 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveMAE: Wavelet decomposition Masked Auto-Encoder for Remote Sensing
Oct 26, 2025Self-supervised learning (SSL) has recently emerged as a key strategy for building foundation models in remote sensing, where the scarcity of annotated data limits the applicability of fully supervised approaches. In this work, we introduce WaveMAE, a masked autoencoding framework tailored for multispectral satellite imagery. Unlike conventional pixel-based reconstruction, WaveMAE leverages a multi-level Discrete Wavelet Transform (DWT) to disentangle frequency components and guide the encoder toward learning scale-aware high-frequency representations. We further propose a Geo-conditioned Positional Encoding (GPE), which incorporates geographical priors via Spherical Harmonics, encouraging embeddings that respect both semantic and geospatial structure. To ensure fairness in evaluation, all methods are pretrained on the same dataset (fMoW-S2) and systematically evaluated on the diverse downstream tasks of the PANGAEA benchmark, spanning semantic segmentation, regression, change detection, and multilabel classification. Extensive experiments demonstrate that WaveMAE achieves consistent improvements over prior state-of-the-art approaches, with substantial gains on segmentation and regression benchmarks. The effectiveness of WaveMAE pretraining is further demonstrated by showing that even a lightweight variant, containing only 26.4% of the parameters, achieves state-of-the-art performance. Our results establish WaveMAE as a strong and geographically informed foundation model for multispectral remote sensing imagery.
U-Shape Mamba: State Space Model for faster diffusion
Apr 18, 2025Diffusion models have become the most popular approach for high-quality image generation, but their high computational cost still remains a significant challenge. To address this problem, we propose U-Shape Mamba (USM), a novel diffusion model that leverages Mamba-based layers within a U-Net-like hierarchical structure. By progressively reducing sequence length in the encoder and restoring it in the decoder through Mamba blocks, USM significantly lowers computational overhead while maintaining strong generative capabilities. Experimental results against Zigma, which is currently the most efficient Mamba-based diffusion model, demonstrate that USM achieves one-third the GFlops, requires less memory and is faster, while outperforming Zigma in image quality. Frechet Inception Distance (FID) is improved by 15.3, 0.84 and 2.7 points on AFHQ, CelebAHQ and COCO datasets, respectively. These findings highlight USM as a highly efficient and scalable solution for diffusion-based generative models, making high-quality image synthesis more accessible to the research community while reducing computational costs.
$^R$FLAV: Rolling Flow matching for infinite Audio Video generation
Mar 12, 2025Joint audio-video (AV) generation is still a significant challenge in generative AI, primarily due to three critical requirements: quality of the generated samples, seamless multimodal synchronization and temporal coherence, with audio tracks that match the visual data and vice versa, and limitless video duration. In this paper, we present $^R$-FLAV, a novel transformer-based architecture that addresses all the key challenges of AV generation. We explore three distinct cross modality interaction modules, with our lightweight temporal fusion module emerging as the most effective and computationally efficient approach for aligning audio and visual modalities. Our experimental results demonstrate that $^R$-FLAV outperforms existing state-of-the-art models in multimodal AV generation tasks. Our code and checkpoints are available at https://github.com/ErgastiAlex/R-FLAV.
MCGM: Mask Conditional Text-to-Image Generative Model
Oct 01, 2024


Recent advancements in generative models have revolutionized the field of artificial intelligence, enabling the creation of highly-realistic and detailed images. In this study, we propose a novel Mask Conditional Text-to-Image Generative Model (MCGM) that leverages the power of conditional diffusion models to generate pictures with specific poses. Our model builds upon the success of the Break-a-scene [1] model in generating new scenes using a single image with multiple subjects and incorporates a mask embedding injection that allows the conditioning of the generation process. By introducing this additional level of control, MCGM offers a flexible and intuitive approach for generating specific poses for one or more subjects learned from a single image, empowering users to influence the output based on their requirements. Through extensive experimentation and evaluation, we demonstrate the effectiveness of our proposed model in generating high-quality images that meet predefined mask conditions and improving the current Break-a-scene generative model.
