 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-Aliasing Snapshot HDR Imaging Using Non-Regular Sensing
Mar 05, 2026Snapshot HDR imaging is essential to capture the full dynamic range of a scene in a single exposure, making it essential for video and dynamic environments where motion prevents the use of multi-exposure techniques or complex hardware set-ups. This work presents a snapshot HDR imaging sensor that is based on spatially varying apertures, implemented by combining two differently sized prototype pixels. The different light integration areas physically extend the dynamic range towards the lower end, compared to a standard high resolution sensor. A non-regular pixel arrangement is suggested, to mitigate aliasing and overcome a loss in spatial resolution that is associated with increased light integration area of the larger prototype pixel. Subsequent reconstruction in the Fourier domain, where natural images can be sparsely represented allows to recover the image with high detail. The image acquisition approach with the proposed non-regular HDR sensor is simulated and analysed with special emphasis on the spatial resolution. The results suggest the snapshot HDR sensor layout to be an effective way to acquire images with high dynamic range and free from aliasing artefacts.
Towards Object Segmentation Mask Selection Using Specular Reflections
Feb 25, 2026Specular reflections pose a significant challenge for object segmentation, as their sharp intensity transitions often mislead both conventional algorithms and deep learning based methods. However, as the specular reflection must lie on the surface of the object, this fact can be exploited to improve the segmentation masks. By identifying the largest region containing the reflection as the object, we derive a more accurate object mask without requiring specialized training data or model adaption. We evaluate our method on both synthetic and real world images and compare it against established and state-of-the-art techniques including Otsu thresholding, YOLO, and SAM2. Compared to the best performing baseline SAM2, our approach achieves up to 26.7% improvement in IoU, 22.3% in DSC, and 9.7% in pixel accuracy. Qualitative evaluations on real world images further confirm the robustness and generalizability of the proposed approach.
LRC-DHVC: Towards Local Rate Control in Neural Video Compression
Jan 20, 2026Local rate control is a key enabler to generalize image and video compression for dedicated challenges, such as video coding for machines. While traditional hybrid video coding can easily adapt the local rate-distortion trade-off by changing the local quantization parameter, no such approach is currently available for learning-based video compression. In this paper, we propose LRC-DHVC, a hierarchical video compression network, which allows continuous local rate control on a pixel level to vary the spatial quality distribution within individual video frames. This is achieved by concatenating a quality map to the input frame and applying a weighted MSE loss which matches the pixelwise trade-off factors in the quality map. During training, the model sees a variety of quality maps due to a constrained-random generation. Our model is the first neural video compression network, which can continuously and spatially adapt to varying quality constraints. Due to the wide quality and bit rate range, a single set of network parameters is sufficient. Compared to single rate point networks, which scale linearly with the number of rate points, the memory requirements for our network parameters remain constant. The code and model are available at link-updated-upon-acceptance.
Visual Autoregressive Modelling for Monocular Depth Estimation
Dec 27, 2025We propose a monocular depth estimation method based on visual autoregressive (VAR) priors, offering an alternative to diffusion-based approaches. Our method adapts a large-scale text-to-image VAR model and introduces a scale-wise conditional upsampling mechanism with classifier-free guidance. Our approach performs inference in ten fixed autoregressive stages, requiring only 74K synthetic samples for fine-tuning, and achieves competitive results. We report state-of-the-art performance in indoor benchmarks under constrained training conditions, and strong performance when applied to outdoor datasets. This work establishes autoregressive priors as a complementary family of geometry-aware generative models for depth estimation, highlighting advantages in data scalability, and adaptability to 3D vision tasks. Code available at "https://github.com/AmirMaEl/VAR-Depth".
