 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIT: A Large-Scale Dataset for Fit-Aware Virtual Try-On
Apr 09, 2026Given a person and a garment image, virtual try-on (VTO) aims to synthesize a realistic image of the person wearing the garment, while preserving their original pose and identity. Although recent VTO methods excel at visualizing garment appearance, they largely overlook a crucial aspect of the try-on experience: the accuracy of garment fit -- for example, depicting how an extra-large shirt looks on an extra-small person. A key obstacle is the absence of datasets that provide precise garment and body size information, particularly for "ill-fit" cases, where garments are significantly too large or too small. Consequently, current VTO methods default to generating well-fitted results regardless of the garment or person size. In this paper, we take the first steps towards solving this open problem. We introduce FIT (Fit-Inclusive Try-on), a large-scale VTO dataset comprising over 1.13M try-on image triplets accompanied by precise body and garment measurements. We overcome the challenges of data collection via a scalable synthetic strategy: (1) We programmatically generate 3D garments using GarmentCode and drape them via physics simulation to capture realistic garment fit. (2) We employ a novel re-texturing framework to transform synthetic renderings into photorealistic images while strictly preserving geometry. (3) We introduce person identity preservation into our re-texturing model to generate paired person images (same person, different garments) for supervised training. Finally, we leverage our FIT dataset to train a baseline fit-aware virtual try-on model. Our data and results set the new state-of-the-art for fit-aware virtual try-on, as well as offer a robust benchmark for future research. We will make all data and code publicly available on our project page: https://johannakarras.github.io/FIT.
Pro-Pose: Unpaired Full-Body Portrait Synthesis via Canonical UV Maps
Dec 19, 2025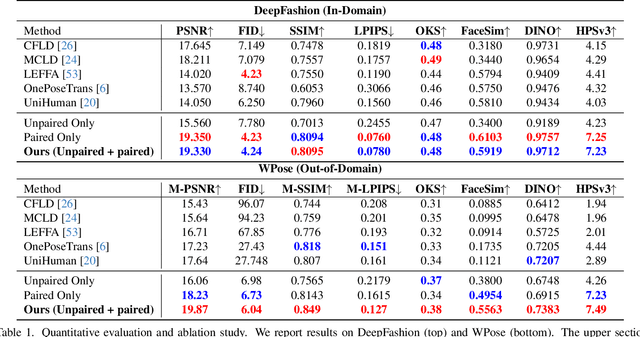
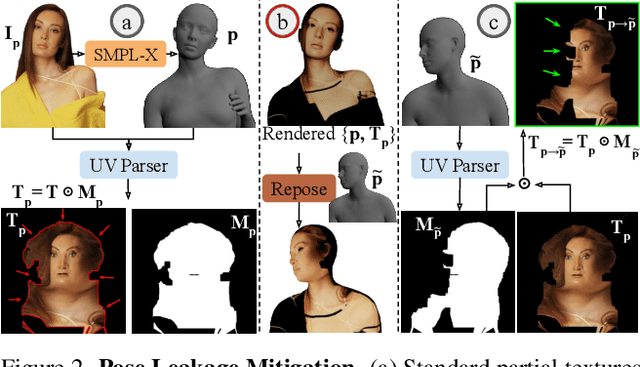
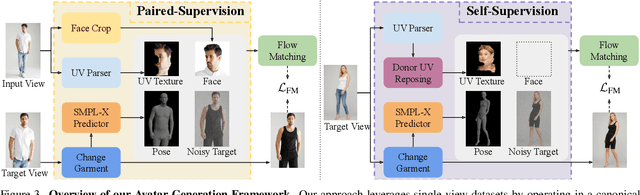

Photographs of people taken by professional photographers typically present the person in beautiful lighting, with an interesting pose, and flattering quality. This is unlike common photos people can take of themselves. In this paper, we explore how to create a ``professional'' version of a person's photograph, i.e., in a chosen pose, in a simple environment, with good lighting, and standard black top/bottom clothing. A key challenge is to preserve the person's unique identity, face and body features while transforming the photo. If there would exist a large paired dataset of the same person photographed both ``in the wild'' and by a professional photographer, the problem would potentially be easier to solve. However, such data does not exist, especially for a large variety of identities. To that end, we propose two key insights: 1) Our method transforms the input photo and person's face to a canonical UV space, which is further coupled with reposing methodology to model occlusions and novel view synthesis. Operating in UV space allows us to leverage existing unpaired datasets. 2) We personalize the output photo via multi image finetuning. Our approach yields high-quality, reposed portraits and achieves strong qualitative and quantitative performance on real-world imagery.
