 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-Guided Masked Token Prediction for 3D Scene Understanding
Oct 17, 2024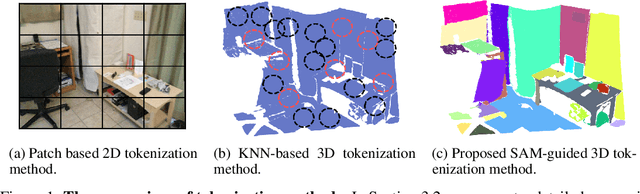

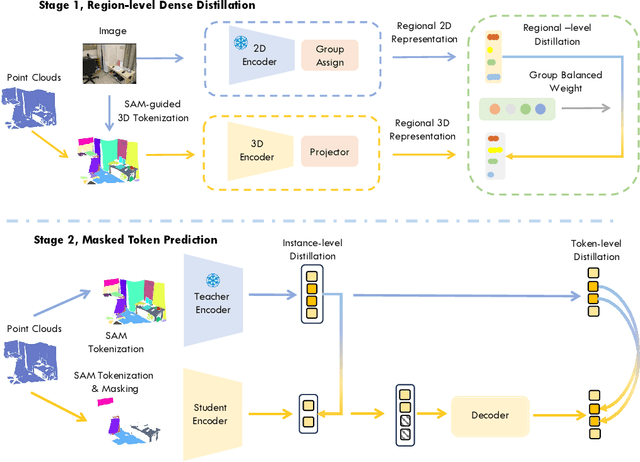

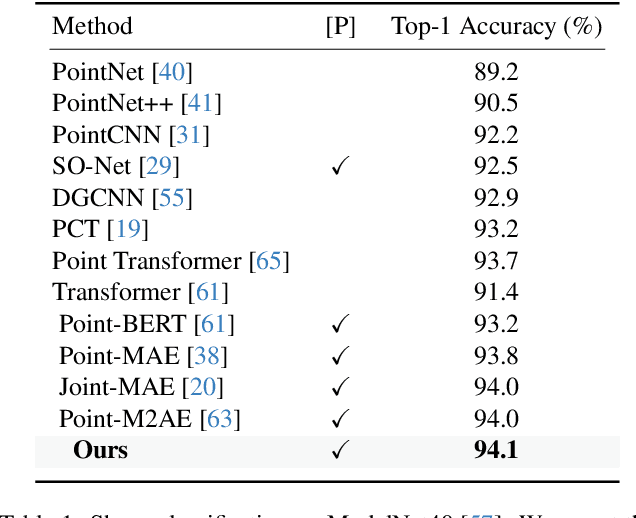
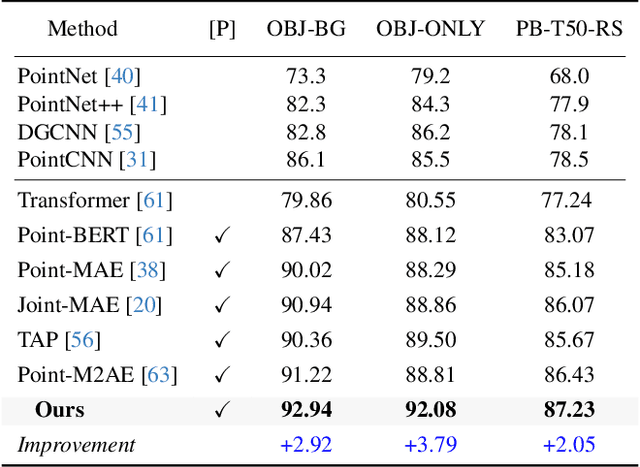
Foundation models have significantly enhanced 2D task performance, and recent works like Bridge3D have successfully applied these models to improve 3D scene understanding through knowledge distillation, marking considerable advancements. Nonetheless, challenges such as the misalignment between 2D and 3D representations and the persistent long-tail distribution in 3D datasets still restrict the effectiveness of knowledge distillation from 2D to 3D using foundation models. To tackle these issues, we introduce a novel SAM-guided tokenization method that seamlessly aligns 3D transformer structures with region-level knowledge distillation, replacing the traditional KNN-based tokenization techniques. Additionally, we implement a group-balanced re-weighting strategy to effectively address the long-tail problem in knowledge distillation. Furthermore, inspired by the recent success of masked feature prediction, our framework incorporates a two-stage masked token prediction process in which the student model predicts both the global embeddings and the token-wise local embeddings derived from the teacher models trained in the first stage. Our methodology has been validated across multiple datasets, including SUN RGB-D, ScanNet, and S3DIS, for tasks like 3D object detection and semantic segmentation. The results demonstrate significant improvements over current State-of-the-art self-supervised methods, establishing new benchmarks in this field.