TreeNet: A Light Weight Model for Low Bitrate Image Compression
Dec 18, 2025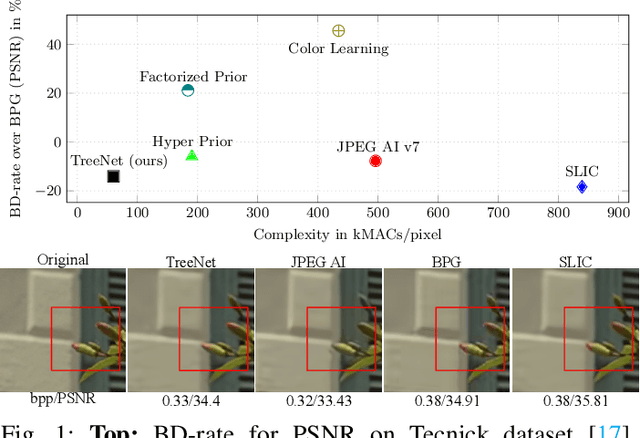
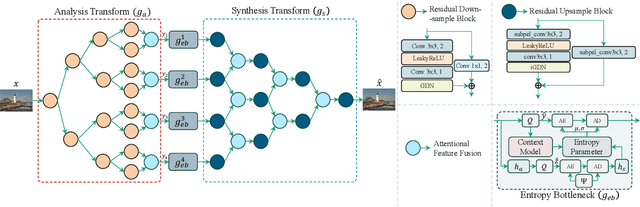
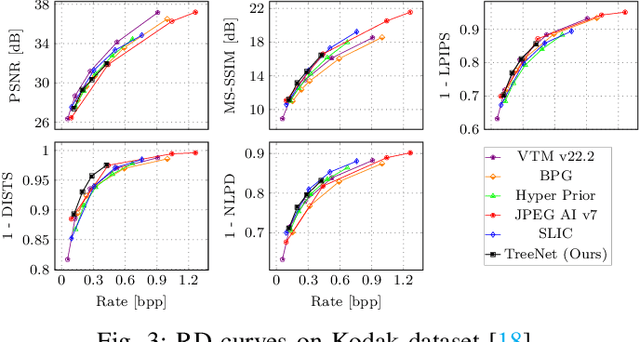
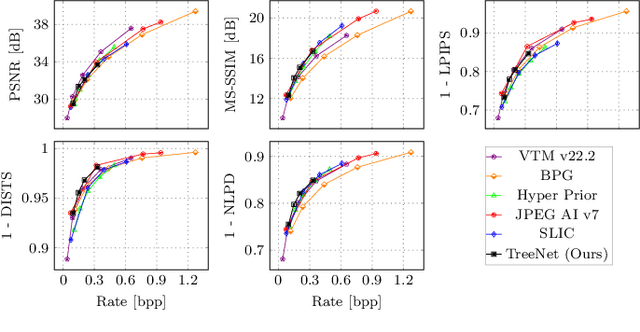
Reducing computational complexity remains a critical challenge for the widespread adoption of learning-based image compression techniques. In this work, we propose TreeNet, a novel low-complexity image compression model that leverages a binary tree-structured encoder-decoder architecture to achieve efficient representation and reconstruction. We employ attentional feature fusion mechanism to effectively integrate features from multiple branches. We evaluate TreeNet on three widely used benchmark datasets and compare its performance against competing methods including JPEG AI, a recent standard in learning-based image compression. At low bitrates, TreeNet achieves an average improvement of 4.83% in BD-rate over JPEG AI, while reducing model complexity by 87.82%. Furthermore, we conduct extensive ablation studies to investigate the influence of various latent representations within TreeNet, offering deeper insights into the factors contributing to reconstruction.
Domain Adaptation for Camera-Specific Image Characteristics using Shallow Discriminators
Nov 13, 2025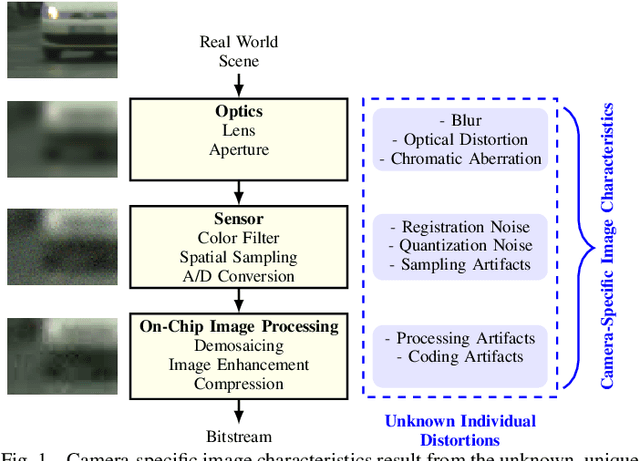
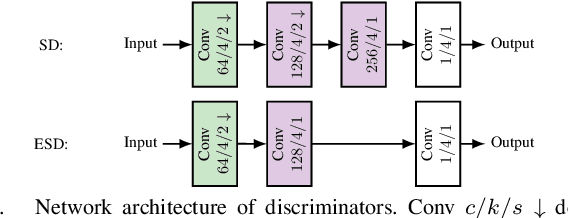
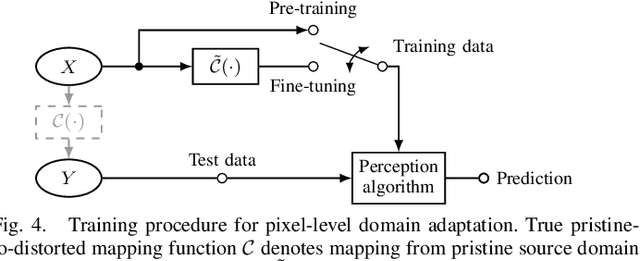
Each image acquisition setup leads to its own camera-specific image characteristics degrading the image quality. In learning-based perception algorithms, characteristics occurring during the application phase, but absent in the training data, lead to a domain gap impeding the performance. Previously, pixel-level domain adaptation through unpaired learning of the pristine-to-distorted mapping function has been proposed. In this work, we propose shallow discriminator architectures to address limitations of these approaches. We show that a smaller receptive field size improves learning of unknown image distortions by more accurately reproducing local distortion characteristics at a low network complexity. In a domain adaptation setup for instance segmentation, we achieve mean average precision increases over previous methods of up to 0.15 for individual distortions and up to 0.16 for camera-specific image characteristics in a simplified camera model. In terms of number of parameters, our approach matches the complexity of one state of the art method while reducing complexity by a factor of 20 compared to another, demonstrating superior efficiency without compromising performance.