Mamba-ST: State Space Model for Efficient Style Transfer
Sep 16, 2024
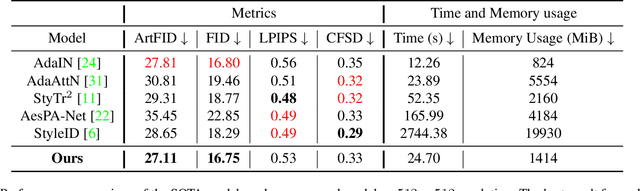
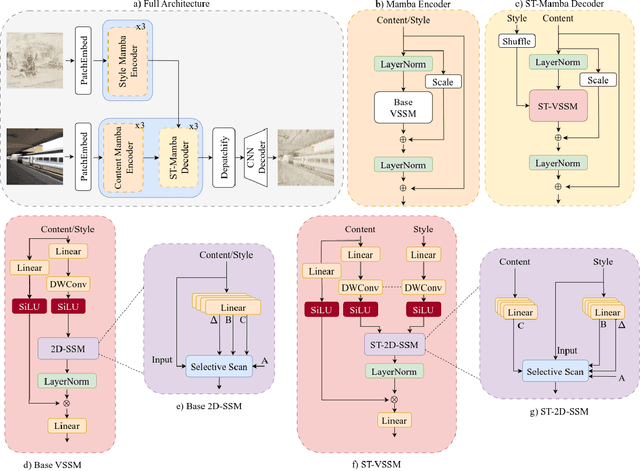
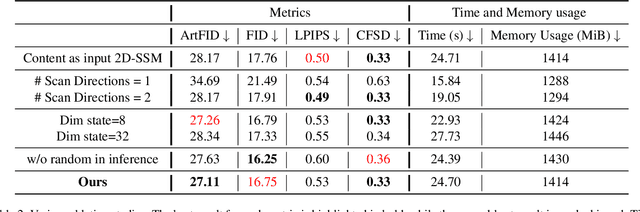
The goal of style transfer is, given a content image and a style source, generating a new image preserving the content but with the artistic representation of the style source. Most of the state-of-the-art architectures use transformers or diffusion-based models to perform this task, despite the heavy computational burden that they require. In particular, transformers use self- and cross-attention layers which have large memory footprint, while diffusion models require high inference time. To overcome the above, this paper explores a novel design of Mamba, an emergent State-Space Model (SSM), called Mamba-ST, to perform style transfer. To do so, we adapt Mamba linear equation to simulate the behavior of cross-attention layers, which are able to combine two separate embeddings into a single output, but drastically reducing memory usage and time complexity. We modified the Mamba's inner equations so to accept inputs from, and combine, two separate data streams. To the best of our knowledge, this is the first attempt to adapt the equations of SSMs to a vision task like style transfer without requiring any other module like cross-attention or custom normalization layers. An extensive set of experiments demonstrates the superiority and efficiency of our method in performing style transfer compared to transformers and diffusion models. Results show improved quality in terms of both ArtFID and FID metrics. Code is available at https://github.com/FilippoBotti/MambaST.
MARS: Paying more attention to visual attributes for text-based person search
Jul 05, 2024Text-based person search (TBPS) is a problem that gained significant interest within the research community. The task is that of retrieving one or more images of a specific individual based on a textual description. The multi-modal nature of the task requires learning representations that bridge text and image data within a shared latent space. Existing TBPS systems face two major challenges. One is defined as inter-identity noise that is due to the inherent vagueness and imprecision of text descriptions and it indicates how descriptions of visual attributes can be generally associated to different people; the other is the intra-identity variations, which are all those nuisances e.g. pose, illumination, that can alter the visual appearance of the same textual attributes for a given subject. To address these issues, this paper presents a novel TBPS architecture named MARS (Mae-Attribute-Relation-Sensitive), which enhances current state-of-the-art models by introducing two key components: a Visual Reconstruction Loss and an Attribute Loss. The former employs a Masked AutoEncoder trained to reconstruct randomly masked image patches with the aid of the textual description. In doing so the model is encouraged to learn more expressive representations and textual-visual relations in the latent space. The Attribute Loss, instead, balances the contribution of different types of attributes, defined as adjective-noun chunks of text. This loss ensures that every attribute is taken into consideration in the person retrieval process. Extensive experiments on three commonly used datasets, namely CUHK-PEDES, ICFG-PEDES, and RSTPReid, report performance improvements, with significant gains in the mean Average Precision (mAP) metric w.r.t. the current state of the art.
