 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSLO-IC: On-the-Sphere Learned Omnidirectional Image Compression with Attention Modules and Spatial Context
Mar 17, 2025
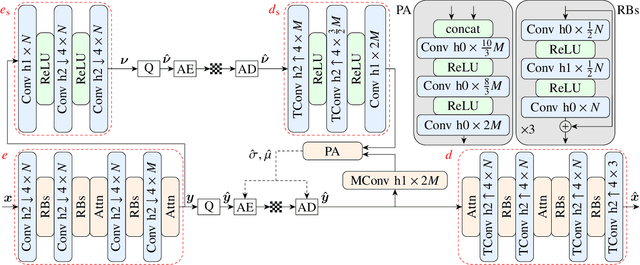
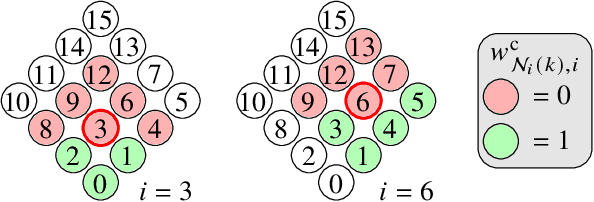
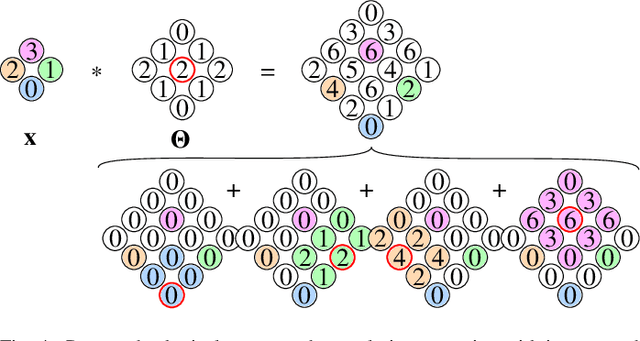
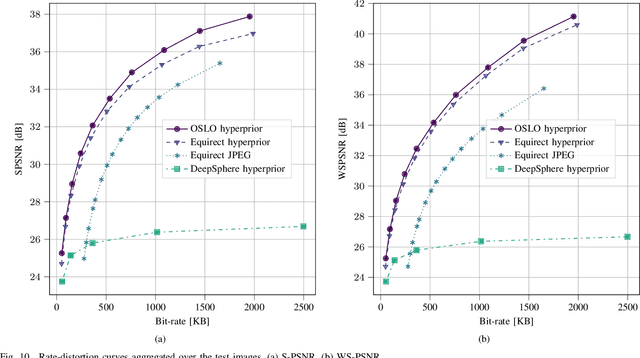
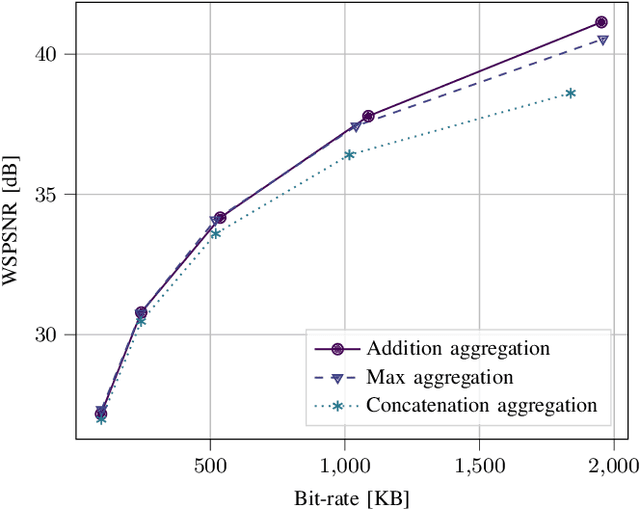
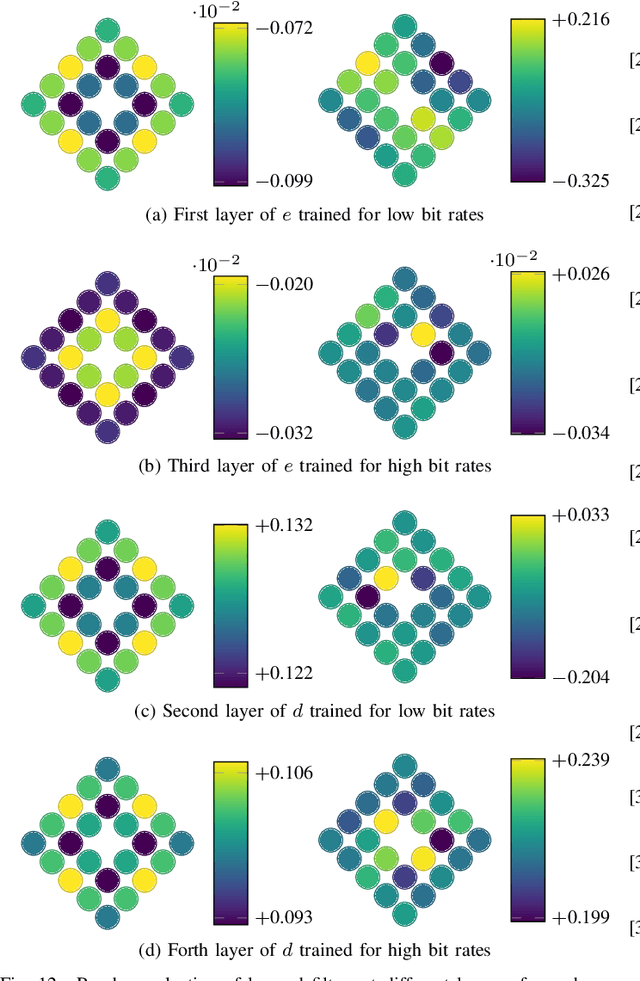
Developing effective 360-degree (spherical) image compression techniques is crucial for technologies like virtual reality and automated driving. This paper advances the state-of-the-art in on-the-sphere learning (OSLO) for omnidirectional image compression framework by proposing spherical attention modules, residual blocks, and a spatial autoregressive context model. These improvements achieve a 23.1% bit rate reduction in terms of WS-PSNR BD rate. Additionally, we introduce a spherical transposed convolution operator for upsampling, which reduces trainable parameters by a factor of four compared to the pixel shuffling used in the OSLO framework, while maintaining similar compression performance. Therefore, in total, our proposed method offers significant rate savings with a smaller architecture and can be applied to any spherical convolutional application.
OSLO: On-the-Sphere Learning for Omnidirectional images and its application to 360-degree image compression
Jul 19, 2021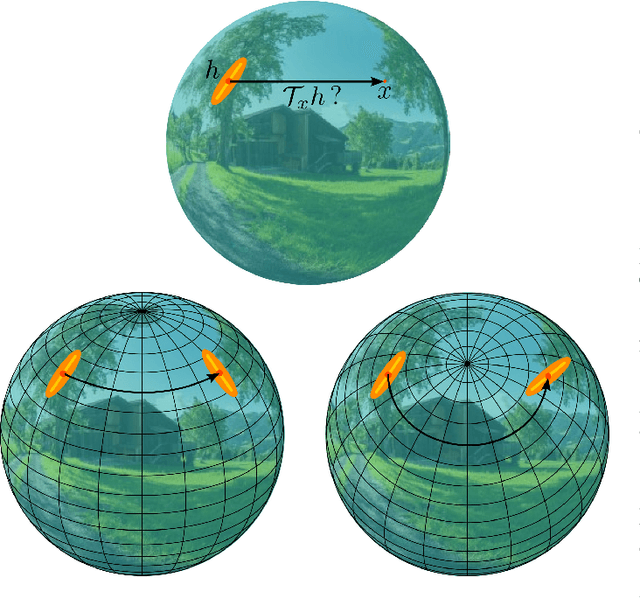
