 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREL-SF4PASS: Panoramic Semantic Segmentation with REL Depth Representation and Spherical Fusion
Jan 23, 2026As an important and challenging problem in computer vision, Panoramic Semantic Segmentation (PASS) aims to give complete scene perception based on an ultra-wide angle of view. Most PASS methods often focus on spherical geometry with RGB input or using the depth information in original or HHA format, which does not make full use of panoramic image geometry. To address these shortcomings, we propose REL-SF4PASS with our REL depth representation based on cylindrical coordinate and Spherical-dynamic Multi-Modal Fusion SMMF. REL is made up of Rectified Depth, Elevation-Gained Vertical Inclination Angle, and Lateral Orientation Angle, which fully represents 3D space in cylindrical coordinate style and the surface normal direction. SMMF aims to ensure the diversity of fusion for different panoramic image regions and reduce the breakage of cylinder side surface expansion in ERP projection, which uses different fusion strategies to match the different regions in panoramic images. Experimental results show that REL-SF4PASS considerably improves performance and robustness on popular benchmark, Stanford2D3D Panoramic datasets. It gains 2.35% average mIoU improvement on all 3 folds and reduces the performance variance by approximately 70% when facing 3D disturbance.
What Happens Next? Next Scene Prediction with a Unified Video Model
Dec 15, 2025



Recent unified models for joint understanding and generation have significantly advanced visual generation capabilities. However, their focus on conventional tasks like text-to-video generation has left the temporal reasoning potential of unified models largely underexplored. To address this gap, we introduce Next Scene Prediction (NSP), a new task that pushes unified video models toward temporal and causal reasoning. Unlike text-to-video generation, NSP requires predicting plausible futures from preceding context, demanding deeper understanding and reasoning. To tackle this task, we propose a unified framework combining Qwen-VL for comprehension and LTX for synthesis, bridged by a latent query embedding and a connector module. This model is trained in three stages on our newly curated, large-scale NSP dataset: text-to-video pre-training, supervised fine-tuning, and reinforcement learning (via GRPO) with our proposed causal consistency reward. Experiments demonstrate our model achieves state-of-the-art performance on our benchmark, advancing the capability of generalist multimodal systems to anticipate what happens next.
Limits To (Machine) Learning
Dec 14, 2025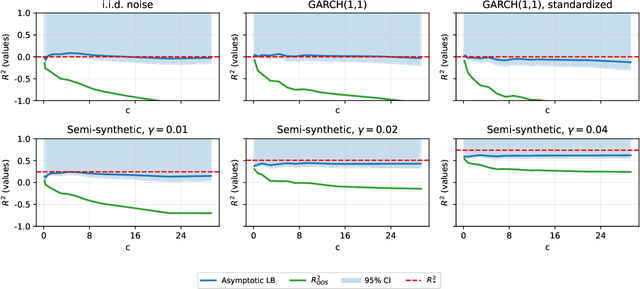



Machine learning (ML) methods are highly flexible, but their ability to approximate the true data-generating process is fundamentally constrained by finite samples. We characterize a universal lower bound, the Limits-to-Learning Gap (LLG), quantifying the unavoidable discrepancy between a model's empirical fit and the population benchmark. Recovering the true population $R^2$, therefore, requires correcting observed predictive performance by this bound. Using a broad set of variables, including excess returns, yields, credit spreads, and valuation ratios, we find that the implied LLGs are large. This indicates that standard ML approaches can substantially understate true predictability in financial data. We also derive LLG-based refinements to the classic Hansen and Jagannathan (1991) bounds, analyze implications for parameter learning in general-equilibrium settings, and show that the LLG provides a natural mechanism for generating excess volatility.
VIDEOP2R: Video Understanding from Perception to Reasoning
Nov 14, 2025Reinforcement fine-tuning (RFT), a two-stage framework consisting of supervised fine-tuning (SFT) and reinforcement learning (RL) has shown promising results on improving reasoning ability of large language models (LLMs). Yet extending RFT to large video language models (LVLMs) remains challenging. We propose VideoP2R, a novel process-aware video RFT framework that enhances video reasoning by modeling perception and reasoning as distinct processes. In the SFT stage, we develop a three-step pipeline to generate VideoP2R-CoT-162K, a high-quality, process-aware chain-of-thought (CoT) dataset for perception and reasoning. In the RL stage, we introduce a novel process-aware group relative policy optimization (PA-GRPO) algorithm that supplies separate rewards for perception and reasoning. Extensive experiments show that VideoP2R achieves state-of-the-art (SotA) performance on six out of seven video reasoning and understanding benchmarks. Ablation studies further confirm the effectiveness of our process-aware modeling and PA-GRPO and demonstrate that model's perception output is information-sufficient for downstream reasoning.
DyConfidMatch: Dynamic Thresholding and Re-sampling for 3D Semi-supervised Learning
Nov 13, 2024



