 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenetic Algorithms for the Optimization of Diffusion Parameters in Content-Based Image Retrieval
Aug 19, 2019
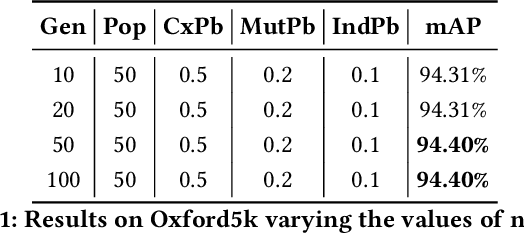
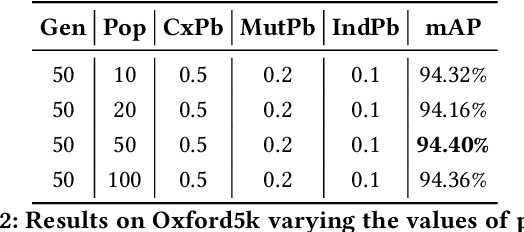
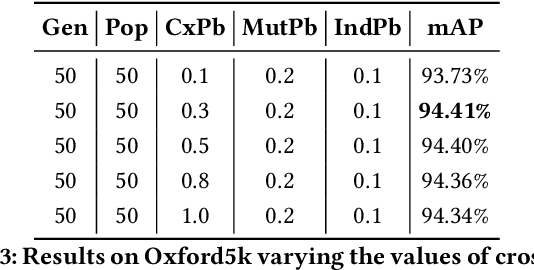
Several computer vision and artificial intelligence projects are nowadays exploiting the manifold data distribution using, e.g., the diffusion process. This approach has produced dramatic improvements on the final performance thanks to the application of such algorithms to the kNN graph. Unfortunately, this recent technique needs a manual configuration of several parameters, thus it is not straightforward to find the best configuration for each dataset. Moreover, the brute-force approach is computationally very demanding when used to optimally set the parameters of the diffusion approach. We propose to use genetic algorithms to find the optimal setting of all the diffusion parameters with respect to retrieval performance for each different dataset. Our approach is faster than others used as references (brute-force, random-search and PSO). A comparison with these methods has been made on three public image datasets: Oxford5k, Paris6k and Oxford105k.
An Efficient Approximate kNN Graph Method for Diffusion on Image Retrieval
Apr 18, 2019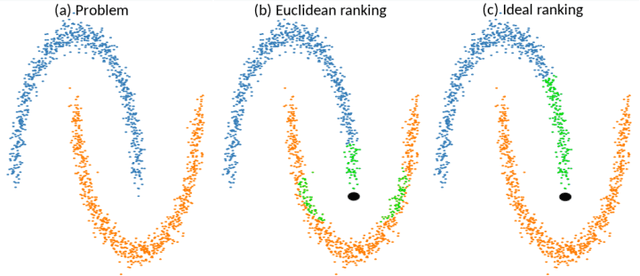
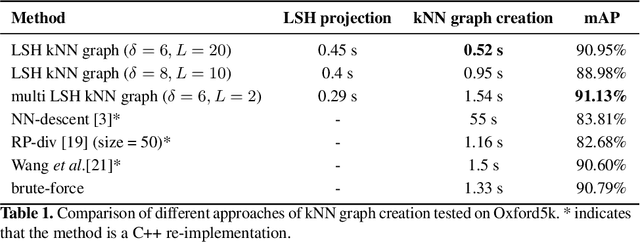
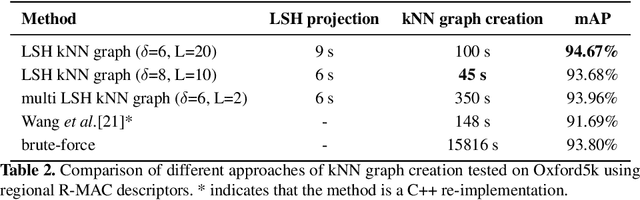

The application of the diffusion in many computer vision and artificial intelligence projects has been shown to give excellent improvements in performance. One of the main bottlenecks of this technique is the quadratic growth of the kNN graph size due to the high-quantity of new connections between nodes in the graph, resulting in long computation times. Several strategies have been proposed to address this, but none are effective and efficient. Our novel technique, based on LSH projections, obtains the same performance as the exact kNN graph after diffusion, but in less time (approximately 18 times faster on a dataset of a hundred thousand images). The proposed method was validated and compared with other state-of-the-art on several public image datasets, including Oxford5k, Paris6k, and Oxford105k.
