 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Estimation Matters Most: Improving Per-Object Depth Estimation for Monocular 3D Detection and Tracking
Jun 08, 2022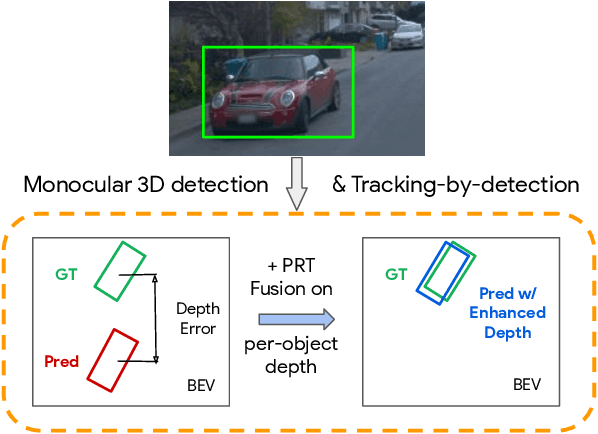
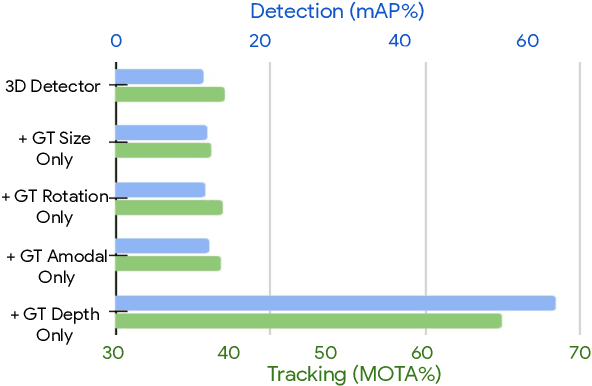
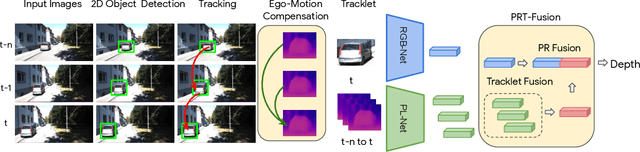
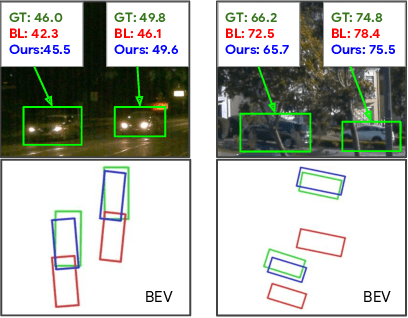
Monocular image-based 3D perception has become an active research area in recent years owing to its applications in autonomous driving. Approaches to monocular 3D perception including detection and tracking, however, often yield inferior performance when compared to LiDAR-based techniques. Through systematic analysis, we identified that per-object depth estimation accuracy is a major factor bounding the performance. Motivated by this observation, we propose a multi-level fusion method that combines different representations (RGB and pseudo-LiDAR) and temporal information across multiple frames for objects (tracklets) to enhance per-object depth estimation. Our proposed fusion method achieves the state-of-the-art performance of per-object depth estimation on the Waymo Open Dataset, the KITTI detection dataset, and the KITTI MOT dataset. We further demonstrate that by simply replacing estimated depth with fusion-enhanced depth, we can achieve significant improvements in monocular 3D perception tasks, including detection and tracking.
