 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Self-supervised Learning via 3D to Multi-view Masked Autoencoder
Paper and Code

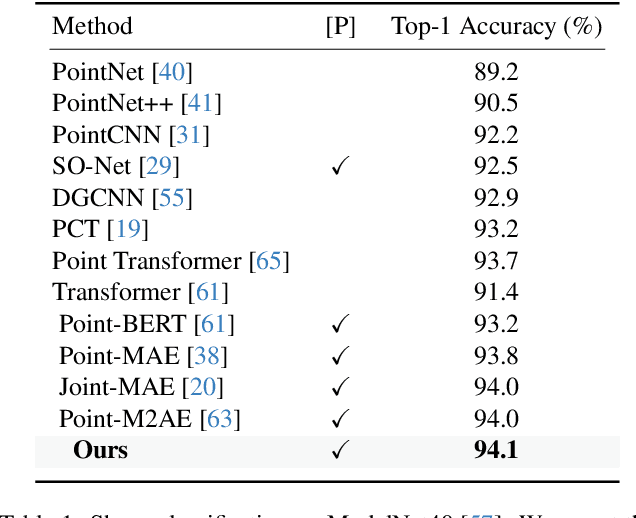

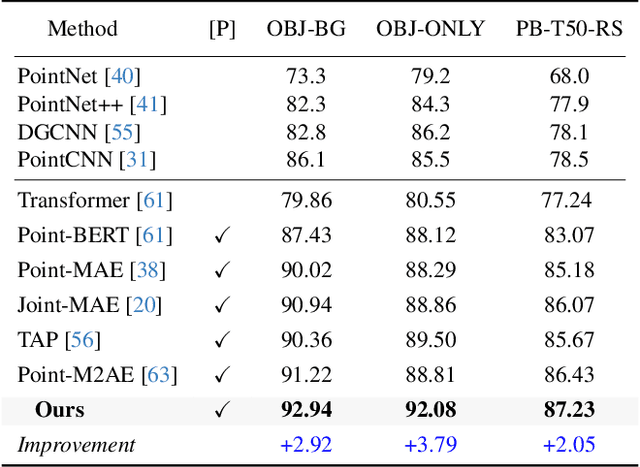
In recent years, the field of 3D self-supervised learning has witnessed significant progress, resulting in the emergence of Multi-Modality Masked AutoEncoders (MAE) methods that leverage both 2D images and 3D point clouds for pre-training. However, a notable limitation of these approaches is that they do not fully utilize the multi-view attributes inherent in 3D point clouds, which is crucial for a deeper understanding of 3D structures. Building upon this insight, we introduce a novel approach employing a 3D to multi-view masked autoencoder to fully harness the multi-modal attributes of 3D point clouds. To be specific, our method uses the encoded tokens from 3D masked point clouds to generate original point clouds and multi-view depth images across various poses. This approach not only enriches the model's comprehension of geometric structures but also leverages the inherent multi-modal properties of point clouds. Our experiments illustrate the effectiveness of the proposed method for different tasks and under different settings. Remarkably, our method outperforms state-of-the-art counterparts by a large margin in a variety of downstream tasks, including 3D object classification, few-shot learning, part segmentation, and 3D object detection. Code will be available at: https://github.com/Zhimin-C/Multiview-MAE