STT: Stateful Tracking with Transformers for Autonomous Driving
Apr 30, 2024Tracking objects in three-dimensional space is critical for autonomous driving. To ensure safety while driving, the tracker must be able to reliably track objects across frames and accurately estimate their states such as velocity and acceleration in the present. Existing works frequently focus on the association task while either neglecting the model performance on state estimation or deploying complex heuristics to predict the states. In this paper, we propose STT, a Stateful Tracking model built with Transformers, that can consistently track objects in the scenes while also predicting their states accurately. STT consumes rich appearance, geometry, and motion signals through long term history of detections and is jointly optimized for both data association and state estimation tasks. Since the standard tracking metrics like MOTA and MOTP do not capture the combined performance of the two tasks in the wider spectrum of object states, we extend them with new metrics called S-MOTA and MOTPS that address this limitation. STT achieves competitive real-time performance on the Waymo Open Dataset.
3D Open-Vocabulary Panoptic Segmentation with 2D-3D Vision-Language Distillation
Jan 04, 2024



3D panoptic segmentation is a challenging perception task, which aims to predict both semantic and instance annotations for 3D points in a scene. Although prior 3D panoptic segmentation approaches have achieved great performance on closed-set benchmarks, generalizing to novel categories remains an open problem. For unseen object categories, 2D open-vocabulary segmentation has achieved promising results that solely rely on frozen CLIP backbones and ensembling multiple classification outputs. However, we find that simply extending these 2D models to 3D does not achieve good performance due to poor per-mask classification quality on novel categories. In this paper, we propose the first method to tackle 3D open-vocabulary panoptic segmentation. Our model takes advantage of the fusion between learnable LiDAR features and dense frozen vision CLIP features, using a single classification head to make predictions for both base and novel classes. To further improve the classification performance on novel classes and leverage the CLIP model, we propose two novel loss functions: object-level distillation loss and voxel-level distillation loss. Our experiments on the nuScenes and SemanticKITTI datasets show that our method outperforms strong baselines by a large margin.
Point Cloud Self-supervised Learning via 3D to Multi-view Masked Autoencoder
Nov 17, 2023

In recent years, the field of 3D self-supervised learning has witnessed significant progress, resulting in the emergence of Multi-Modality Masked AutoEncoders (MAE) methods that leverage both 2D images and 3D point clouds for pre-training. However, a notable limitation of these approaches is that they do not fully utilize the multi-view attributes inherent in 3D point clouds, which is crucial for a deeper understanding of 3D structures. Building upon this insight, we introduce a novel approach employing a 3D to multi-view masked autoencoder to fully harness the multi-modal attributes of 3D point clouds. To be specific, our method uses the encoded tokens from 3D masked point clouds to generate original point clouds and multi-view depth images across various poses. This approach not only enriches the model's comprehension of geometric structures but also leverages the inherent multi-modal properties of point clouds. Our experiments illustrate the effectiveness of the proposed method for different tasks and under different settings. Remarkably, our method outperforms state-of-the-art counterparts by a large margin in a variety of downstream tasks, including 3D object classification, few-shot learning, part segmentation, and 3D object detection. Code will be available at: https://github.com/Zhimin-C/Multiview-MAE
AsyInst: Asymmetric Affinity with DepthGrad and Color for Box-Supervised Instance Segmentation
Dec 07, 2022



The weakly supervised instance segmentation is a challenging task. The existing methods typically use bounding boxes as supervision and optimize the network with a regularization loss term such as pairwise color affinity loss for instance segmentation. Through systematic analysis, we found that the commonly used pairwise affinity loss has two limitations: (1) it works with color affinity but leads to inferior performance with other modalities such as depth gradient, (2)the original affinity loss does not prevent trivial predictions as intended but actually accelerates this process due to the affinity loss term being symmetric. To overcome these two limitations, in this paper, we propose a novel asymmetric affinity loss which provides the penalty against the trivial prediction and generalizes well with affinity loss from different modalities. With the proposed asymmetric affinity loss, our method outperforms the state-of-the-art methods on the Cityscapes dataset and outperforms our baseline method by 3.5% in mask AP.
