 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained HDR Image Quality Assessment From Noticeably Distorted to Very High Fidelity
Jun 14, 2025



High dynamic range (HDR) and wide color gamut (WCG) technologies significantly improve color reproduction compared to standard dynamic range (SDR) and standard color gamuts, resulting in more accurate, richer, and more immersive images. However, HDR increases data demands, posing challenges for bandwidth efficiency and compression techniques. Advances in compression and display technologies require more precise image quality assessment, particularly in the high-fidelity range where perceptual differences are subtle. To address this gap, we introduce AIC-HDR2025, the first such HDR dataset, comprising 100 test images generated from five HDR sources, each compressed using four codecs at five compression levels. It covers the high-fidelity range, from visible distortions to compression levels below the visually lossless threshold. A subjective study was conducted using the JPEG AIC-3 test methodology, combining plain and boosted triplet comparisons. In total, 34,560 ratings were collected from 151 participants across four fully controlled labs. The results confirm that AIC-3 enables precise HDR quality estimation, with 95\% confidence intervals averaging a width of 0.27 at 1 JND. In addition, several recently proposed objective metrics were evaluated based on their correlation with subjective ratings. The dataset is publicly available.
LoC-LIC: Low Complexity Learned Image Coding Using Hierarchical Feature Transforms
Apr 30, 2025Current learned image compression models typically exhibit high complexity, which demands significant computational resources. To overcome these challenges, we propose an innovative approach that employs hierarchical feature extraction transforms to significantly reduce complexity while preserving bit rate reduction efficiency. Our novel architecture achieves this by using fewer channels for high spatial resolution inputs/feature maps. On the other hand, feature maps with a large number of channels have reduced spatial dimensions, thereby cutting down on computational load without sacrificing performance. This strategy effectively reduces the forward pass complexity from \(1256 \, \text{kMAC/Pixel}\) to just \(270 \, \text{kMAC/Pixel}\). As a result, the reduced complexity model can open the way for learned image compression models to operate efficiently across various devices and pave the way for the development of new architectures in image compression technology.
Compact Latent Representation for Image Compression (CLRIC)
Feb 20, 2025Current image compression models often require separate models for each quality level, making them resource-intensive in terms of both training and storage. To address these limitations, we propose an innovative approach that utilizes latent variables from pre-existing trained models (such as the Stable Diffusion Variational Autoencoder) for perceptual image compression. Our method eliminates the need for distinct models dedicated to different quality levels. We employ overfitted learnable functions to compress the latent representation from the target model at any desired quality level. These overfitted functions operate in the latent space, ensuring low computational complexity, around $25.5$ MAC/pixel for a forward pass on images with dimensions $(1363 \times 2048)$ pixels. This approach efficiently utilizes resources during both training and decoding. Our method achieves comparable perceptual quality to state-of-the-art learned image compression models while being both model-agnostic and resolution-agnostic. This opens up new possibilities for the development of innovative image compression methods.
A Study on the Effect of Color Spaces in Learned Image Compression
Jun 19, 2024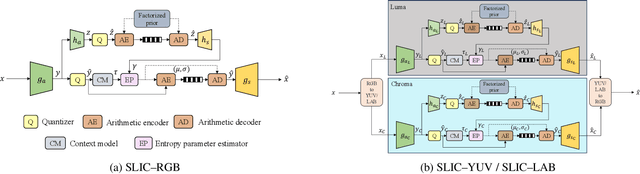
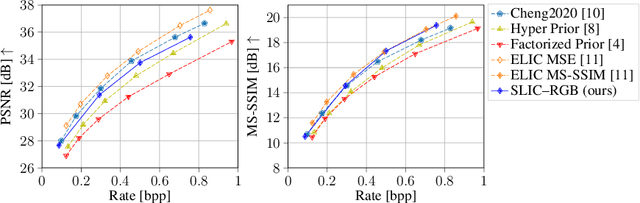
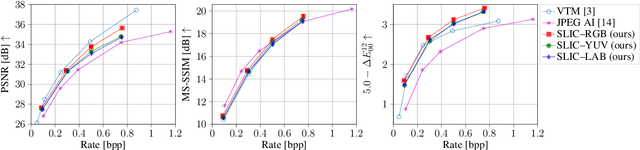
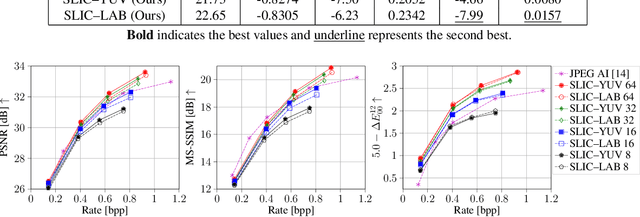
In this work, we present a comparison between color spaces namely YUV, LAB, RGB and their effect on learned image compression. For this we use the structure and color based learned image codec (SLIC) from our prior work, which consists of two branches - one for the luminance component (Y or L) and another for chrominance components (UV or AB). However, for the RGB variant we input all 3 channels in a single branch, similar to most learned image codecs operating in RGB. The models are trained for multiple bitrate configurations in each color space. We report the findings from our experiments by evaluating them on various datasets and compare the results to state-of-the-art image codecs. The YUV model performs better than the LAB variant in terms of MS-SSIM with a Bj{\o}ntegaard delta bitrate (BD-BR) gain of 7.5\% using VTM intra-coding mode as the baseline. Whereas the LAB variant has a better performance than YUV model in terms of CIEDE2000 having a BD-BR gain of 8\%. Overall, the RGB variant of SLIC achieves the best performance with a BD-BR gain of 13.14\% in terms of MS-SSIM and a gain of 17.96\% in CIEDE2000 at the cost of a higher model complexity.
SLIC: A Learned Image Codec Using Structure and Color
Jan 30, 2024



