 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMURF: Self-Teaching Multi-Frame Unsupervised RAFT with Full-Image Warping
May 14, 2021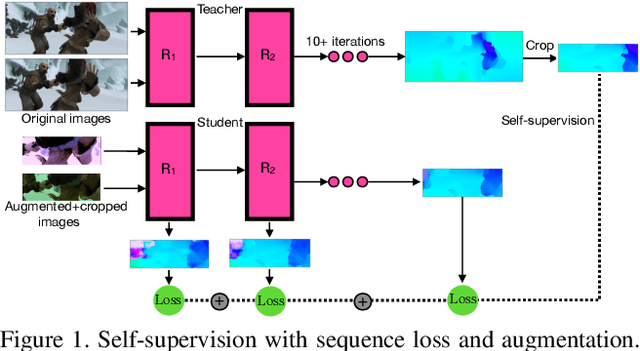
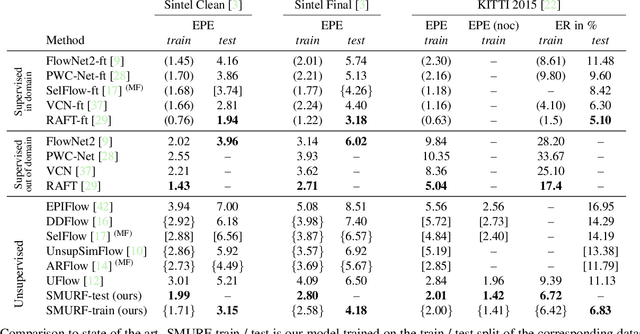
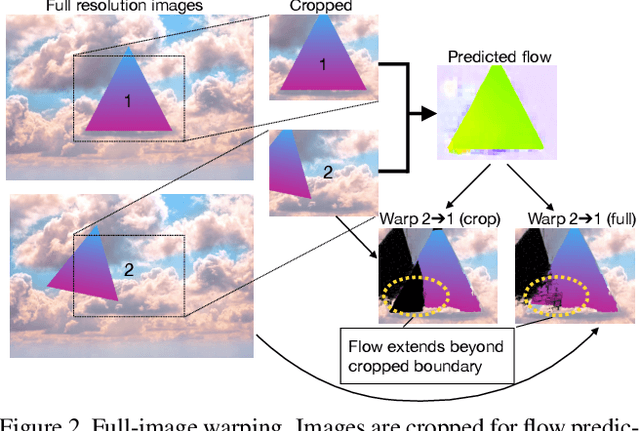
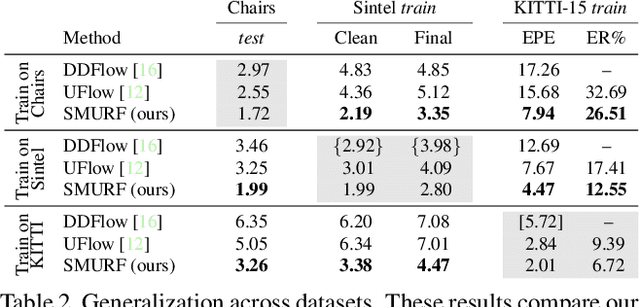
We present SMURF, a method for unsupervised learning of optical flow that improves state of the art on all benchmarks by $36\%$ to $40\%$ (over the prior best method UFlow) and even outperforms several supervised approaches such as PWC-Net and FlowNet2. Our method integrates architecture improvements from supervised optical flow, i.e. the RAFT model, with new ideas for unsupervised learning that include a sequence-aware self-supervision loss, a technique for handling out-of-frame motion, and an approach for learning effectively from multi-frame video data while still only requiring two frames for inference.
