 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Scaling in Masked Diffusion Models
Jun 16, 2026Masked diffusion models (MDMs) have recently emerged as a promising paradigm for sequence generation. Scaling MDMs is conventionally achieved by increasing the parameter count or the number of denoising steps. We introduce Recursive Masked Diffusion Models (R-MDMs), which add recursive depth as a third scaling axis by repeatedly applying the same denoising transformer within each diffusion step. Recursion enables iterative refinement of the output through parameter reuse, increasing effective model depth without increasing parameter count. Across structured generation tasks, including Sudoku and Countdown, we show that R-MDMs achieve substantially improved parameter efficiency: a model with $L$ recursive iterations often matches the performance of non-recursive baselines with roughly $L\times$ more parameters. Moreover, recursive refinement can partially substitute for additional denoising steps, allowing recursive models to reach the same generation quality with fewer forward passes at inference time. These results suggest that recursive depth is a practically useful scaling mechanism for MDMs, improving both parameter efficiency and the allocation of test-time compute.
PriFT: Prior-Support Guided Supervised Fine-Tuning
Jun 08, 2026Supervised fine-tuning (SFT) is an efficient approach for downstream task adaptation and often serves as the initialization stage for reinforcement learning (RL), but it can show weaker generalization than RL. A key limitation is its off-policy objective: SFT fits fixed demonstrations token by token, including targets poorly aligned with the model's pretrained distribution, which can lead to overfitting. A recent line of work addresses this issue by assigning larger training weights to tokens better aligned with the current model's predictive distribution, with the intuition that fitting these tokens are less distortive to the model's pretrained knowledge and representations. However, computing the token weights from the model that is currently fine-tuned entangles token weights with the optimization trajectory, inducing a self-reinforcing dynamics as the distribution rapidly departs from the pretrained model. To address this, we propose PriFT (Prior-support guided Fine-Tuning), which derives token weights from a frozen pretrained reference to obtain a stable reweighting signal unaffected by fine-tuning. This signal estimates prior support: the extent to which each target token is supported by the pretrained distribution. Across multiple existing token-reweighting rules, replacing the reweighting signal from the online model to pretrained model consistently improves performance. We introduce two instantiations: PriFT-prob uses pretrained token probability, while PriFT-mass selects tokens by cumulative probability mass under the pretrained distribution. Extensive experiments on mathematical reasoning, code generation, and medical question answering show that PriFT achieves state-of-the-art results among SFT baselines and provides a better initialization for subsequent RL training.
Geodesics of Dynamic Graphs for Regime Change Detection
Jun 05, 2026Traditional change point detection in dynamic networks assumes abrupt transitions between stationary states, overlooking scenarios of continuous evolution which arise in most real-world applications, such as social networks or physical systems. We address this gap by formally defining regimes as periods of coherent dynamics in temporal graphs, which we characterize as trajectories along geodesics in a suitably defined graph space. This original perspective allows us to define regime changes as significant drifts in dynamics, either toward new trajectories or with pace changes. We leverage graph regression methods to measure the cumulative distance of sequences of observed graphs from the estimated geodesics between their endpoints, in the relevant graph space, which we can combine with change point detection algorithms. We present experiments on dynamic networks, with changing trajectories and varying speeds, in which we outperform state of the art change point detection models. Then, we analyse mobility data during the Covid-19 pandemic, and show that our assumptions on regular network evolution lead to change points that are more aligned to external events compared to the outcomes of baseline methods. Our work is the first to model and detect changes between evolving regimes in graph space, providing a realistic and powerful tool for analyzing complex temporal graph data.
RePercENT: Scaling Disentangled Representation Learning Beyond Two Modalities
Jun 03, 2026To leverage the full potential of multimodal data, we need representations that go beyond the state-of-the-art alignment and fusion approaches and exploit all cross-modal interactions without sacrificing modality-specific information. Learning disentangled representations is a principled way to identify these underlying shared and unique factors that are hidden in observational data. However, while multimodal disentanglement is a compelling paradigm, existing methods are largely confined to the two-modality regime due to its inherent scalability bottleneck. To address this, we propose RePercENT, a self-supervised framework designed to surpass these limitations and unlocks scalable pairwise disentanglement beyond two modalities. Through a multimodal `plug-and-play' architecture, our approach operates directly on pre-extracted embeddings, eliminating the need for extensive joint pre-training while making no assumptions regarding the underlying modalities or foundation model backbones. Moreover, we introduce a joint optimization objective for simultaneously deriving the shared and unique components, and provide formal theoretical guarantees that characterize the optimality of our solution. Across diverse modalities and tasks, RePercENT successfully recovers disentangled components while maintaining competitive performance and significantly reducing computational complexity.