A High-Level Feature Model to Predict the Encoding Energy of a Hardware Video Encoder
Oct 14, 2025In today's society, live video streaming and user generated content streamed from battery powered devices are ubiquitous. Live streaming requires real-time video encoding, and hardware video encoders are well suited for such an encoding task. In this paper, we introduce a high-level feature model using Gaussian process regression that can predict the encoding energy of a hardware video encoder. In an evaluation setup restricted to only P-frames and a single keyframe, the model can predict the encoding energy with a mean absolute percentage error of approximately 9%. Further, we demonstrate with an ablation study that spatial resolution is a key high-level feature for encoding energy prediction of a hardware encoder. A practical application of our model is that it can be used to perform a prior estimation of the energy required to encode a video at various spatial resolutions, with different coding standards and codec presets.
Lossless 4:2:0 Screen Content Coding Using Luma-Guided Soft Context Formation
Aug 26, 2025The soft context formation coder is a pixel-wise state-of-the-art lossless screen content coder using pattern matching and color palette coding in combination with arithmetic coding. It achieves excellent compression performance on screen content images in RGB 4:4:4 format with few distinct colors. In contrast to many other lossless compression methods, it codes entire color pixels at once, i.e., all color components of one pixel are coded together. Consequently, it does not natively support image formats with downsampled chroma, such as YCbCr 4:2:0, which is an often used chroma format in video compression. In this paper, we extend the soft context formation coding capabilities to 4:2:0 image compression, by successively coding Y and CbCr planes based on an analysis of normalized mutual information between image planes. Additionally, we propose an enhancement to the chroma prediction based on the luminance plane. Furthermore, we propose to transmit side-information about occurring luma-chroma combinations to improve chroma probability distribution modelling. Averaged over a large screen content image dataset, our proposed method outperforms HEVC-SCC, with HEVC-SCC needing 5.66% more bitrate compared to our method.
LoC-LIC: Low Complexity Learned Image Coding Using Hierarchical Feature Transforms
Apr 30, 2025Current learned image compression models typically exhibit high complexity, which demands significant computational resources. To overcome these challenges, we propose an innovative approach that employs hierarchical feature extraction transforms to significantly reduce complexity while preserving bit rate reduction efficiency. Our novel architecture achieves this by using fewer channels for high spatial resolution inputs/feature maps. On the other hand, feature maps with a large number of channels have reduced spatial dimensions, thereby cutting down on computational load without sacrificing performance. This strategy effectively reduces the forward pass complexity from \(1256 \, \text{kMAC/Pixel}\) to just \(270 \, \text{kMAC/Pixel}\). As a result, the reduced complexity model can open the way for learned image compression models to operate efficiently across various devices and pave the way for the development of new architectures in image compression technology.
Improved Motion Plane Adaptive 360-Degree Video Compression Using Affine Motion Models
Mar 29, 2025



Efficient compression of 360-degree video content requires the application of advanced motion models for interframe prediction. The Motion Plane Adaptive (MPA) motion model projects the frames on multiple perspective planes in the 3D space. It improves the motion compensation by estimating the motion on those planes with a translational diamond search. In this work, we enhance this motion model with an affine parameterization and motion estimation method. Thereby, we find a feasible trade-off between the quality of the reconstructed frames and the computational cost. The affine motion estimation is hereby done with the inverse compositional Lucas-Kanade algorithm. With the proposed method, it is possible to improve the motion compensation significantly, so that the motion compensated frame has a Weighted-to-Spherically-uniform Peak Signal-to-Noise Ratio (WS-PSNR) which is about 1.6 dB higher than with the conventional MPA. In a basic video codec, the improved inter prediction can lead to Bj{\o}ntegaard Delta (BD) rate savings between 9 % and 35 % depending on the block size (BS) and number of motion parameters.