Semi-supervised learning (SSL) leverages limited labeled and abundant unlabeled data but often faces challenges with data imbalance, especially in 3D contexts. This study investigates class-level confidence as an indicator of learning status in 3D SSL, proposing a novel method that utilizes dynamic thresholding to better use unlabeled data, particularly from underrepresented classes. A re-sampling strategy is also introduced to mitigate bias towards well-represented classes, ensuring equitable class representation. Through extensive experiments in 3D SSL, our method surpasses state-of-the-art counterparts in classification and detection tasks, highlighting its effectiveness in tackling data imbalance. This approach presents a significant advancement in SSL for 3D datasets, providing a robust solution for data imbalance issues.
SAM-Guided Masked Token Prediction for 3D Scene Understanding
Oct 17, 2024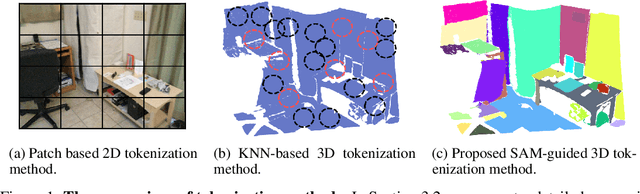

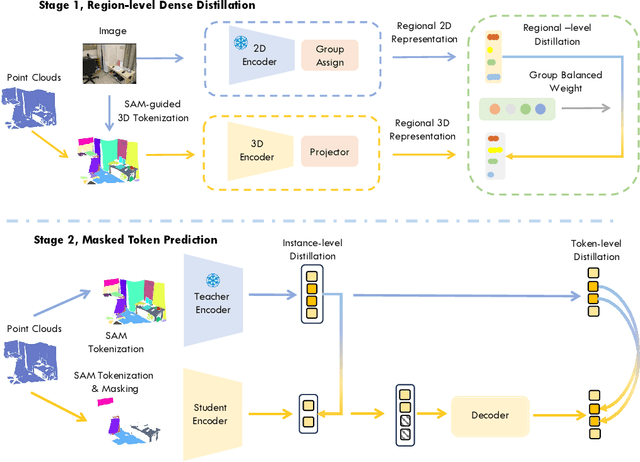

Foundation models have significantly enhanced 2D task performance, and recent works like Bridge3D have successfully applied these models to improve 3D scene understanding through knowledge distillation, marking considerable advancements. Nonetheless, challenges such as the misalignment between 2D and 3D representations and the persistent long-tail distribution in 3D datasets still restrict the effectiveness of knowledge distillation from 2D to 3D using foundation models. To tackle these issues, we introduce a novel SAM-guided tokenization method that seamlessly aligns 3D transformer structures with region-level knowledge distillation, replacing the traditional KNN-based tokenization techniques. Additionally, we implement a group-balanced re-weighting strategy to effectively address the long-tail problem in knowledge distillation. Furthermore, inspired by the recent success of masked feature prediction, our framework incorporates a two-stage masked token prediction process in which the student model predicts both the global embeddings and the token-wise local embeddings derived from the teacher models trained in the first stage. Our methodology has been validated across multiple datasets, including SUN RGB-D, ScanNet, and S3DIS, for tasks like 3D object detection and semantic segmentation. The results demonstrate significant improvements over current State-of-the-art self-supervised methods, establishing new benchmarks in this field.
End-To-End Training and Testing Gamification Framework to Learn Human Highway Driving
Apr 18, 2024The current autonomous stack is well modularized and consists of perception, decision making and control in a handcrafted framework. With the advances in artificial intelligence (AI) and computing resources, researchers have been pushing the development of end-to-end AI for autonomous driving, at least in problems of small searching space such as in highway scenarios, and more and more photorealistic simulation will be critical for efficient learning. In this research, we propose a novel game-based end-to-end learning and testing framework for autonomous vehicle highway driving, by learning from human driving skills. Firstly, we utilize the popular game Grand Theft Auto V (GTA V) to collect highway driving data with our proposed programmable labels. Then, an end-to-end architecture predicts the steering and throttle values that control the vehicle by the image of the game screen. The predicted control values are sent to the game via a virtual controller to keep the vehicle in lane and avoid collisions with other vehicles on the road. The proposed solution is validated in GTA V games, and the results demonstrate the effectiveness of this end-to-end gamification framework for learning human driving skills.
Point Cloud Self-supervised Learning via 3D to Multi-view Masked Autoencoder
Nov 17, 2023
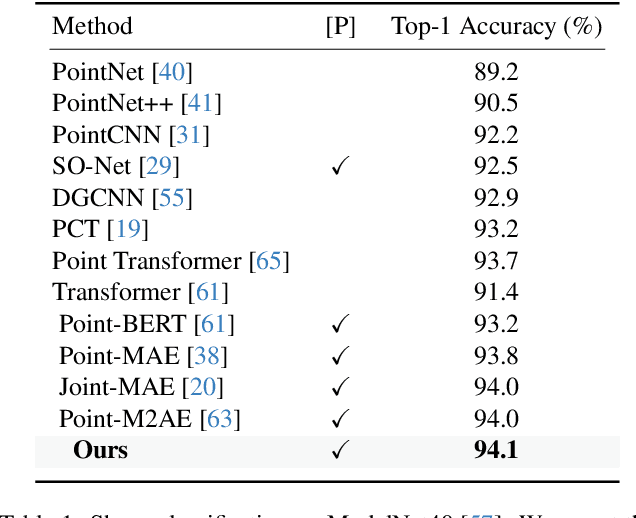