A Dense-Depth Representation for VLAD descriptors in Content-Based Image Retrieval
Aug 15, 2018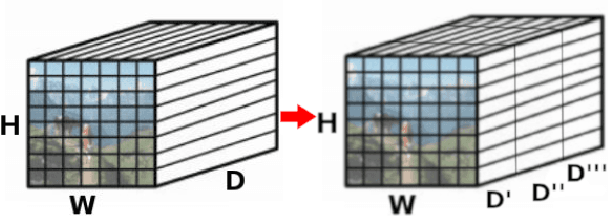
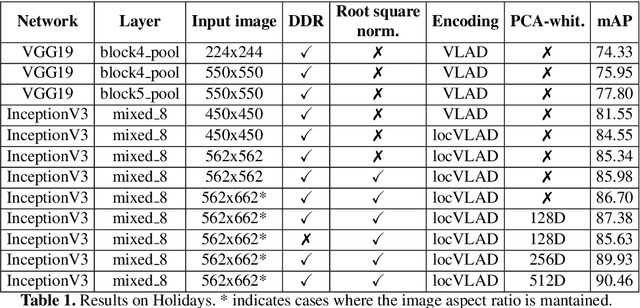
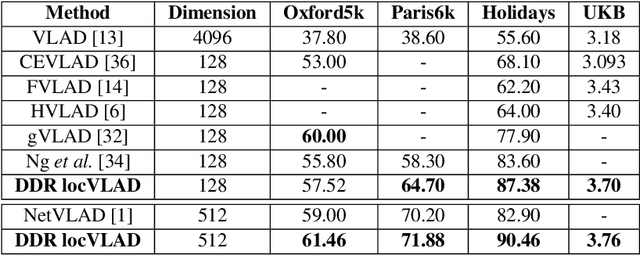
The recent advances brought by deep learning allowed to improve the performance in image retrieval tasks. Through the many convolutional layers, available in a Convolutional Neural Network (CNN), it is possible to obtain a hierarchy of features from the evaluated image. At every step, the patches extracted are smaller than the previous levels and more representative. Following this idea, this paper introduces a new detector applied on the feature maps extracted from pre-trained CNN. Specifically, this approach lets to increase the number of features in order to increase the performance of the aggregation algorithms like the most famous and used VLAD embedding. The proposed approach is tested on different public datasets: Holidays, Oxford5k, Paris6k and UKB.
An accurate retrieval through R-MAC+ descriptors for landmark recognition
Jun 22, 2018
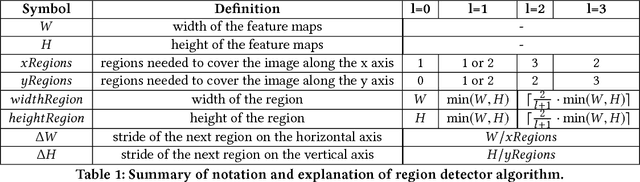
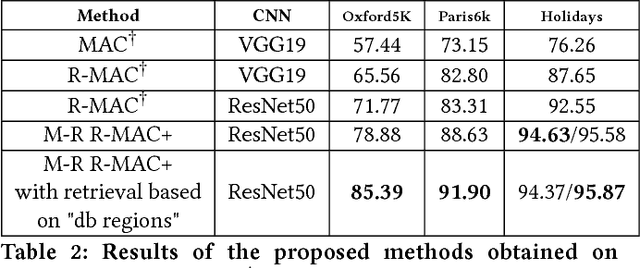
The landmark recognition problem is far from being solved, but with the use of features extracted from intermediate layers of Convolutional Neural Networks (CNNs), excellent results have been obtained. In this work, we propose some improvements on the creation of R-MAC descriptors in order to make the newly-proposed R-MAC+ descriptors more representative than the previous ones. However, the main contribution of this paper is a novel retrieval technique, that exploits the fine representativeness of the MAC descriptors of the database images. Using this descriptors called "db regions" during the retrieval stage, the performance is greatly improved. The proposed method is tested on different public datasets: Oxford5k, Paris6k and Holidays. It outperforms the state-of-the- art results on Holidays and reached excellent results on Oxford5k and Paris6k, overcame only by approaches based on fine-tuning strategies.