SMURF: Self-Teaching Multi-Frame Unsupervised RAFT with Full-Image Warping
May 14, 2021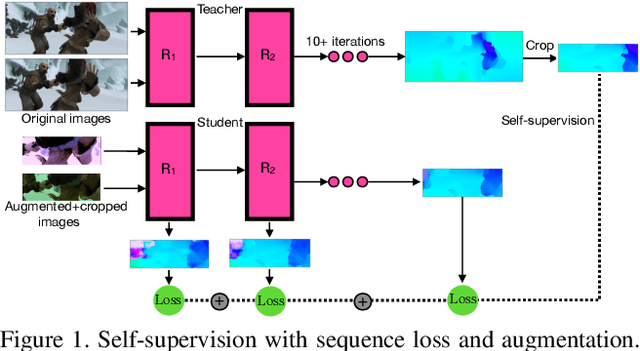
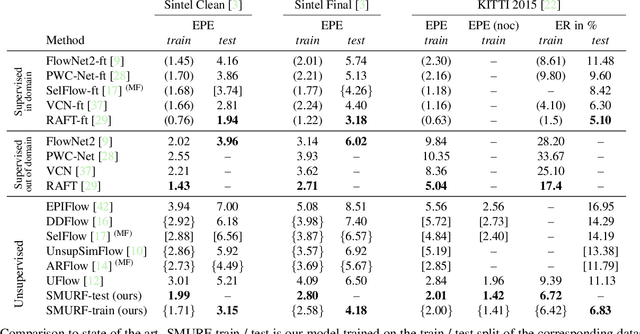
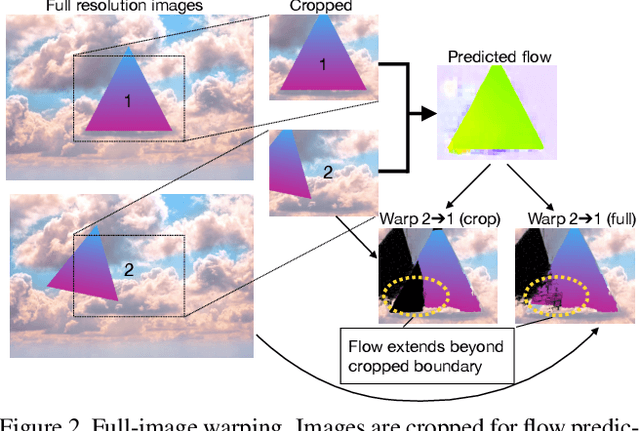
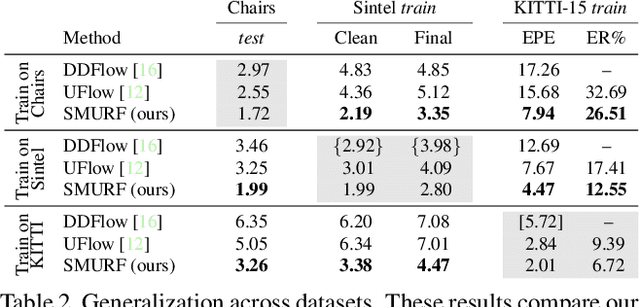
We present SMURF, a method for unsupervised learning of optical flow that improves state of the art on all benchmarks by $36\%$ to $40\%$ (over the prior best method UFlow) and even outperforms several supervised approaches such as PWC-Net and FlowNet2. Our method integrates architecture improvements from supervised optical flow, i.e. the RAFT model, with new ideas for unsupervised learning that include a sequence-aware self-supervision loss, a technique for handling out-of-frame motion, and an approach for learning effectively from multi-frame video data while still only requiring two frames for inference.
Detachable Object Detection: Segmentation and Depth Ordering From Short-Baseline Video
Sep 22, 2011


We describe an approach for segmenting an image into regions that correspond to surfaces in the scene that are partially surrounded by the medium. It integrates both appearance and motion statistics into a cost functional, that is seeded with occluded regions and minimized efficiently by solving a linear programming problem. Where a short observation time is insufficient to determine whether the object is detachable, the results of the minimization can be used to seed a more costly optimization based on a longer sequence of video data. The result is an entirely unsupervised scheme to detect and segment an arbitrary and unknown number of objects. We test our scheme to highlight the potential, as well as limitations, of our approach.