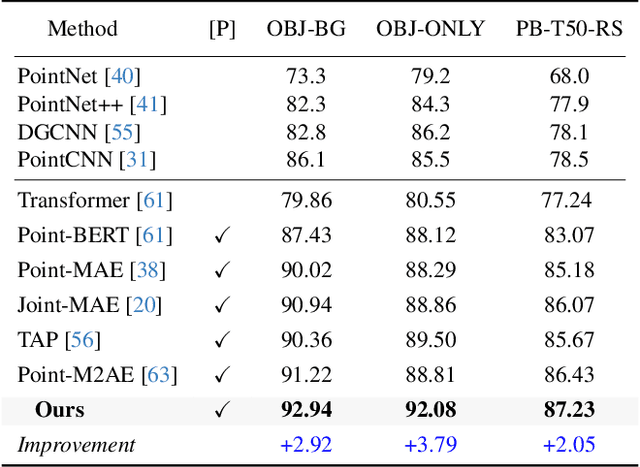
In recent years, the field of 3D self-supervised learning has witnessed significant progress, resulting in the emergence of Multi-Modality Masked AutoEncoders (MAE) methods that leverage both 2D images and 3D point clouds for pre-training. However, a notable limitation of these approaches is that they do not fully utilize the multi-view attributes inherent in 3D point clouds, which is crucial for a deeper understanding of 3D structures. Building upon this insight, we introduce a novel approach employing a 3D to multi-view masked autoencoder to fully harness the multi-modal attributes of 3D point clouds. To be specific, our method uses the encoded tokens from 3D masked point clouds to generate original point clouds and multi-view depth images across various poses. This approach not only enriches the model's comprehension of geometric structures but also leverages the inherent multi-modal properties of point clouds. Our experiments illustrate the effectiveness of the proposed method for different tasks and under different settings. Remarkably, our method outperforms state-of-the-art counterparts by a large margin in a variety of downstream tasks, including 3D object classification, few-shot learning, part segmentation, and 3D object detection. Code will be available at: https://github.com/Zhimin-C/Multiview-MAE
EGraFFBench: Evaluation of Equivariant Graph Neural Network Force Fields for Atomistic Simulations
Oct 03, 2023
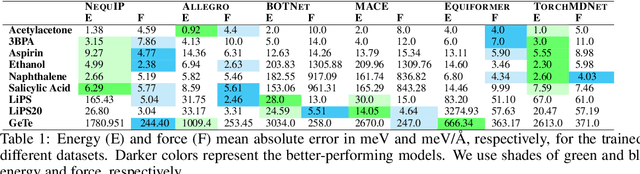
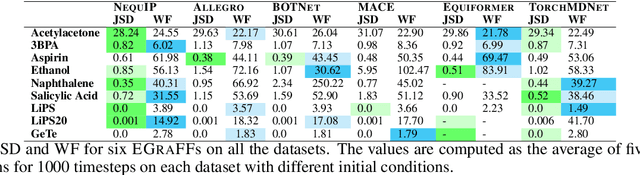
Equivariant graph neural networks force fields (EGraFFs) have shown great promise in modelling complex interactions in atomic systems by exploiting the graphs' inherent symmetries. Recent works have led to a surge in the development of novel architectures that incorporate equivariance-based inductive biases alongside architectural innovations like graph transformers and message passing to model atomic interactions. However, thorough evaluations of these deploying EGraFFs for the downstream task of real-world atomistic simulations, is lacking. To this end, here we perform a systematic benchmarking of 6 EGraFF algorithms (NequIP, Allegro, BOTNet, MACE, Equiformer, TorchMDNet), with the aim of understanding their capabilities and limitations for realistic atomistic simulations. In addition to our thorough evaluation and analysis on eight existing datasets based on the