We propose the structure and color based learned image codec (SLIC) in which the task of compression is split into that of luminance and chrominance. The deep learning model is built with a novel multi-scale architecture for Y and UV channels in the encoder, where the features from various stages are combined to obtain the latent representation. An autoregressive context model is employed for backward adaptation and a hyperprior block for forward adaptation. Various experiments are carried out to study and analyze the performance of the proposed model, and to compare it with other image codecs. We also illustrate the advantages of our method through the visualization of channel impulse responses, latent channels and various ablation studies. The model achieves Bj{\o}ntegaard delta bitrate gains of 7.5% and 4.66% in terms of MS-SSIM and CIEDE2000 metrics with respect to other state-of-the-art reference codecs.
Color Learning for Image Compression
Jun 30, 2023



Deep learning based image compression has gained a lot of momentum in recent times. To enable a method that is suitable for image compression and subsequently extended to video compression, we propose a novel deep learning model architecture, where the task of image compression is divided into two sub-tasks, learning structural information from luminance channel and color from chrominance channels. The model has two separate branches to process the luminance and chrominance components. The color difference metric CIEDE2000 is employed in the loss function to optimize the model for color fidelity. We demonstrate the benefits of our approach and compare the performance to other codecs. Additionally, the visualization and analysis of latent channel impulse response is performed.
Temporal Scalability of Dynamic Volume Data Using Mesh Compensated Wavelet Lifting
Mar 01, 2023



Due to their high resolution, dynamic medical 2D+t and 3D+t volumes from computed tomography (CT) and magnetic resonance tomography (MR) reach a size which makes them very unhandy for teleradiologic applications. A lossless scalable representation offers the advantage of a down-scaled version which can be used for orientation or previewing, while the remaining information for reconstructing the full resolution is transmitted on demand. The wavelet transform offers the desired scalability. A very high quality of the lowpass sub-band is crucial in order to use it as a down-scaled representation. We propose an approach based on compensated wavelet lifting for obtaining a scalable representation of dynamic CT and MR volumes with very high quality. The mesh compensation is feasible to model the displacement in dynamic volumes which is mainly given by expansion and contraction of tissue over time. To achieve this, we propose an optimized estimation of the mesh compensation parameters to optimally fit for dynamic volumes. Within the lifting structure, the inversion of the motion compensation is crucial in the update step. We propose to take this inversion directly into account during the estimation step and can improve the quality of the lowpass sub-band by 0.63 and 0.43 dB on average for our tested dynamic CT and MR volumes at the cost of an increase of the rate by 2.4% and 1.2% on average.
Analysis of mesh-based motion compensation in wavelet lifting of dynamical 3-D+t CT data
Feb 03, 2023Factorized in the lifting structure, the wavelet transform can easily be extended by arbitrary compensation methods. Thereby, the transform can be adapted to displacements in the signal without losing the ability of perfect reconstruction. This leads to an improvement of scalability. In temporal direction of dynamic medical 3-D+t volumes from Computed Tomography, displacement is mainly given by expansion and compression of tissue. We show that these smooth movements can be well compensated with a mesh-based method. We compare the properties of triangle and quadrilateral meshes. We also show that with a mesh-based compensation approach coding results are comparable to the common slice wise coding with JPEG 2000 while a scalable representation in temporal direction can be achieved.
Centroid adapted frequency selective extrapolation for reconstruction of lost image areas
Jan 12, 2023Lost image areas with different size and arbitrary shape can occur in many scenarios such as error-prone communication, depth-based image rendering or motion compensated wavelet lifting. The goal of image reconstruction is to restore these lost image areas as close to the original as possible. Frequency selective extrapolation is a block-based method for efficiently reconstructing lost areas in images. So far, the actual shape of the lost area is not considered directly. We propose a centroid adaption to enhance the existing frequency selective extrapolation algorithm that takes the shape of lost areas into account. To enlarge the test set for evaluation we further propose a method to generate arbitrarily shaped lost areas. On our large test set, we obtain an average reconstruction gain of 1.29 dB.
Efficient lossless coding of highpass bands from block-based motion compensated wavelet lifting using JPEG 2000
Jan 11, 2023Lossless image coding is a crucial task especially in the medical area, e.g., for volumes from Computed Tomography or Magnetic Resonance Tomography. Besides lossless coding, compensated wavelet lifting offers a scalable representation of such huge volumes. While compensation methods increase the details in the lowpass band, they also vary the characteristics of the wavelet coefficients, so an adaption of the coefficient coder should be considered. We propose a simple invertible extension for JPEG 2000 that can reduce the filesize for lossless coding of the highpass band by 0.8% on average with peak rate saving of 1.1%.