 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of Variable Rate Coding in JPEG AI
Mar 20, 2025Empirical evidence has demonstrated that learning-based image compression can outperform classical compression frameworks. This has led to the ongoing standardization of learned-based image codecs, namely Joint Photographic Experts Group (JPEG) AI. The objective of JPEG AI is to enhance compression efficiency and provide a software and hardwarefriendly solution. Based on our research, JPEG AI represents the first standardization that can facilitate the implementation of a learned image codec on a mobile device. This article presents an overview of the variable rate coding functionality in JPEG AI, which includes three variable rate adaptations: a threedimensional quality map, a fast bit rate matching algorithm, and a training strategy. The variable rate adaptations offer a continuous rate function up to 2.0 bpp, exhibiting a high level of performance, a flexible bit allocation between different color components, and a region of interest function for the specified use case. The evaluation of performance encompasses both objective and subjective results. With regard to the objective bit rate matching, the main profile with low complexity yielded a 13.1% BD-rate gain over VVC intra, while the high profile with high complexity achieved a 19.2% BD-rate gain over VVC intra. The BD-rate result is calculated as the mean of the seven perceptual metrics defined in the JPEG AI common test conditions. With respect to subjective results, the example of improving the quality of the region of interest is illustrated.
Bit Rate Matching Algorithm Optimization in JPEG-AI Verification Model
Feb 27, 2024The research on neural network (NN) based image compression has shown superior performance compared to classical compression frameworks. Unlike the hand-engineered transforms in the classical frameworks, NN-based models learn the non-linear transforms providing more compact bit representations, and achieve faster coding speed on parallel devices over their classical counterparts. Those properties evoked the attention of both scientific and industrial communities, resulting in the standardization activity JPEG-AI. The verification model for the standardization process of JPEG-AI is already in development and has surpassed the advanced VVC intra codec. To generate reconstructed images with the desired bits per pixel and assess the BD-rate performance of both the JPEG-AI verification model and VVC intra, bit rate matching is employed. However, the current state of the JPEG-AI verification model experiences significant slowdowns during bit rate matching, resulting in suboptimal performance due to an unsuitable model. The proposed methodology offers a gradual algorithmic optimization for matching bit rates, resulting in a fourfold acceleration and over 1% improvement in BD-rate at the base operation point. At the high operation point, the acceleration increases up to sixfold.
Adapting Learned Image Codecs to Screen Content via Adjustable Transformations
Feb 27, 2024



As learned image codecs (LICs) become more prevalent, their low coding efficiency for out-of-distribution data becomes a bottleneck for some applications. To improve the performance of LICs for screen content (SC) images without breaking backwards compatibility, we propose to introduce parameterized and invertible linear transformations into the coding pipeline without changing the underlying baseline codec's operation flow. We design two neural networks to act as prefilters and postfilters in our setup to increase the coding efficiency and help with the recovery from coding artifacts. Our end-to-end trained solution achieves up to 10% bitrate savings on SC compression compared to the baseline LICs while introducing only 1% extra parameters.
Bit Distribution Study and Implementation of Spatial Quality Map in the JPEG-AI Standardization
Feb 27, 2024Currently, there is a high demand for neural network-based image compression codecs. These codecs employ non-linear transforms to create compact bit representations and facilitate faster coding speeds on devices compared to the hand-crafted transforms used in classical frameworks. The scientific and industrial communities are highly interested in these properties, leading to the standardization effort of JPEG-AI. The JPEG-AI verification model has been released and is currently under development for standardization. Utilizing neural networks, it can outperform the classic codec VVC intra by over 10% BD-rate operating at base operation point. Researchers attribute this success to the flexible bit distribution in the spatial domain, in contrast to VVC intra's anchor that is generated with a constant quality point. However, our study reveals that VVC intra displays a more adaptable bit distribution structure through the implementation of various block sizes. As a result of our observations, we have proposed a spatial bit allocation method to optimize the JPEG-AI verification model's bit distribution and enhance the visual quality. Furthermore, by applying the VVC bit distribution strategy, the objective performance of JPEG-AI verification mode can be further improved, resulting in a maximum gain of 0.45 dB in PSNR-Y.
Quantized Decoder in Learned Image Compression for Deterministic Reconstruction
Dec 18, 2023