Fashion-VDM: Video Diffusion Model for Virtual Try-On
Nov 04, 2024
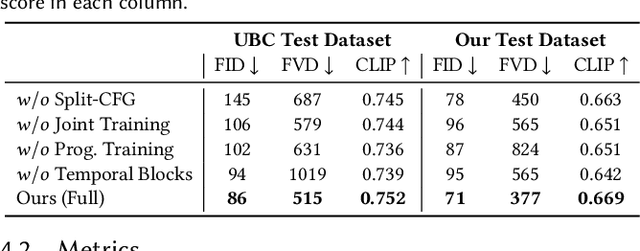
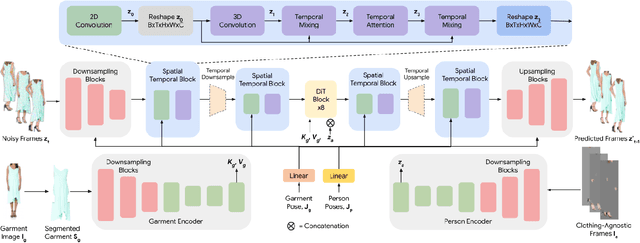
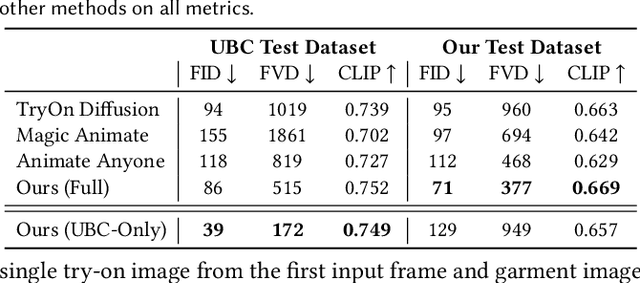
We present Fashion-VDM, a video diffusion model (VDM) for generating virtual try-on videos. Given an input garment image and person video, our method aims to generate a high-quality try-on video of the person wearing the given garment, while preserving the person's identity and motion. Image-based virtual try-on has shown impressive results; however, existing video virtual try-on (VVT) methods are still lacking garment details and temporal consistency. To address these issues, we propose a diffusion-based architecture for video virtual try-on, split classifier-free guidance for increased control over the conditioning inputs, and a progressive temporal training strategy for single-pass 64-frame, 512px video generation. We also demonstrate the effectiveness of joint image-video training for video try-on, especially when video data is limited. Our qualitative and quantitative experiments show that our approach sets the new state-of-the-art for video virtual try-on. For additional results, visit our project page: https://johannakarras.github.io/Fashion-VDM.
SAM-Guided Masked Token Prediction for 3D Scene Understanding
Oct 17, 2024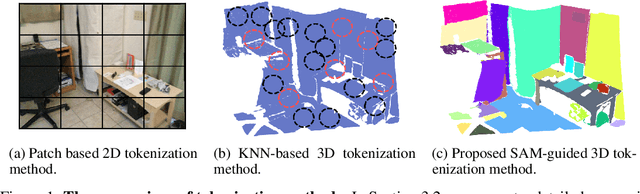

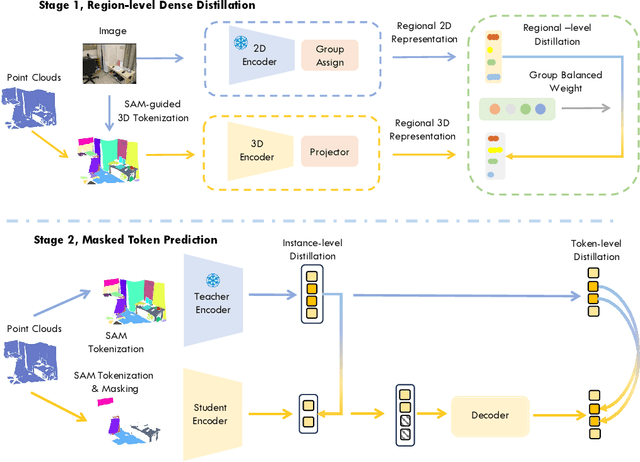

Foundation models have significantly enhanced 2D task performance, and recent works like Bridge3D have successfully applied these models to improve 3D scene understanding through knowledge distillation, marking considerable advancements. Nonetheless, challenges such as the misalignment between 2D and 3D representations and the persistent long-tail distribution in 3D datasets still restrict the effectiveness of knowledge distillation from 2D to 3D using foundation models. To tackle these issues, we introduce a novel SAM-guided tokenization method that seamlessly aligns 3D transformer structures with region-level knowledge distillation, replacing the traditional KNN-based tokenization techniques. Additionally, we implement a group-balanced re-weighting strategy to effectively address the long-tail problem in knowledge distillation. Furthermore, inspired by the recent success of masked feature prediction, our framework incorporates a two-stage masked token prediction process in which the student model predicts both the global embeddings and the token-wise local embeddings derived from the teacher models trained in the first stage. Our methodology has been validated across multiple datasets, including SUN RGB-D, ScanNet, and S3DIS, for tasks like 3D object detection and semantic segmentation. The results demonstrate significant improvements over current State-of-the-art self-supervised methods, establishing new benchmarks in this field.
