 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained HDR Image Quality Assessment From Noticeably Distorted to Very High Fidelity
Jun 14, 2025



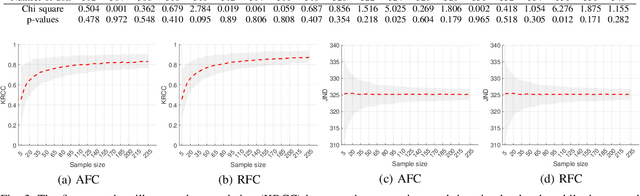
High dynamic range (HDR) and wide color gamut (WCG) technologies significantly improve color reproduction compared to standard dynamic range (SDR) and standard color gamuts, resulting in more accurate, richer, and more immersive images. However, HDR increases data demands, posing challenges for bandwidth efficiency and compression techniques. Advances in compression and display technologies require more precise image quality assessment, particularly in the high-fidelity range where perceptual differences are subtle. To address this gap, we introduce AIC-HDR2025, the first such HDR dataset, comprising 100 test images generated from five HDR sources, each compressed using four codecs at five compression levels. It covers the high-fidelity range, from visible distortions to compression levels below the visually lossless threshold. A subjective study was conducted using the JPEG AIC-3 test methodology, combining plain and boosted triplet comparisons. In total, 34,560 ratings were collected from 151 participants across four fully controlled labs. The results confirm that AIC-3 enables precise HDR quality estimation, with 95\% confidence intervals averaging a width of 0.27 at 1 JND. In addition, several recently proposed objective metrics were evaluated based on their correlation with subjective ratings. The dataset is publicly available.
Subjective Visual Quality Assessment for High-Fidelity Learning-Based Image Compression
Apr 10, 2025Learning-based image compression methods have recently emerged as promising alternatives to traditional codecs, offering improved rate-distortion performance and perceptual quality. JPEG AI represents the latest standardized framework in this domain, leveraging deep neural networks for high-fidelity image reconstruction. In this study, we present a comprehensive subjective visual quality assessment of JPEG AI-compressed images using the JPEG AIC-3 methodology, which quantifies perceptual differences in terms of Just Noticeable Difference (JND) units. We generated a dataset of 50 compressed images with fine-grained distortion levels from five diverse sources. A large-scale crowdsourced experiment collected 96,200 triplet responses from 459 participants. We reconstructed JND-based quality scales using a unified model based on boosted and plain triplet comparisons. Additionally, we evaluated the alignment of multiple objective image quality metrics with human perception in the high-fidelity range. The CVVDP metric achieved the overall highest performance; however, most metrics including CVVDP were overly optimistic in predicting the quality of JPEG AI-compressed images. These findings emphasize the necessity for rigorous subjective evaluations in the development and benchmarking of modern image codecs, particularly in the high-fidelity range. Another technical contribution is the introduction of the well-known Meng-Rosenthal-Rubin statistical test to the field of Quality of Experience research. This test can reliably assess the significance of difference in performance of quality metrics in terms of correlation between metrics and ground truth. The complete dataset, including all subjective scores, is publicly available at https://github.com/jpeg-aic/dataset-JPEG-AI-SDR25.
Image Intrinsic Scale Assessment: Bridging the Gap Between Quality and Resolution
Feb 10, 2025



Image Quality Assessment (IQA) measures and predicts perceived image quality by human observers. Although recent studies have highlighted the critical influence that variations in the scale of an image have on its perceived quality, this relationship has not been systematically quantified. To bridge this gap, we introduce the Image Intrinsic Scale (IIS), defined as the largest scale where an image exhibits its highest perceived quality. We also present the Image Intrinsic Scale Assessment (IISA) task, which involves subjectively measuring and predicting the IIS based on human judgments. We develop a subjective annotation methodology and create the IISA-DB dataset, comprising 785 image-IIS pairs annotated by experts in a rigorously controlled crowdsourcing study. Furthermore, we propose WIISA (Weak-labeling for Image Intrinsic Scale Assessment), a strategy that leverages how the IIS of an image varies with downscaling to generate weak labels. Experiments show that applying WIISA during the training of several IQA methods adapted for IISA consistently improves the performance compared to using only ground-truth labels. We will release the code, dataset, and pre-trained models upon acceptance.