Class-Level Confidence Based 3D Semi-Supervised Learning
Oct 18, 2022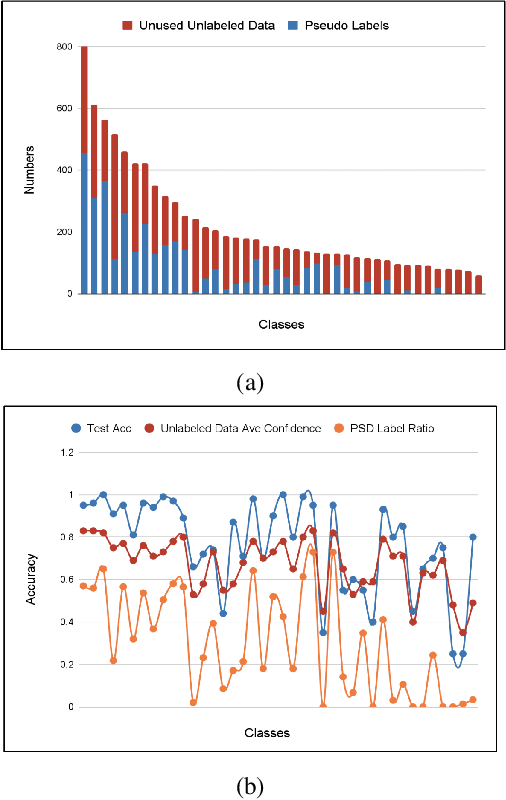
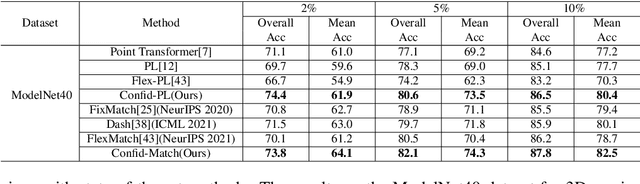
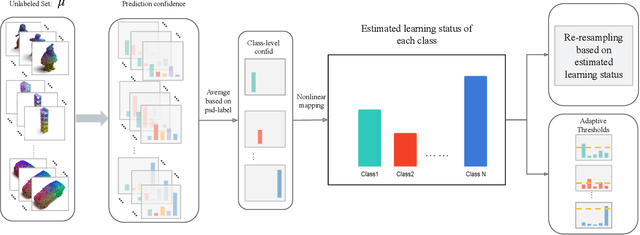
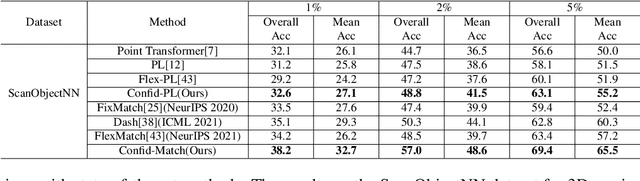
Recent state-of-the-art method FlexMatch firstly demonstrated that correctly estimating learning status is crucial for semi-supervised learning (SSL). However, the estimation method proposed by FlexMatch does not take into account imbalanced data, which is the common case for 3D semi-supervised learning. To address this problem, we practically demonstrate that unlabeled data class-level confidence can represent the learning status in the 3D imbalanced dataset. Based on this finding, we present a novel class-level confidence based 3D SSL method. Firstly, a dynamic thresholding strategy is proposed to utilize more unlabeled data, especially for low learning status classes. Then, a re-sampling strategy is designed to avoid biasing toward high learning status classes, which dynamically changes the sampling probability of each class. To show the effectiveness of our method in 3D SSL tasks, we conduct extensive experiments on 3D SSL classification and detection tasks. Our method significantly outperforms state-of-the-art counterparts for both 3D SSL classification and detection tasks in all datasets.