Fixed-Point Masked Generative Modeling
May 29, 2026Masked Generative Models (MGMs) enable parallel decoding and achieve strong performance across modalities, but require full-sequence bidirectional transformers at every step, making training costly and degrading quality under low sampling budgets. Existing work improves efficiency via better samplers or cheaper fixed-depth denoisers, but they still allocate a fixed amount of denoiser computation to each refinement step. We introduce Fixed-Point Masked Generative Models (FP-MGMs), which replace part of the denoiser with a fixed-point solver over shared attention layers to enable adaptive depth with fewer parameters. To make it more effective for masked generation, we first introduce a cross-step consistency loss, which aligns hidden representations at neighboring denoising steps and, second, three-state reuse (3SR) which warm-starts the solver using the previous solution by treating differently unchanged, still-masked, and newly revealed tokens respectively. Together, these components define our complete training-to-inference framework for fixed-point masked generation, \emph{CoFRe}. We also show that pre-trained MGMs can be converted into FP-MGMs with short fine-tuning, avoiding full retraining. Across modalities, CoFRe improves the quality and cost trade-off. On OpenWebText, CoFRe reduces parameters by 38.8\%, training time by 11.5\%, and VRAM by 16.9\%, while improving generative perplexity from 830.8 to 101.8 at a budget of $96$ transformer-block forward passes, compared to MDLM. In ImageNette, CoFRe reduces training time by 48.6\% and VRAM by 50.7\%, while improving FID in all sample budgets tested. Overall, CoFRe offers a practical framework for cheaper training and stronger low-budget masked generation.
ODySSeI: An Open-Source End-to-End Framework for Automated Detection, Segmentation, and Severity Estimation of Lesions in Invasive Coronary Angiography Images
Mar 20, 2026Invasive Coronary Angiography (ICA) is the clinical gold standard for the assessment of coronary artery disease. However, its interpretation remains subjective and prone to intra- and inter-operator variability. In this work, we introduce ODySSeI: an Open-source end-to-end framework for automated Detection, Segmentation, and Severity estimation of lesions in ICA images. ODySSeI integrates deep learning-based lesion detection and lesion segmentation models trained using a novel Pyramidal Augmentation Scheme (PAS) to enhance robustness and real-time performance across diverse patient cohorts (2149 patients from Europe, North America, and Asia). Furthermore, we propose a quantitative coronary angiography-free Lesion Severity Estimation (LSE) technique that directly computes the Minimum Lumen Diameter (MLD) and diameter stenosis from the predicted lesion geometry. Extensive evaluation on both in-distribution and out-of-distribution clinical datasets demonstrates ODySSeI's strong generalizability. Our PAS yields large performance gains in highly complex tasks as compared to relatively simpler ones, notably, a 2.5-fold increase in lesion detection performance versus a 1-3\% increase in lesion segmentation performance over their respective baselines. Our LSE technique achieves high accuracy, with predicted MLD values differing by only $\pm$ 2-3 pixels from the corresponding ground truths. On average, ODySSeI processes a raw ICA image within only a few seconds on a CPU and in a fraction of a second on a GPU and is available as a plug-and-play web interface at swisscardia.epfl.ch. Overall, this work establishes ODySSeI as a comprehensive and open-source framework which supports automated, reproducible, and scalable ICA analysis for real-time clinical decision-making.
Position: Message-passing and spectral GNNs are two sides of the same coin
Feb 10, 2026Graph neural networks (GNNs) are commonly divided into message-passing neural networks (MPNNs) and spectral graph neural networks, reflecting two largely separate research traditions in machine learning and signal processing. This paper argues that this divide is mostly artificial, hindering progress in the field. We propose a viewpoint in which both MPNNs and spectral GNNs are understood as different parametrizations of permutation-equivariant operators acting on graph signals. From this perspective, many popular architectures are equivalent in expressive power, while genuine gaps arise only in specific regimes. We further argue that MPNNs and spectral GNNs offer complementary strengths. That is, MPNNs provide a natural language for discrete structure and expressivity analysis using tools from logic and graph isomorphism research, while the spectral perspective provides principled tools for understanding smoothing, bottlenecks, stability, and community structure. Overall, we posit that progress in graph learning will be accelerated by clearly understanding the key similarities and differences between these two types of GNNs, and by working towards unifying these perspectives within a common theoretical and conceptual framework rather than treating them as competing paradigms.
