the underlying quantum distribution using models with training parameters that scale polynomial in n under a fixed training time? We study four kinds of generative models: Deep Boltzmann machine (DBM), Generative Adversarial Networks (GANs), Long Short-Term Memory (LSTM) and Autoregressive GAN, on learning quantum data set generated by deep random circuits. We demonstrate the leading performance of LSTM in learning quantum samples, and thus the autoregressive structure present in the underlying quantum distribution from random quantum circuits. Both numerical experiments and a theoretical proof in the case of the DBM show exponentially growing complexity of learning-agent parameters required for achieving a fixed accuracy as n increases. Finally, we establish a connection between learnability and the complexity of generative models by benchmarking learnability against different sets of samples drawn from probability distributions of variable degrees of complexities in their quantum and classical representations.
Image Augmentations for GAN Training
Jun 04, 2020



Data augmentations have been widely studied to improve the accuracy and robustness of classifiers. However, the potential of image augmentation in improving GAN models for image synthesis has not been thoroughly investigated in previous studies. In this work, we systematically study the effectiveness of various existing augmentation techniques for GAN training in a variety of settings. We provide insights and guidelines on how to augment images for both vanilla GANs and GANs with regularizations, improving the fidelity of the generated images substantially. Surprisingly, we find that vanilla GANs attain generation quality on par with recent state-of-the-art results if we use augmentations on both real and generated images. When this GAN training is combined with other augmentation-based regularization techniques, such as contrastive loss and consistency regularization, the augmentations further improve the quality of generated images. We provide new state-of-the-art results for conditional generation on CIFAR-10 with both consistency loss and contrastive loss as additional regularizations.
Improved Consistency Regularization for GANs
Feb 11, 2020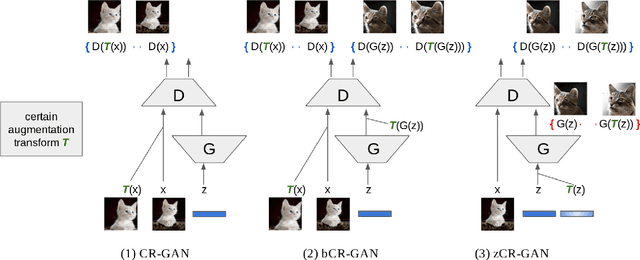
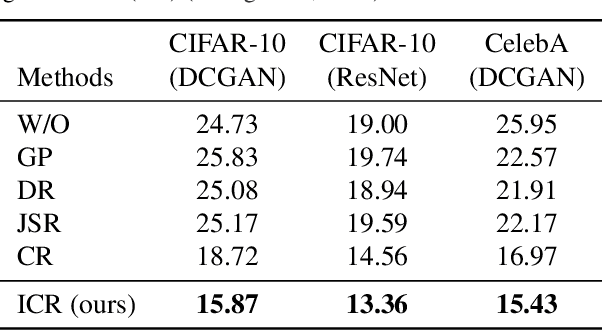


Recent work has increased the performance of Generative Adversarial Networks (GANs) by enforcing a consistency cost on the discriminator. We improve on this technique in several ways. We first show that consistency regularization can introduce artifacts into the GAN samples and explain how to fix this issue. We then propose several modifications to the consistency regularization procedure designed to improve its performance. We carry out extensive experiments quantifying the benefit of our improvements. For unconditional image synthesis on CIFAR-10 and CelebA, our modifications yield the best known FID scores on various GAN architectures. For conditional image synthesis on CIFAR-10, we improve the state-of-the-art FID score from 11.48 to 9.21. Finally, on ImageNet-2012, we apply our technique to the original BigGAN model and improve the FID from 6.66 to 5.38, which is the best score at that model size.
Improving Differentially Private Models with Active Learning
Oct 02, 2019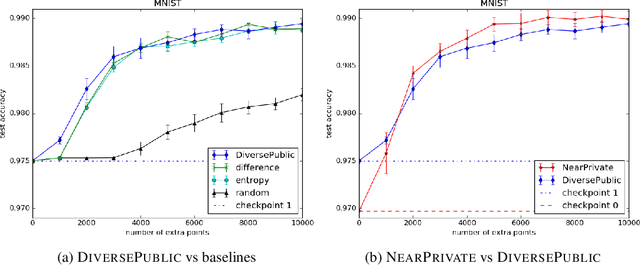
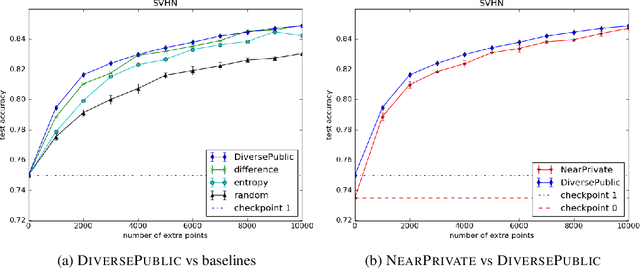
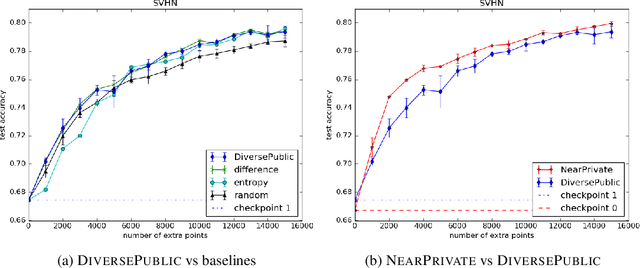
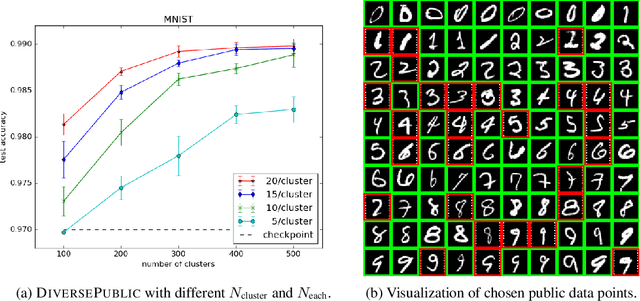
Broad adoption of machine learning techniques has increased privacy concerns for models trained on sensitive data such as medical records. Existing techniques for training differentially private (DP) models give rigorous privacy guarantees, but applying these techniques to neural networks can severely degrade model performance. This performance reduction is an obstacle to deploying private models in the real world. In this work, we improve the performance of DP models by fine-tuning them through active learning on public data. We introduce two new techniques - DIVERSEPUBLIC and NEARPRIVATE - for doing this fine-tuning in a privacy-aware way. For the MNIST and SVHN datasets, these techniques improve state-of-the-art accuracy for DP models while retaining privacy guarantees.
Generating Natural Adversarial Examples
Feb 23, 2018



Due to their complex nature, it is hard to characterize the ways in which machine learning models can misbehave or be exploited when deployed. Recent work on adversarial examples, i.e. inputs with minor perturbations that result in substantially different model predictions, is helpful in evaluating the robustness of these models by exposing the adversarial scenarios where they fail. However, these malicious perturbations are often unnatural, not semantically meaningful, and not applicable to complicated domains such as language. In this paper, we propose a framework to generate natural and legible adversarial examples that lie on the data manifold, by searching in semantic space of dense and continuous data representation, utilizing the recent advances in generative adversarial networks. We present generated adversaries to demonstrate the potential of the proposed approach for black-box classifiers for a wide range of applications such as image classification, textual entailment, and machine translation. We include experiments to show that the generated adversaries are natural, legible to humans, and useful in evaluating and analyzing black-box classifiers.