Learned image compression has a problem of non-bit-exact reconstruction due to different calculations of floating point arithmetic on different devices. This paper shows a method to achieve a deterministic reconstructed image by quantizing only the decoder of the learned image compression model. From the implementation perspective of an image codec, it is beneficial to have the results reproducible when decoded on different devices. In this paper, we study quantization of weights and activations without overflow of accumulator in all decoder subnetworks. We show that the results are bit-exact at the output, and the resulting BD-rate loss of quantization of decoder is 0.5 % in the case of 16-bit weights and 16-bit activations, and 7.9 % in the case of 8-bit weights and 16-bit activations.
Efficient Contextformer: Spatio-Channel Window Attention for Fast Context Modeling in Learned Image Compression
Jun 25, 2023In this work, we introduce Efficient Contextformer (eContextformer) for context modeling in lossy learned image compression, which is built upon our previous work, Contextformer. The eContextformer combines the recent advancements in efficient transformers and fast context models with the spatio-channel attention mechanism. The proposed model enables content-adaptive exploitation of the spatial and channel-wise latent dependencies for a high performance and efficient entropy modeling. By incorporating several innovations, the eContextformer features improved decoding speed, model complexity and rate-distortion performance over previous work. For instance, compared to Contextformer, the eContextformer requires 145x less model complexity, 210x less decoding speed and achieves higher average bit savings on the Kodak, CLIC2020 and Tecnick datasets. Compared to the standard Versatile Video Coding (VVC) Test Model (VTM) 16.2, the proposed model provides up to 17.1% bitrate savings and surpasses various learning-based models.
Learning-Based Conditional Image Coder Using Color Separation
Dec 12, 2022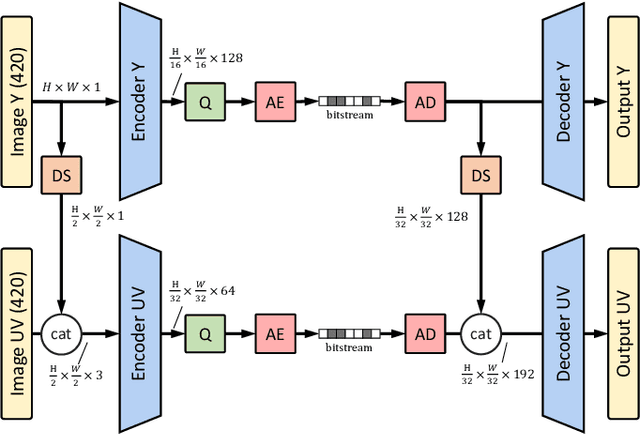

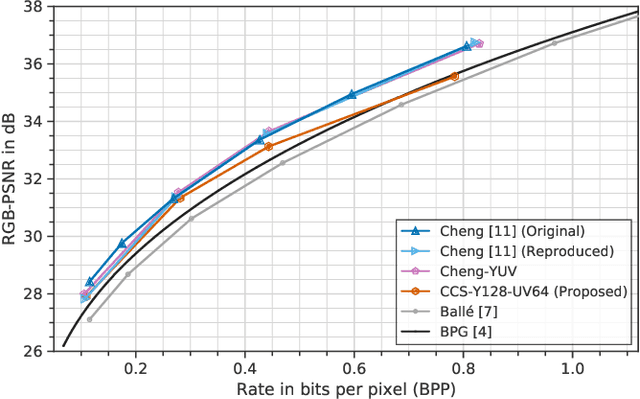

Recently, image compression codecs based on Neural Networks(NN) outperformed the state-of-art classic ones such as BPG, an image format based on HEVC intra. However, the typical NN codec has high complexity, and it has limited options for parallel data processing. In this work, we propose a conditional separation principle that aims to improve parallelization and lower the computational requirements of an NN codec. We present a Conditional Color Separation (CCS) codec which follows this principle. The color components of an image are split into primary and non-primary ones. The processing of each component is done separately, by jointly trained networks. Our approach allows parallel processing of each component, flexibility to select different channel numbers, and an overall complexity reduction. The CCS codec uses over 40% less memory, has 2x faster encoding and 22% faster decoding speed, with only 4% BD-rate loss in RGB PSNR compared to our baseline model over BPG.
Device Interoperability for Learned Image Compression with Weights and Activations Quantization
Dec 02, 2022



Learning-based image compression has improved to a level where it can outperform traditional image codecs such as HEVC and VVC in terms of coding performance. In addition to good compression performance, device interoperability is essential for a compression codec to be deployed, i.e., encoding and decoding on different CPUs or GPUs should be error-free and with negligible performance reduction. In this paper, we present a method to solve the device interoperability problem of a state-of-the-art image compression network. We implement quantization to entropy networks which output entropy parameters. We suggest a simple method which can ensure cross-platform encoding and decoding, and can be implemented quickly with minor performance deviation, of 0.3% BD-rate, from floating point model results.