 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA location-aware embedding technique for accurate landmark recognition
Paper and Code
Apr 19, 2017


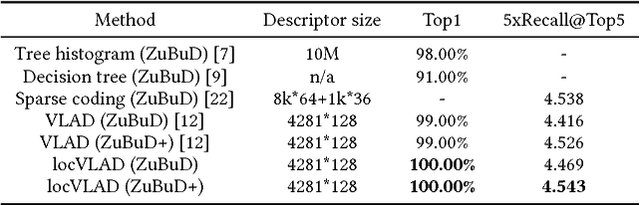
The current state of the research in landmark recognition highlights the good accuracy which can be achieved by embedding techniques, such as Fisher vector and VLAD. All these techniques do not exploit spatial information, i.e. consider all the features and the corresponding descriptors without embedding their location in the image. This paper presents a new variant of the well-known VLAD (Vector of Locally Aggregated Descriptors) embedding technique which accounts, at a certain degree, for the location of features. The driving motivation comes from the observation that, usually, the most interesting part of an image (e.g., the landmark to be recognized) is almost at the center of the image, while the features at the borders are irrelevant features which do no depend on the landmark. The proposed variant, called locVLAD (location-aware VLAD), computes the mean of the two global descriptors: the VLAD executed on the entire original image, and the one computed on a cropped image which removes a certain percentage of the image borders. This simple variant shows an accuracy greater than the existing state-of-the-art approach. Experiments are conducted on two public datasets (ZuBuD and Holidays) which are used both for training and testing. Morever a more balanced version of ZuBuD is proposed.