Technical Report on Visual Quality Assessment for Frame Interpolation
Jan 16, 2019



Current benchmarks for optical flow algorithms evaluate the estimation quality by comparing their predicted flow field with the ground truth, and additionally may compare interpolated frames, based on these predictions, with the correct frames from the actual image sequences. For the latter comparisons, objective measures such as mean square errors are applied. However, for applications like image interpolation, the expected user's quality of experience cannot be fully deduced from such simple quality measures. Therefore, we conducted a subjective quality assessment study by crowdsourcing for the interpolated images provided in one of the optical flow benchmarks, the Middlebury benchmark. We used paired comparisons with forced choice and reconstructed absolute quality scale values according to Thurstone's model using the classical least squares method. The results give rise to a re-ranking of 141 participating algorithms w.r.t. visual quality of interpolated frames mostly based on optical flow estimation. Our re-ranking result shows the necessity of visual quality assessment as another evaluation metric for optical flow and frame interpolation benchmarks.
ProFlow: Learning to Predict Optical Flow
Jun 03, 2018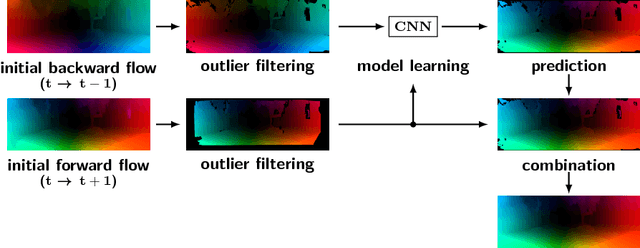
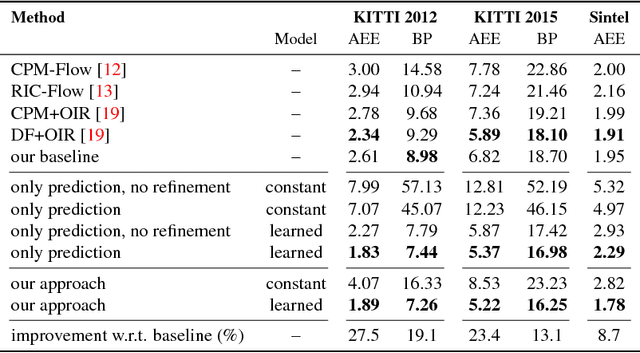
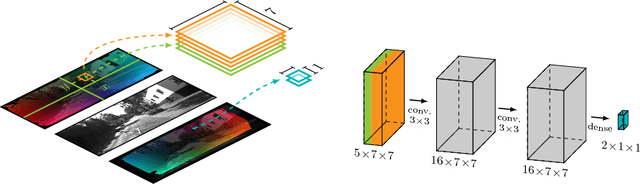
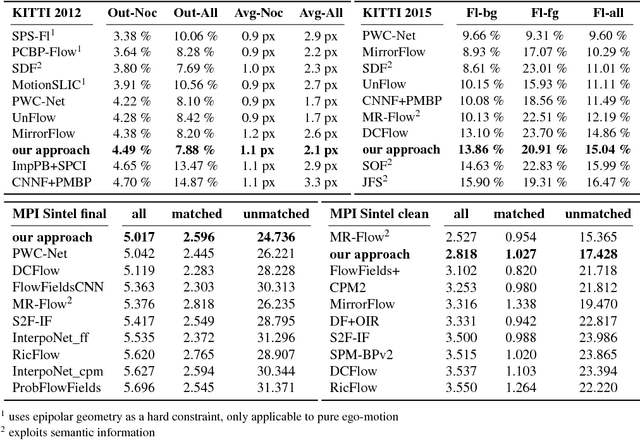
Temporal coherence is a valuable source of information in the context of optical flow estimation. However, finding a suitable motion model to leverage this information is a non-trivial task. In this paper we propose an unsupervised online learning approach based on a convolutional neural network (CNN) that estimates such a motion model individually for each frame. By relating forward and backward motion these learned models not only allow to infer valuable motion information based on the backward flow, they also help to improve the performance at occlusions, where a reliable prediction is particularly useful. Moreover, our learned models are spatially variant and hence allow to estimate non-rigid motion per construction. This, in turns, allows to overcome the major limitation of recent rigidity-based approaches that seek to improve the estimation by incorporating additional stereo/SfM constraints. Experiments demonstrate the usefulness of our new approach. They not only show a consistent improvement of up to 27% for all major benchmarks (KITTI 2012, KITTI 2015, MPI Sintel) compared to a baseline without prediction, they also show top results for the MPI Sintel benchmark -- the one of the three benchmarks that contains the largest amount of non-rigid motion.