M&M VTO: Multi-Garment Virtual Try-On and Editing
Jun 06, 2024



We present M&M VTO, a mix and match virtual try-on method that takes as input multiple garment images, text description for garment layout and an image of a person. An example input includes: an image of a shirt, an image of a pair of pants, "rolled sleeves, shirt tucked in", and an image of a person. The output is a visualization of how those garments (in the desired layout) would look like on the given person. Key contributions of our method are: 1) a single stage diffusion based model, with no super resolution cascading, that allows to mix and match multiple garments at 1024x512 resolution preserving and warping intricate garment details, 2) architecture design (VTO UNet Diffusion Transformer) to disentangle denoising from person specific features, allowing for a highly effective finetuning strategy for identity preservation (6MB model per individual vs 4GB achieved with, e.g., dreambooth finetuning); solving a common identity loss problem in current virtual try-on methods, 3) layout control for multiple garments via text inputs specifically finetuned over PaLI-3 for virtual try-on task. Experimental results indicate that M&M VTO achieves state-of-the-art performance both qualitatively and quantitatively, as well as opens up new opportunities for virtual try-on via language-guided and multi-garment try-on.
Continual Adversarial Defense
Dec 15, 2023



In response to the rapidly evolving nature of adversarial attacks on a monthly basis, numerous defenses have been proposed to generalize against as many known attacks as possible. However, designing a defense method that can generalize to all types of attacks, including unseen ones, is not realistic because the environment in which defense systems operate is dynamic and comprises various unique attacks used by many attackers. The defense system needs to upgrade itself by utilizing few-shot defense feedback and efficient memory. Therefore, we propose the first continual adversarial defense (CAD) framework that adapts to any attacks in a dynamic scenario, where various attacks emerge stage by stage. In practice, CAD is modeled under four principles: (1) continual adaptation to new attacks without catastrophic forgetting, (2) few-shot adaptation, (3) memory-efficient adaptation, and (4) high accuracy on both clean and adversarial images. We leverage cutting-edge continual learning, few-shot learning, and ensemble learning techniques to qualify the principles. Experiments conducted on CIFAR-10 and ImageNet-100 validate the effectiveness of our approach against multiple stages of 10 modern adversarial attacks and significant improvements over 10 baseline methods. In particular, CAD is capable of quickly adapting with minimal feedback and a low cost of defense failure, while maintaining good performance against old attacks. Our research sheds light on a brand-new paradigm for continual defense adaptation against dynamic and evolving attacks.