R4D: Utilizing Reference Objects for Long-Range Distance Estimation
Jun 10, 2022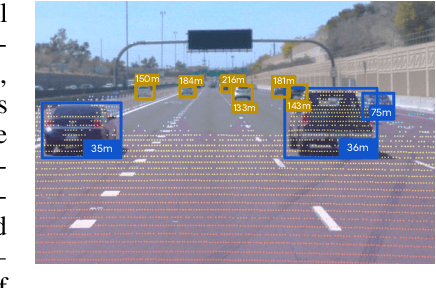

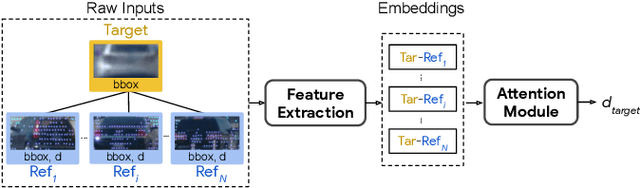
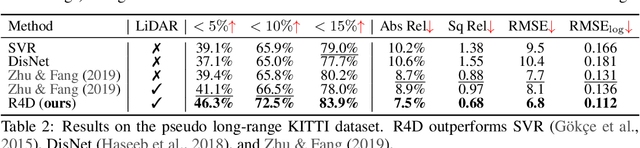
Estimating the distance of objects is a safety-critical task for autonomous driving. Focusing on short-range objects, existing methods and datasets neglect the equally important long-range objects. In this paper, we introduce a challenging and under-explored task, which we refer to as Long-Range Distance Estimation, as well as two datasets to validate new methods developed for this task. We then proposeR4D, the first framework to accurately estimate the distance of long-range objects by using references with known distances in the scene. Drawing inspiration from human perception, R4D builds a graph by connecting a target object to all references. An edge in the graph encodes the relative distance information between a pair of target and reference objects. An attention module is then used to weigh the importance of reference objects and combine them into one target object distance prediction. Experiments on the two proposed datasets demonstrate the effectiveness and robustness of R4D by showing significant improvements compared to existing baselines. We are looking to make the proposed dataset, Waymo OpenDataset - Long-Range Labels, available publicly at waymo.com/open/download.
Depth Estimation Matters Most: Improving Per-Object Depth Estimation for Monocular 3D Detection and Tracking
Jun 08, 2022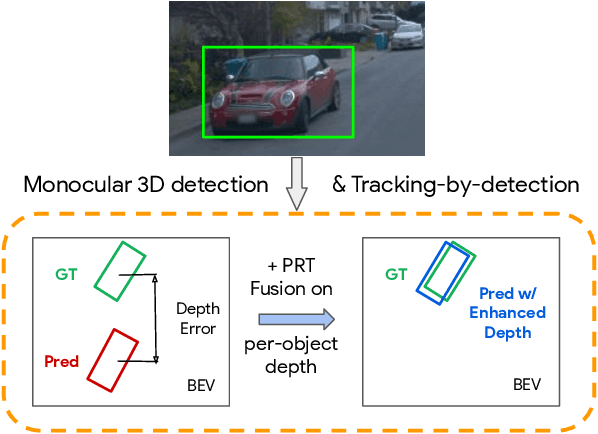
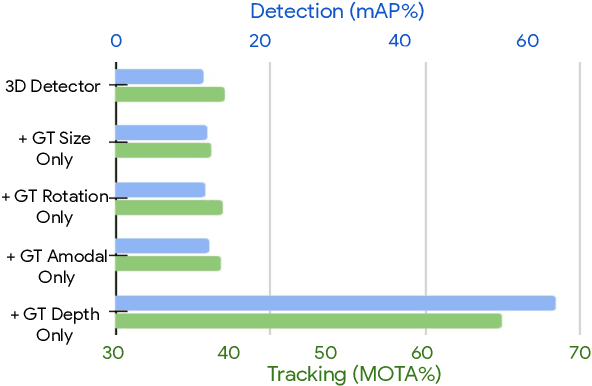
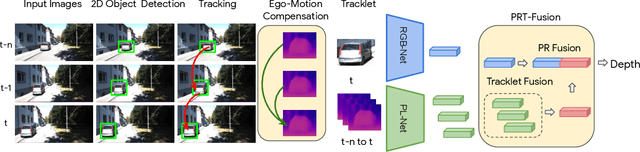
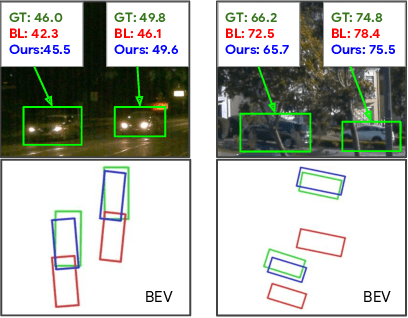
Monocular image-based 3D perception has become an active research area in recent years owing to its applications in autonomous driving. Approaches to monocular 3D perception including detection and tracking, however, often yield inferior performance when compared to LiDAR-based techniques. Through systematic analysis, we identified that per-object depth estimation accuracy is a major