Direct Variational Perspective Shape from Shading with Cartesian Depth Parametrisation
Jul 13, 2015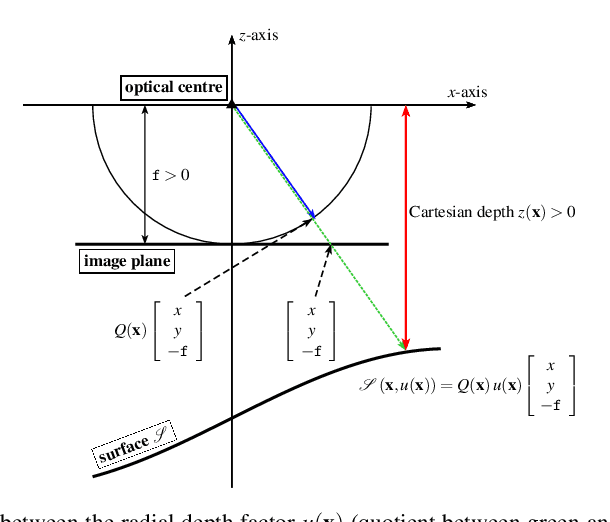

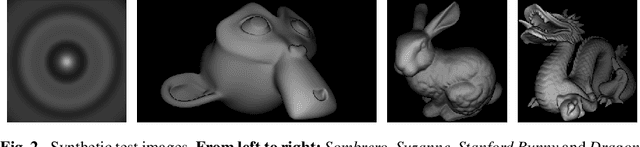
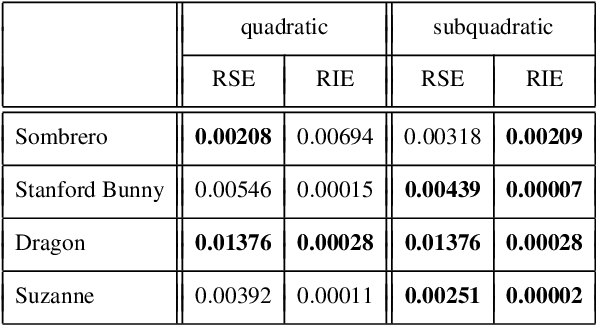
Most of today's state-of-the-art methods for perspective shape from shading are modelled in terms of partial differential equations (PDEs) of Hamilton-Jacobi type. To improve the robustness of such methods w.r.t. noise and missing data, first approaches have recently been proposed that seek to embed the underlying PDE into a variational framework with data and smoothness term. So far, however, such methods either make use of a radial depth parametrisation that makes the regularisation hard to interpret from a geometrical viewpoint or they consider indirect smoothness terms that require additional consistency constraints to provide valid solutions. Moreover the minimisation of such frameworks is an intricate task, since the underlying energy is typically non-convex. In our paper we address all three of the aforementioned issues. First, we propose a novel variational model that operates directly on the Cartesian depth. In this context, we also point out a common mistake in the derivation of the surface normal. Moreover, we employ a direct second-order regulariser with edge-preservation property. This direct regulariser yields by construction valid solutions without requiring additional consistency constraints. Finally, we also propose a novel coarse-to-fine minimisation framework based on an alternating explicit scheme. This framework allows us to avoid local minima during the minimisation and thus to improve the accuracy of the reconstruction. Experiments show the good quality of our model as well as the usefulness of the proposed numerical scheme.