Fine-grained subjective visual quality assessment for high-fidelity compressed images
Oct 12, 2024Advances in image compression, storage, and display technologies have made high-quality images and videos widely accessible. At this level of quality, distinguishing between compressed and original content becomes difficult, highlighting the need for assessment methodologies that are sensitive to even the smallest visual quality differences. Conventional subjective visual quality assessments often use absolute category rating scales, ranging from ``excellent'' to ``bad''. While suitable for evaluating more pronounced distortions, these scales are inadequate for detecting subtle visual differences. The JPEG standardization project AIC is currently developing a subjective image quality assessment methodology for high-fidelity images. This paper presents the proposed assessment methods, a dataset of high-quality compressed images, and their corresponding crowdsourced visual quality ratings. It also outlines a data analysis approach that reconstructs quality scale values in just noticeable difference (JND) units. The assessment method uses boosting techniques on visual stimuli to help observers detect compression artifacts more clearly. This is followed by a rescaling process that adjusts the boosted quality values back to the original perceptual scale. This reconstruction yields a fine-grained, high-precision quality scale in JND units, providing more informative results for practical applications. The dataset and code to reproduce the results will be available at https://github.com/jpeg-aic/dataset-BTC-PTC-24.
Maximum entropy and quantized metric models for absolute category ratings
Oct 01, 2024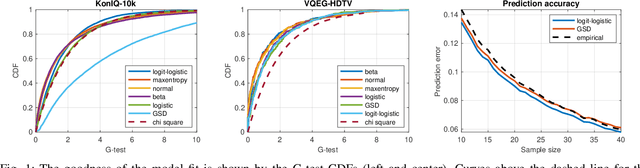
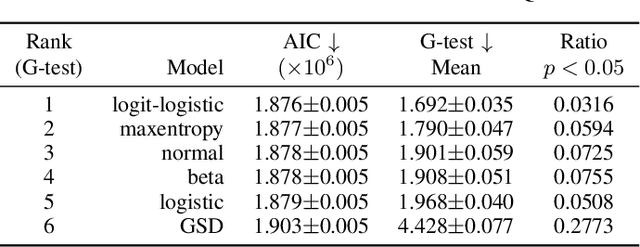
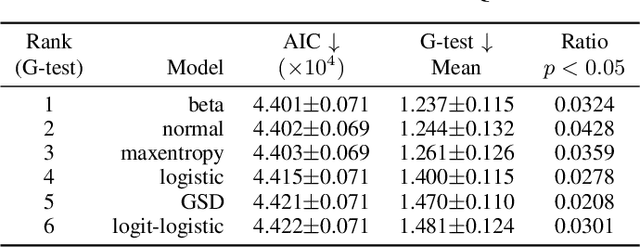
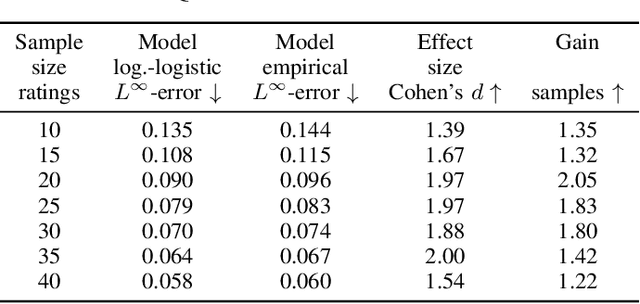
The datasets of most image quality assessment studies contain ratings on a categorical scale with five levels, from bad (1) to excellent (5). For each stimulus, the number of ratings from 1 to 5 is summarized and given in the form of the mean opinion score. In this study, we investigate families of multinomial probability distributions parameterized by mean and variance that are used to fit the empirical rating distributions. To this end, we consider quantized metric models based on continuous distributions that model perceived stimulus quality on a latent scale. The probabilities for the rating categories are determined by quantizing the corresponding random variables using threshold values. Furthermore, we introduce a novel discrete maximum entropy distribution for a given mean and variance. We compare the performance of these models and the state of the art given by the generalized score distribution for two large data sets, KonIQ-10k and VQEG HDTV. Given an input distribution of ratings, our fitted two-parameter models predict unseen ratings better than the empirical distribution. In contrast to empirical ACR distributions and their discrete models, our continuous models can provide fine-grained estimates of quantiles of quality of experience that are relevant to service providers to satisfy a target fraction of the user population.