Swin2-MoSE: A New Single Image Super-Resolution Model for Remote Sensing
Apr 29, 2024
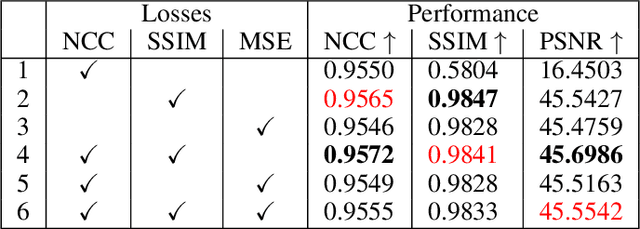
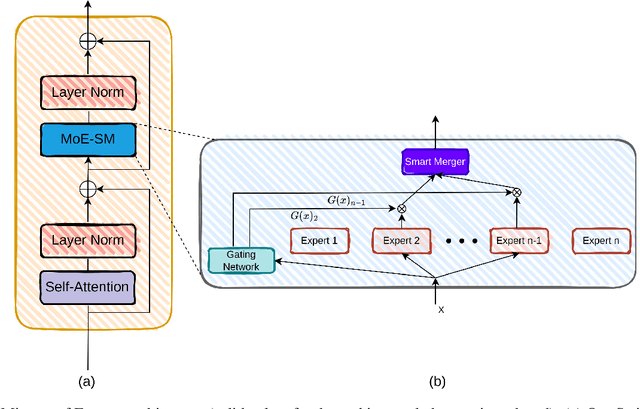
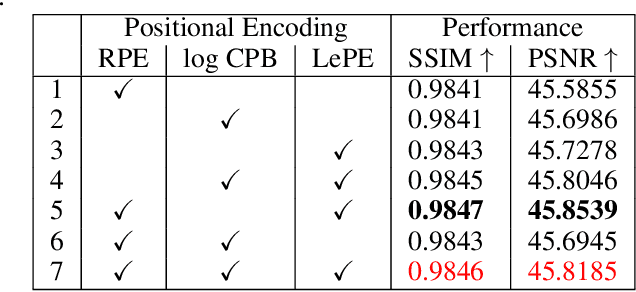
Due to the limitations of current optical and sensor technologies and the high cost of updating them, the spectral and spatial resolution of satellites may not always meet desired requirements. For these reasons, Remote-Sensing Single-Image Super-Resolution (RS-SISR) techniques have gained significant interest. In this paper, we propose Swin2-MoSE model, an enhanced version of Swin2SR. Our model introduces MoE-SM, an enhanced Mixture-of-Experts (MoE) to replace the Feed-Forward inside all Transformer block. MoE-SM is designed with Smart-Merger, and new layer for merging the output of individual experts, and with a new way to split the work between experts, defining a new per-example strategy instead of the commonly used per-token one. Furthermore, we analyze how positional encodings interact with each other, demonstrating that per-channel bias and per-head bias can positively cooperate. Finally, we propose to use a combination of Normalized-Cross-Correlation (NCC) and Structural Similarity Index Measure (SSIM) losses, to avoid typical MSE loss limitations. Experimental results demonstrate that Swin2-MoSE outperforms SOTA by up to 0.377 ~ 0.958 dB (PSNR) on task of 2x, 3x and 4x resolution-upscaling (Sen2Venus and OLI2MSI datasets). We show the efficacy of Swin2-MoSE, applying it to a semantic segmentation task (SeasoNet dataset). Code and pretrained are available on https://github.com/IMPLabUniPr/swin2-mose/tree/official_code
Adversarial Identity Injection for Semantic Face Image Synthesis
Apr 16, 2024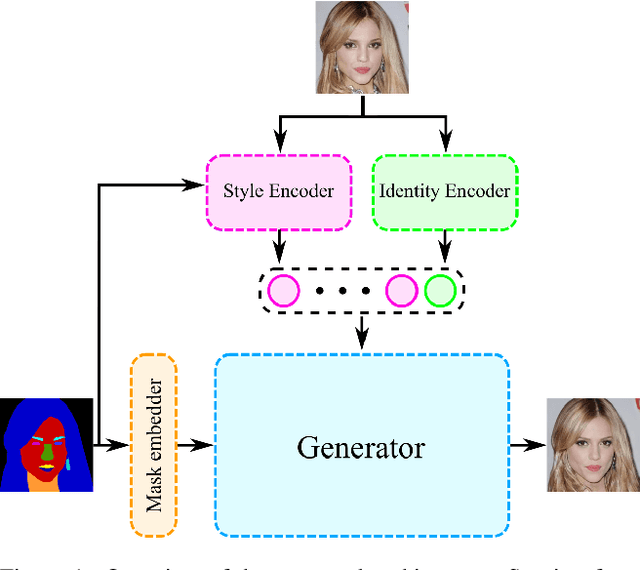
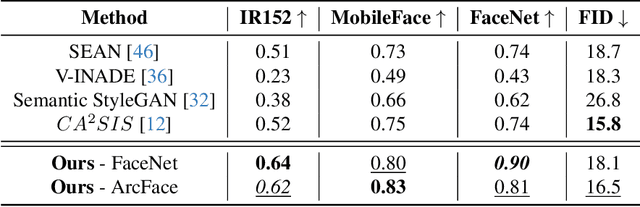

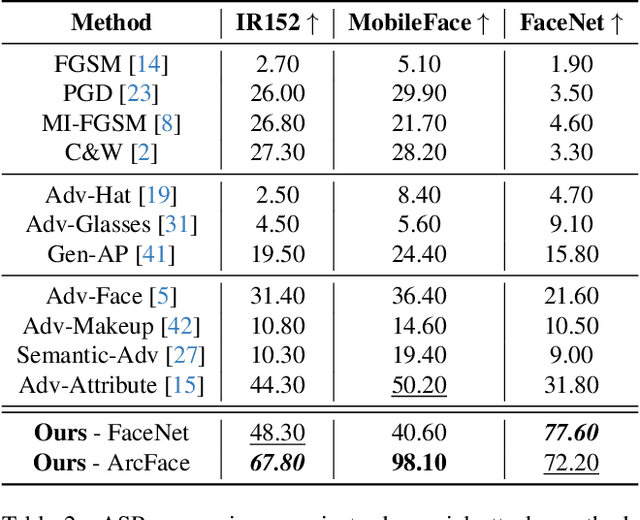
Nowadays, deep learning models have reached incredible performance in the task of image generation. Plenty of literature works address the task of face generation and editing, with human and automatic systems that struggle to distinguish what's real from generated. Whereas most systems reached excellent visual generation quality, they still face difficulties in preserving the identity of the starting input subject. Among all the explored techniques, Semantic Image Synthesis (SIS) methods, whose goal is to generate an image conditioned on a semantic segmentation mask, are the most promising, even though preserving the perceived identity of the input subject is not