State-of-the-art 2D image compression schemes rely on the power of convolutional neural networks (CNNs). Although CNNs offer promising perspectives for 2D image compression, extending such models to omnidirectional images is not straightforward. First, omnidirectional images have specific spatial and statistical properties that can not be fully captured by current CNN models. Second, basic mathematical operations composing a CNN architecture, e.g., translation and sampling, are not well-defined on the sphere. In this paper, we study the learning of representation models for omnidirectional images and propose to use the properties of HEALPix uniform sampling of the sphere to redefine the mathematical tools used in deep learning models for omnidirectional images. In particular, we: i) propose the definition of a new convolution operation on the sphere that keeps the high expressiveness and the low complexity of a classical 2D convolution; ii) adapt standard CNN techniques such as stride, iterative aggregation, and pixel shuffling to the spherical domain; and then iii) apply our new framework to the task of omnidirectional image compression. Our experiments show that our proposed on-the-sphere solution leads to a better compression gain that can save 13.7% of the bit rate compared to similar learned models applied to equirectangular images. Also, compared to learning models based on graph convolutional networks, our solution supports more expressive filters that can preserve high frequencies and provide a better perceptual quality of the compressed images. Such results demonstrate the efficiency of the proposed framework, which opens new research venues for other omnidirectional vision tasks to be effectively implemented on the sphere manifold.