Localization of Just Noticeable Difference for Image Compression
Jun 13, 2023



The just noticeable difference (JND) is the minimal difference between stimuli that can be detected by a person. The picture-wise just noticeable difference (PJND) for a given reference image and a compression algorithm represents the minimal level of compression that causes noticeable differences in the reconstruction. These differences can only be observed in some specific regions within the image, dubbed as JND-critical regions. Identifying these regions can improve the development of image compression algorithms. Due to the fact that visual perception varies among individuals, determining the PJND values and JND-critical regions for a target population of consumers requires subjective assessment experiments involving a sufficiently large number of observers. In this paper, we propose a novel framework for conducting such experiments using crowdsourcing. By applying this framework, we created a novel PJND dataset, KonJND++, consisting of 300 source images, compressed versions thereof under JPEG or BPG compression, and an average of 43 ratings of PJND and 129 self-reported locations of JND-critical regions for each source image. Our experiments demonstrate the effectiveness and reliability of our proposed framework, which is easy to be adapted for collecting a large-scale dataset. The source code and dataset are available at https://github.com/angchen-dev/LocJND.
Relaxed forced choice improves performance of visual quality assessment methods
Apr 29, 2023


In image quality assessment, a collective visual quality score for an image or video is obtained from the individual ratings of many subjects. One commonly used format for these experiments is the two-alternative forced choice method. Two stimuli with the same content but differing visual quality are presented sequentially or side-by-side. Subjects are asked to select the one of better quality, and when uncertain, they are required to guess. The relaxed alternative forced choice format aims to reduce the cognitive load and the noise in the responses due to the guessing by providing a third response option, namely, ``not sure''. This work presents a large and comprehensive crowdsourcing experiment to compare these two response formats: the one with the ``not sure'' option and the one without it. To provide unambiguous ground truth for quality evaluation, subjects were shown pairs of images with differing numbers of dots and asked each time to choose the one with more dots. Our crowdsourcing study involved 254 participants and was conducted using a within-subject design. Each participant was asked to respond to 40 pair comparisons with and without the ``not sure'' response option and completed a questionnaire to evaluate their cognitive load for each testing condition. The experimental results show that the inclusion of the ``not sure'' response option in the forced choice method reduced mental load and led to models with better data fit and correspondence to ground truth. We also tested for the equivalence of the models and found that they were different. The dataset is available at http://database.mmsp-kn.de/cogvqa-database.html.
KonX: Cross-Resolution Image Quality Assessment
Dec 12, 2022Scale-invariance is an open problem in many computer vision subfields. For example, object labels should remain constant across scales, yet model predictions diverge in many cases. This problem gets harder for tasks where the ground-truth labels change with the presentation scale. In image quality assessment (IQA), downsampling attenuates impairments, e.g., blurs or compression artifacts, which can positively affect the impression evoked in subjective studies. To accurately predict perceptual image quality, cross-resolution IQA methods must therefore account for resolution-dependent errors induced by model inadequacies as well as for the perceptual label shifts in the ground truth. We present the first study of its kind that disentangles and examines the two issues separately via KonX, a novel, carefully crafted cross-resolution IQA database. This paper contributes the following: 1. Through KonX, we provide empirical evidence of label shifts caused by changes in the presentation resolution. 2. We show that objective IQA methods have a scale bias, which reduces their predictive performance. 3. We propose a multi-scale and multi-column DNN architecture that improves performance over previous state-of-the-art IQA models for this task, including recent transformers. We thus both raise and address a novel research problem in image quality assessment.