Efficient Nearest Neighbors Search for Large-Scale Landmark Recognition
Jun 15, 2018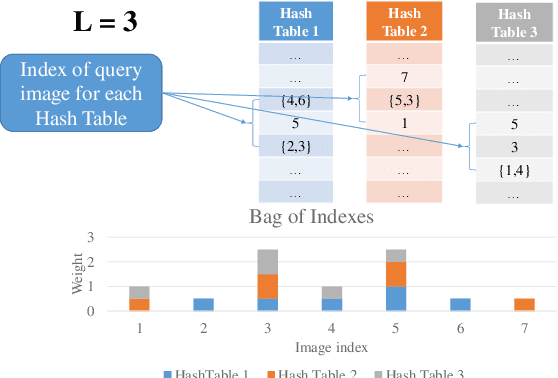
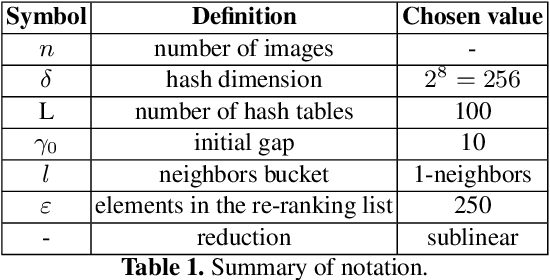
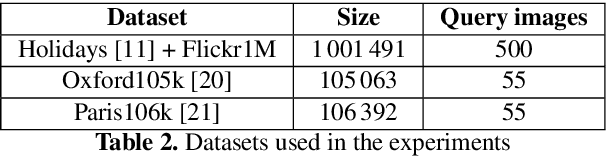
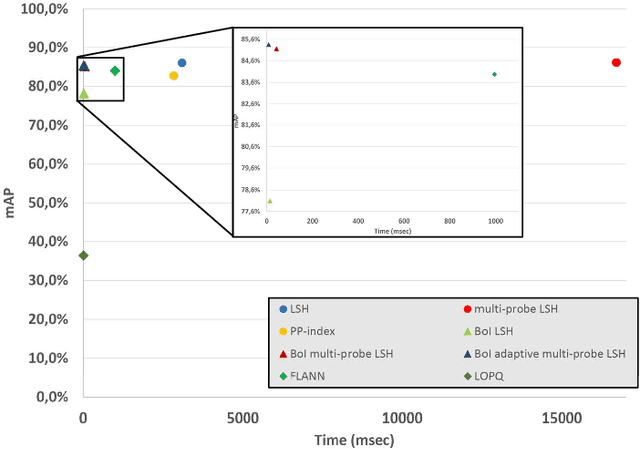
The problem of landmark recognition has achieved excellent results in small-scale datasets. When dealing with large-scale retrieval, issues that were irrelevant with small amount of data, quickly become fundamental for an efficient retrieval phase. In particular, computational time needs to be kept as low as possible, whilst the retrieval accuracy has to be preserved as much as possible. In this paper we propose a novel multi-index hashing method called Bag of Indexes (BoI) for Approximate Nearest Neighbors (ANN) search. It allows to drastically reduce the query time and outperforms the accuracy results compared to the state-of-the-art methods for large-scale landmark recognition. It has been demonstrated that this family of algorithms can be applied on different embedding techniques like VLAD and R-MAC obtaining excellent results in very short times on different public datasets: Holidays+Flickr1M, Oxford105k and Paris106k.
A location-aware embedding technique for accurate landmark recognition
Apr 19, 2017


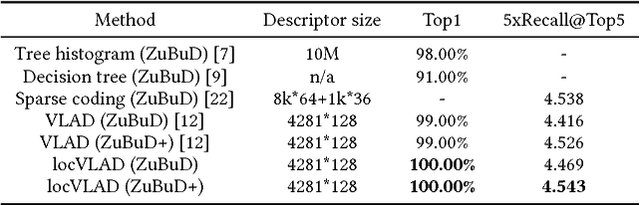
The current state of the research in landmark recognition highlights the good accuracy which can be achieved by embedding techniques, such as Fisher vector and VLAD. All these techniques do not exploit spatial information, i.e. consider all the features and the corresponding descriptors without embedding their location in the image. This paper presents a new variant of the well-known VLAD (Vector of Locally Aggregated Descriptors) embedding technique which accounts, at a certain degree, for the location of features. The driving motivation comes from the observation that, usually, the most interesting part of an image (e.g., the landmark to be recognized) is almost at the center of the image, while the features at the borders are irrelevant features which do no depend on the landmark. The proposed variant, called locVLAD (location-aware VLAD), computes the mean of the two global descriptors: the VLAD executed on the entire original image, and the one computed on a cropped image which removes a certain percentage of the image borders. This simple variant shows an accuracy greater than the existing state-of-the-art approach. Experiments are conducted on two public datasets (ZuBuD and Holidays) which are used both for training and testing. Morever a more balanced version of ZuBuD is proposed.