Model soups need only one ingredient
Feb 10, 2026Fine-tuning large pre-trained models on a target distribution often improves in-distribution (ID) accuracy, but at the cost of out-of-distribution (OOD) robustness as representations specialize to the fine-tuning data. Weight-space ensembling methods, such as Model Soups, mitigate this effect by averaging multiple checkpoints, but they are computationally prohibitive, requiring the training and storage of dozens of fine-tuned models. In this paper, we introduce MonoSoup, a simple, data-free, hyperparameter-free, post-hoc method that achieves a strong ID-OOD balance using only a single checkpoint. Our method applies Singular Value Decomposition (SVD) to each layer's update and decomposes it into high-energy directions that capture task-specific adaptation and low-energy directions that introduce noise but may still encode residual signals useful for robustness. MonoSoup then uses entropy-based effective rank to automatically re-weigh these components with layer-wise coefficients that account for the spectral and geometric structure of the model. Experiments on CLIP models fine-tuned on ImageNet and evaluated under natural distribution shifts, as well as on Qwen language models tested on mathematical reasoning and multiple-choice benchmarks, show that this plug-and-play approach is a practical and effective alternative to multi-checkpoint methods, retaining much of their benefits without their computational overhead.
Task Addition and Weight Disentanglement in Closed-Vocabulary Models
Nov 18, 2025Task arithmetic has recently emerged as a promising method for editing pre-trained \textit{open-vocabulary} models, offering a cost-effective alternative to standard multi-task fine-tuning. However, despite the abundance of \textit{closed-vocabulary} models that are not pre-trained with language supervision, applying task arithmetic to these models remains unexplored. In this paper, we deploy and study task addition in closed-vocabulary image classification models. We consider different pre-training schemes and find that \textit{weight disentanglement} -- the property enabling task arithmetic -- is a general consequence of pre-training, as it appears in different pre-trained closed-vocabulary models. In fact, we find that pre-trained closed-vocabulary vision transformers can also be edited with task arithmetic, achieving high task addition performance and enabling the efficient deployment of multi-task models. Finally, we demonstrate that simple linear probing is a competitive baseline to task addition. Overall, our findings expand the applicability of task arithmetic to a broader class of pre-trained models and open the way for more efficient use of pre-trained models in diverse settings.
Semantic Document Derendering: SVG Reconstruction via Vision-Language Modeling
Nov 17, 2025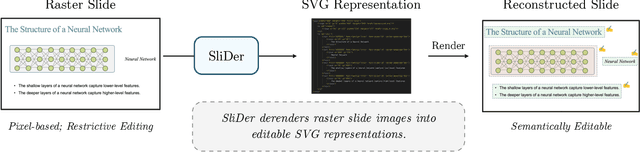
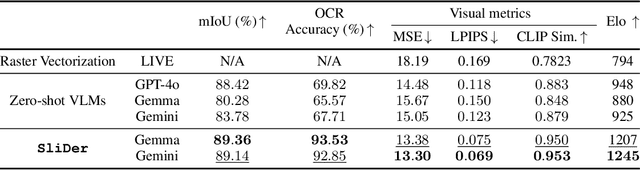
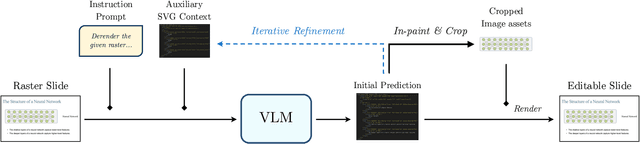
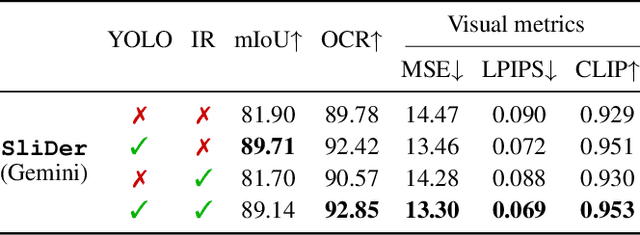
Multimedia documents such as slide presentations and posters are designed to be interactive and easy to modify. Yet, they are often distributed in a static raster format, which limits editing and customization. Restoring their editability requires converting these raster images back into structured vector formats. However, existing geometric raster-vectorization methods, which rely on low-level primitives like curves and polygons, fall short at this task. Specifically, when applied to complex documents like slides, they fail to preserve the high-level structure, resulting in a flat collection of shapes where the semantic distinction between image and text elements is lost. To overcome this limitation, we address the problem of semantic document derendering by introducing SliDer, a novel framework that uses Vision-Language Models (VLMs) to derender slide images as compact and editable Scalable Vector Graphic (SVG) representations. SliDer detects and extracts attributes from individual image and text elements in a raster input and organizes them into a coherent SVG format. Crucially, the model iteratively refines its predictions during inference in a process analogous to human design, generating SVG code that more faithfully reconstructs the original raster upon rendering. Furthermore, we introduce Slide2SVG, a novel dataset comprising raster-SVG pairs of slide documents curated from real-world scientific presentations, to facilitate future research in this domain. Our results demonstrate that SliDer achieves a reconstruction LPIPS of 0.069 and is favored by human evaluators in 82.9% of cases compared to the strongest zero-shot VLM baseline.