 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained HDR Image Quality Assessment From Noticeably Distorted to Very High Fidelity
Jun 14, 2025



High dynamic range (HDR) and wide color gamut (WCG) technologies significantly improve color reproduction compared to standard dynamic range (SDR) and standard color gamuts, resulting in more accurate, richer, and more immersive images. However, HDR increases data demands, posing challenges for bandwidth efficiency and compression techniques. Advances in compression and display technologies require more precise image quality assessment, particularly in the high-fidelity range where perceptual differences are subtle. To address this gap, we introduce AIC-HDR2025, the first such HDR dataset, comprising 100 test images generated from five HDR sources, each compressed using four codecs at five compression levels. It covers the high-fidelity range, from visible distortions to compression levels below the visually lossless threshold. A subjective study was conducted using the JPEG AIC-3 test methodology, combining plain and boosted triplet comparisons. In total, 34,560 ratings were collected from 151 participants across four fully controlled labs. The results confirm that AIC-3 enables precise HDR quality estimation, with 95\% confidence intervals averaging a width of 0.27 at 1 JND. In addition, several recently proposed objective metrics were evaluated based on their correlation with subjective ratings. The dataset is publicly available.
Adapting Learned Image Codecs to Screen Content via Adjustable Transformations
Feb 27, 2024



As learned image codecs (LICs) become more prevalent, their low coding efficiency for out-of-distribution data becomes a bottleneck for some applications. To improve the performance of LICs for screen content (SC) images without breaking backwards compatibility, we propose to introduce parameterized and invertible linear transformations into the coding pipeline without changing the underlying baseline codec's operation flow. We design two neural networks to act as prefilters and postfilters in our setup to increase the coding efficiency and help with the recovery from coding artifacts. Our end-to-end trained solution achieves up to 10% bitrate savings on SC compression compared to the baseline LICs while introducing only 1% extra parameters.
Efficient Contextformer: Spatio-Channel Window Attention for Fast Context Modeling in Learned Image Compression
Jun 25, 2023


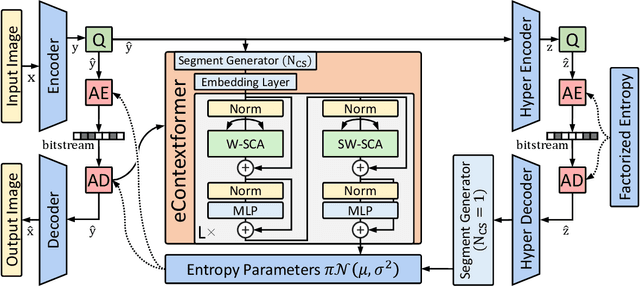
In this work, we introduce Efficient Contextformer (eContextformer) for context modeling in lossy learned image compression, which is built upon our previous work, Contextformer. The eContextformer combines the recent advancements in efficient transformers and fast context models with the spatio-channel attention mechanism. The proposed model enables content-adaptive exploitation of the spatial and channel-wise latent dependencies for a high performance and efficient entropy modeling. By incorporating several innovations, the eContextformer features improved decoding speed, model complexity and rate-distortion performance over previous work. For instance, compared to Contextformer, the eContextformer requires 145x less model complexity, 210x less decoding speed and achieves higher average bit savings on the Kodak, CLIC2020 and Tecnick datasets. Compared to the standard Versatile Video Coding (VVC) Test Model (VTM) 16.2, the proposed model provides up to 17.1% bitrate savings and surpasses various learning-based models.