Point Cloud Self-supervised Learning via 3D to Multi-view Masked Autoencoder
Nov 17, 2023
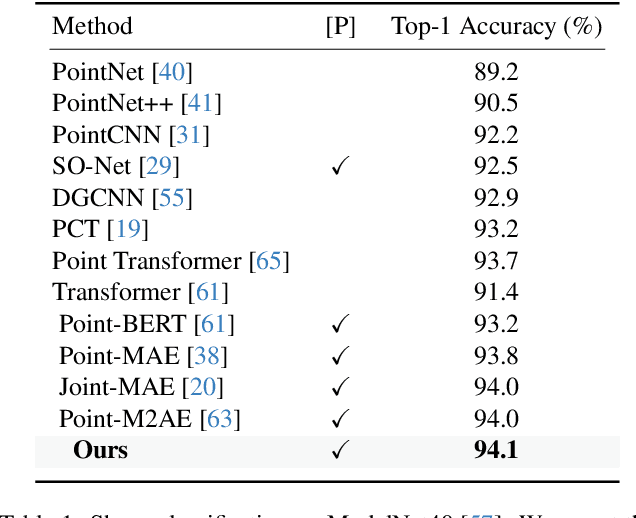

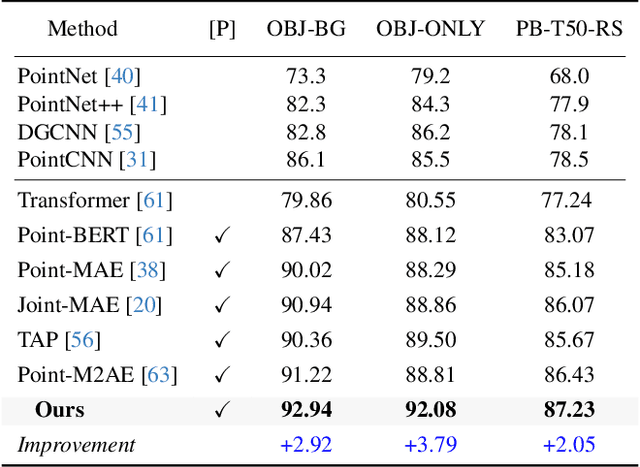
In recent years, the field of 3D self-supervised learning has witnessed significant progress, resulting in the emergence of Multi-Modality Masked AutoEncoders (MAE) methods that leverage both 2D images and 3D point clouds for pre-training. However, a notable limitation of these approaches is that they do not fully utilize the multi-view attributes inherent in 3D point clouds, which is crucial for a deeper understanding of 3D structures. Building upon this insight, we introduce a novel approach employing a 3D to multi-view masked autoencoder to fully harness the multi-modal attributes of 3D point clouds. To be specific, our method uses the encoded tokens from 3D masked point clouds to generate original point clouds and multi-view depth images across various poses. This approach not only enriches the model's comprehension of geometric structures but also leverages the inherent multi-modal properties of point clouds. Our experiments illustrate the effectiveness of the proposed method for different tasks and under different settings. Remarkably, our method outperforms state-of-the-art counterparts by a large margin in a variety of downstream tasks, including 3D object classification, few-shot learning, part segmentation, and 3D object detection. Code will be available at: https://github.com/Zhimin-C/Multiview-MAE
MoDAR: Using Motion Forecasting for 3D Object Detection in Point Cloud Sequences
Jun 05, 2023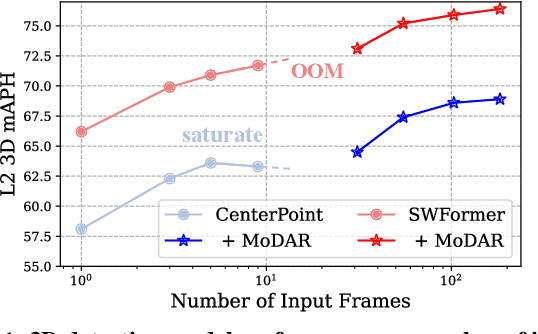
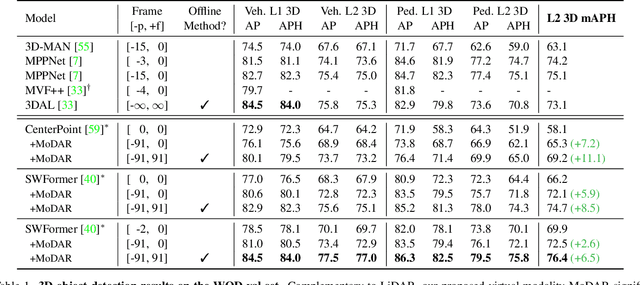
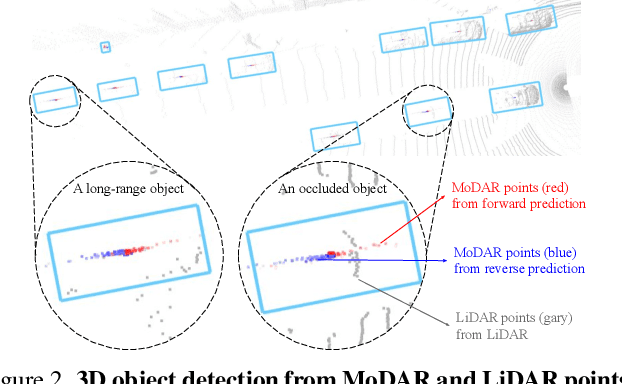
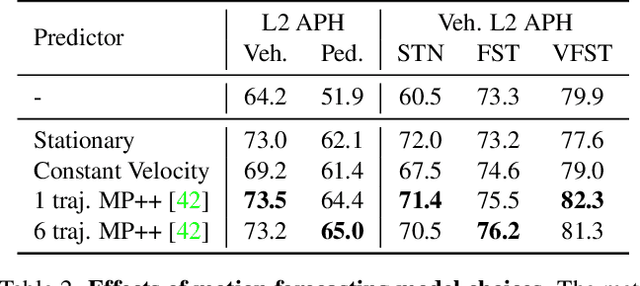
Occluded and long-range objects are ubiquitous and challenging for 3D object detection. Point cloud sequence data provide unique opportunities to improve such cases, as an occluded or distant object can be observed from different viewpoints or gets better visibility over time. However, the efficiency and effectiveness in encoding long-term sequence data can still be improved. In this work, we propose MoDAR, using motion forecasting outputs as a type of virtual modality, to augment LiDAR point clouds. The MoDAR modality propagates object information from temporal contexts to a target frame, represented as a set of virtual points, one for each object from a waypoint on a forecasted trajectory. A fused point cloud of both raw sensor points and the virtual points can then be fed to any off-the-shelf point-cloud based 3D object detector. Evaluated on the Waymo Open Dataset, our method significantly improves prior art detectors by using motion forecasting from extra-long sequences (e.g. 18 seconds), achieving new state of the arts, while not adding much computation overhead.