factor bounding the performance. Motivated by this observation, we propose a multi-level fusion method that combines different representations (RGB and pseudo-LiDAR) and temporal information across multiple frames for objects (tracklets) to enhance per-object depth estimation. Our proposed fusion method achieves the state-of-the-art performance of per-object depth estimation on the Waymo Open Dataset, the KITTI detection dataset, and the KITTI MOT dataset. We further demonstrate that by simply replacing estimated depth with fusion-enhanced depth, we can achieve significant improvements in monocular 3D perception tasks, including detection and tracking.
Disentangling Object Motion and Occlusion for Unsupervised Multi-frame Monocular Depth
Mar 29, 2022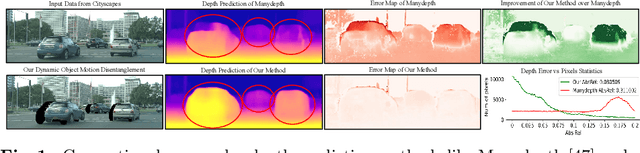
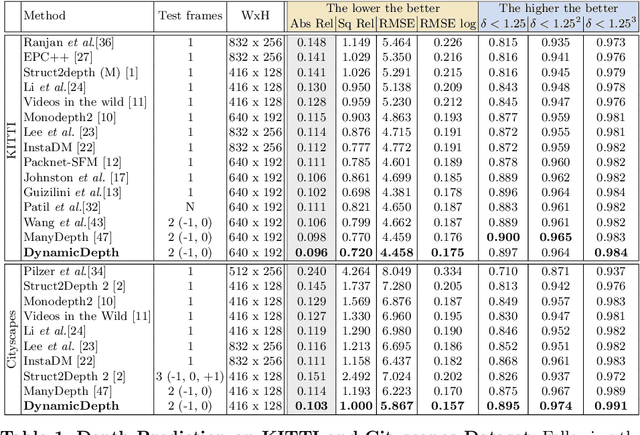
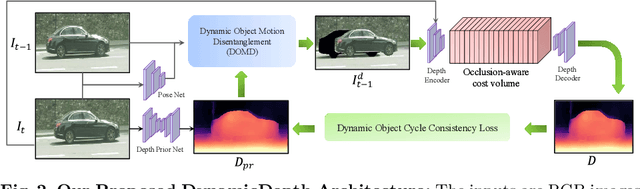
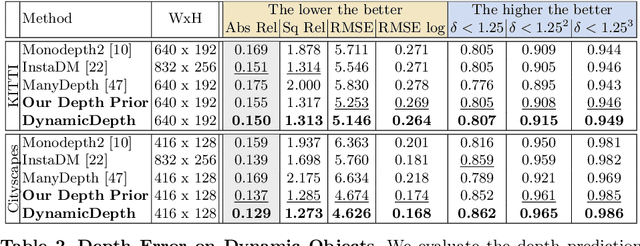
Conventional self-supervised monocular depth prediction methods are based on a static environment assumption, which leads to accuracy degradation in dynamic scenes due to the mismatch and occlusion problems introduced by object motions. Existing dynamic-object-focused methods only partially solved the mismatch problem at the training loss level. In this paper, we accordingly propose a novel multi-frame monocular depth prediction method to solve these problems at both the prediction and supervision loss levels. Our method, called DynamicDepth, is a new framework trained via a self-supervised cycle consistent learning scheme. A Dynamic Object Motion Disentanglement (DOMD) module is proposed to disentangle object motions to solve the mismatch problem. Moreover, novel occlusion-aware Cost Volume and Re-projection Loss are designed to alleviate the occlusion effects of object motions. Extensive analyses and experiments on the Cityscapes and KITTI datasets show that our method significantly outperforms the state-of-the-art monocular depth prediction methods, especially in the areas of dynamic objects. Our code will be made publicly available.