Going the Extra Mile in Face Image Quality Assessment: A Novel Database and Model
Jul 11, 2022
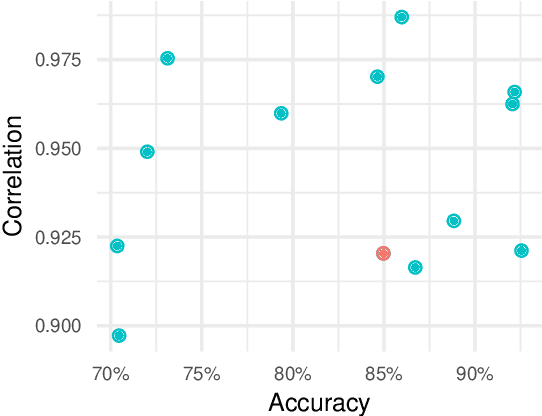

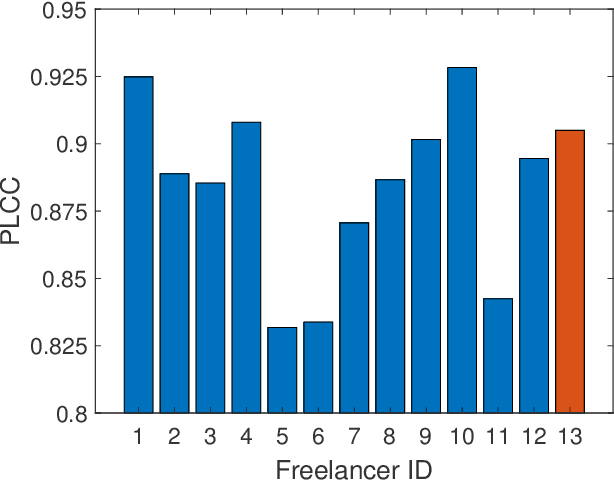
Computer vision models for image quality assessment (IQA) predict the subjective effect of generic image degradation, such as artefacts, blurs, bad exposure, or colors. The scarcity of face images in existing IQA datasets (below 10\%) is limiting the precision of IQA required for accurately filtering low-quality face images or guiding CV models for face image processing, such as super-resolution, image enhancement, and generation. In this paper, we first introduce the largest annotated IQA database to date that contains 20,000 human faces (an order of magnitude larger than all existing rated datasets of faces), of diverse individuals, in highly varied circumstances, quality levels, and distortion types. Based on the database, we further propose a novel deep learning model, which re-purposes generative prior features for predicting subjective face quality. By exploiting rich statistics encoded in well-trained generative models, we obtain generative prior information of the images and serve them as latent references to facilitate the blind IQA task. Experimental results demonstrate the superior prediction accuracy of the proposed model on the face IQA task.
TranSalNet: Visual saliency prediction using transformers
Oct 07, 2021



Convolutional neural networks (CNNs) have significantly advanced computational modeling for saliency prediction. However, the inherent inductive biases of convolutional architectures cause insufficient long-range contextual encoding capacity, which potentially makes a saliency model less humanlike. Transformers have shown great potential in encoding long-range information by leveraging the self-attention mechanism. In this paper, we propose a novel saliency model integrating transformer components to CNNs to capture the long-range contextual information. Experimental results show that the new components make improvements, and the proposed model achieves promising results in predicting saliency.