AsyInst: Asymmetric Affinity with DepthGrad and Color for Box-Supervised Instance Segmentation
Dec 07, 2022



The weakly supervised instance segmentation is a challenging task. The existing methods typically use bounding boxes as supervision and optimize the network with a regularization loss term such as pairwise color affinity loss for instance segmentation. Through systematic analysis, we found that the commonly used pairwise affinity loss has two limitations: (1) it works with color affinity but leads to inferior performance with other modalities such as depth gradient, (2)the original affinity loss does not prevent trivial predictions as intended but actually accelerates this process due to the affinity loss term being symmetric. To overcome these two limitations, in this paper, we propose a novel asymmetric affinity loss which provides the penalty against the trivial prediction and generalizes well with affinity loss from different modalities. With the proposed asymmetric affinity loss, our method outperforms the state-of-the-art methods on the Cityscapes dataset and outperforms our baseline method by 3.5% in mask AP.
R4D: Utilizing Reference Objects for Long-Range Distance Estimation
Jun 10, 2022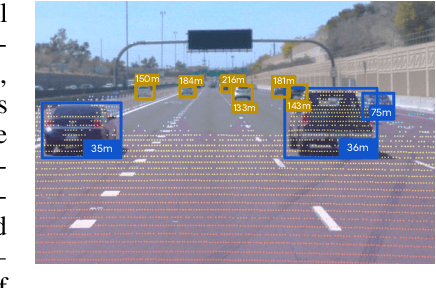

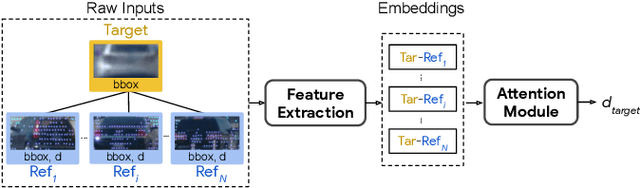
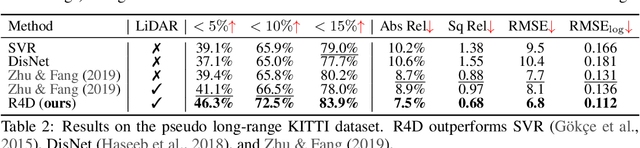
Estimating the distance of objects is a safety-critical task for autonomous driving. Focusing on short-range objects, existing methods and datasets neglect the equally important long-range objects. In this paper, we introduce a challenging and under-explored task, which we refer to as Long-Range Distance Estimation, as well as two datasets to validate new methods developed for this task. We then proposeR4D, the first framework to accurately estimate the distance of long-range objects by using references with known distances in the scene. Drawing inspiration from human perception, R4D builds a graph by connecting a target object to all references. An edge in the graph encodes the relative distance information between a pair of target and reference objects. An attention module is then used to weigh the importance of reference objects and combine them into one target object distance prediction. Experiments on the two proposed datasets demonstrate the effectiveness and robustness of R4D by showing significant improvements compared to existing baselines. We are looking to make the proposed dataset, Waymo OpenDataset - Long-Range Labels, available publicly at waymo.com/open/download.