Fine granularity access in interactive compression of 360-degree images based on rate adaptive channel codes
Jun 25, 2020
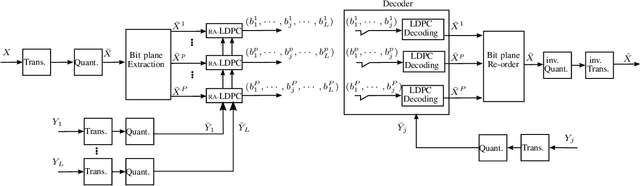

In this paper, we propose a new interactive compression scheme for omnidirectional images. This requires two characteristics: efficient compression of data, to lower the storage cost, and random access ability to extract part of the compressed stream requested by the user (for reducing the transmission rate). For efficient compression, data needs to be predicted by a series of references that have been pre-defined and compressed. This contrasts with the spirit of random accessibility. We propose a solution for this problem based on incremental codes implemented by rate adaptive channel codes. This scheme encodes the image while adapting to any user request and leads to an efficient coding that is flexible in extracting data depending on the available information at the decoder. Therefore, only the information that is needed to be displayed at the user's side is transmitted during the user's request as if the request was already known at the encoder. The experimental results demonstrate that our coder obtains better transmission rate than the state-of-the-art tile-based methods at a small cost in storage. Moreover, the transmission rate grows gradually with the size of the request and avoids a staircase effect, which shows the perfect suitability of our coder for interactive transmission.
A location-aware embedding technique for accurate landmark recognition
Apr 19, 2017


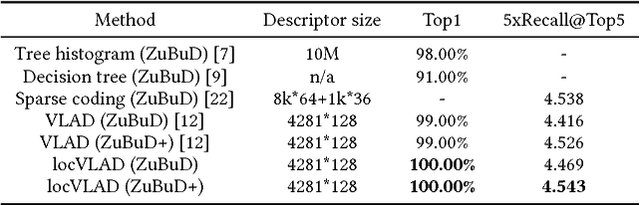
The current state of the research in landmark recognition highlights the good accuracy which can be achieved by embedding techniques, such as Fisher vector and VLAD. All these techniques do not exploit spatial information, i.e. consider all the features and the corresponding descriptors without embedding their location in the image. This paper presents a new variant of the well-known VLAD (Vector of Locally Aggregated Descriptors) embedding technique which accounts, at a certain degree, for the location of features. The driving motivation comes from the observation that, usually, the most interesting part of an image (e.g., the landmark to be recognized) is almost at the center of the image, while the features at the borders are irrelevant features which do no depend on the landmark. The proposed variant, called locVLAD (location-aware VLAD), computes the mean of the two global descriptors: the VLAD executed on the entire original image, and the one computed on a cropped image which removes a certain percentage of the image borders. This simple variant shows an accuracy greater than the existing state-of-the-art approach. Experiments are conducted on two public datasets (ZuBuD and Holidays) which are used both for training and testing. Morever a more balanced version of ZuBuD is proposed.