Learning from Temporal Gradient for Semi-supervised Action Recognition
Dec 06, 2021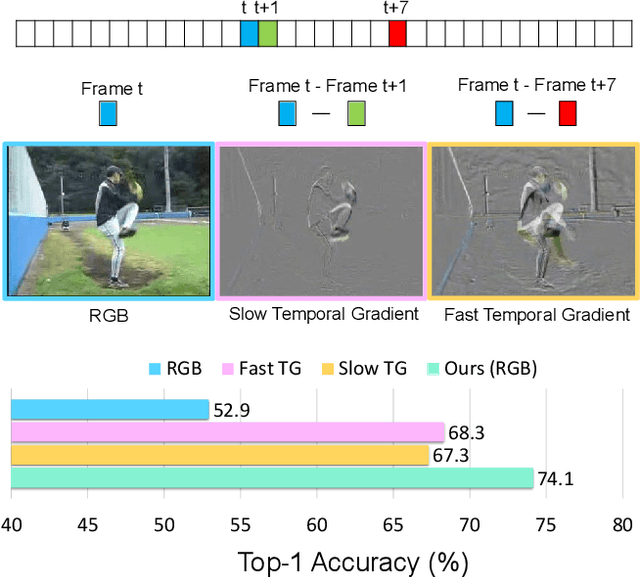
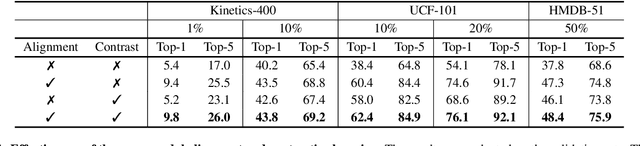
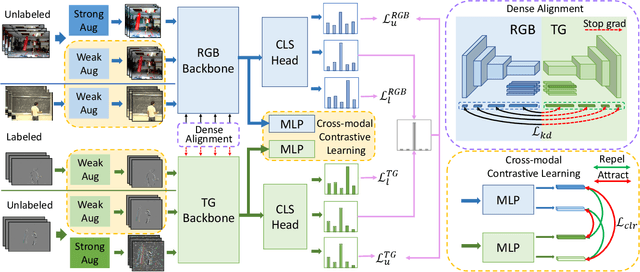
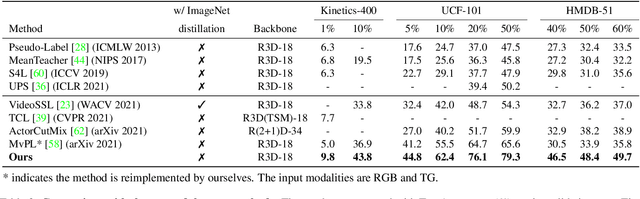
Semi-supervised video action recognition tends to enable deep neural networks to achieve remarkable performance even with very limited labeled data. However, existing methods are mainly transferred from current image-based methods (e.g., FixMatch). Without specifically utilizing the temporal dynamics and inherent multimodal attributes, their results could be suboptimal. To better leverage the encoded temporal information in videos, we introduce temporal gradient as an additional modality for more attentive feature extraction in this paper. To be specific, our method explicitly distills the fine-grained motion representations from temporal gradient (TG) and imposes consistency across different modalities (i.e., RGB and TG). The performance of semi-supervised action recognition is significantly improved without additional computation or parameters during inference. Our method achieves the state-of-the-art performance on three video action recognition benchmarks (i.e., Kinetics-400, UCF-101, and HMDB-51) under several typical semi-supervised settings (i.e., different ratios of labeled data).