benchmarking literature, we release two new benchmark datasets, propose four new metrics, and three new challenging tasks. The new datasets and tasks evaluate the performance of EGraFF to out-of-distribution data, in terms of different crystal structures, temperatures, and new molecules. Interestingly, evaluation of the EGraFF models based on dynamic simulations reveals that having a lower error on energy or force does not guarantee stable or reliable simulation or faithful replication of the atomic structures. Moreover, we find that no model clearly outperforms other models on all datasets and tasks. Importantly, we show that the performance of all the models on out-of-distribution datasets is unreliable, pointing to the need for the development of a foundation model for force fields that can be used in real-world simulations. In summary, this work establishes a rigorous framework for evaluating machine learning force fields in the context of atomic simulations and points to open research challenges within this domain.
DNN-DANM: A High-Accuracy Two-Dimensional DOA Estimation Method Using Practical RIS
Sep 25, 2023



Reconfigurable intelligent surface (RIS) or intelligent reflecting surface (IRS) has been an attractive technology for future wireless communication and sensing systems. However, in the practical RIS, the mutual coupling effect among RIS elements, the reflection phase shift, and amplitude errors will degrade the RIS performance significantly. This paper investigates the two-dimensional direction-of-arrival (DOA) estimation problem in the scenario using a practical RIS. After formulating the system model with the mutual coupling effect and the reflection phase/amplitude errors of the RIS, a novel DNNDANM method is proposed for the DOA estimation by combining the deep neural network (DNN) and the decoupling atomic norm minimization (DANM). The DNN step reconstructs the received signal from the one with RIS impairments, and the DANM step exploits the signal sparsity in the two-dimensional spatial domain. Additionally, a semi-definite programming (SDP) method with low computational complexity is proposed to solve the atomic minimization problem. Finally, both simulation and prototype are carried out to show estimation performance, and the proposed method outperforms the existing methods in the two-dimensional DOA estimation with low complexity in the scenario with practical RIS.
* 11 pages, 12 figures