their main concern. Therefore, in this paper, we investigate the problem of identity preservation in face image generation and present an SIS architecture that exploits a cross-attention mechanism to merge identity, style, and semantic features to generate faces whose identities are as similar as possible to the input ones. Experimental results reveal that the proposed method is not only suitable for preserving the identity but is also effective in the face recognition adversarial attack, i.e. hiding a second identity in the generated faces.
Towards Controllable Face Generation with Semantic Latent Diffusion Models
Mar 19, 2024Semantic Image Synthesis (SIS) is among the most popular and effective techniques in the field of face generation and editing, thanks to its good generation quality and the versatility is brings along. Recent works attempted to go beyond the standard GAN-based framework, and started to explore Diffusion Models (DMs) for this task as these stand out with respect to GANs in terms of both quality and diversity. On the other hand, DMs lack in fine-grained controllability and reproducibility. To address that, in this paper we propose a SIS framework based on a novel Latent Diffusion Model architecture for human face generation and editing that is both able to reproduce and manipulate a real reference image and generate diversity-driven results. The proposed system utilizes both SPADE normalization and cross-attention layers to merge shape and style information and, by doing so, allows for a precise control over each of the semantic parts of the human face. This was not possible with previous methods in the state of the art. Finally, we performed an extensive set of experiments to prove that our model surpasses current state of the art, both qualitatively and quantitatively.
Semantic Image Synthesis via Class-Adaptive Cross-Attention
Aug 30, 2023In semantic image synthesis, the state of the art is dominated by methods that use spatially-adaptive normalization layers, which allow for excellent visual generation quality and editing versatility. Granted their efficacy, recent research efforts have focused toward finer-grained local style control and multi-modal generation. By construction though, such layers tend to overlook global image statistics leading to unconvincing local style editing and causing global inconsistencies such as color or illumination distribution shifts. Also, the semantic layout is required for mapping styles in the generator, putting a strict alignment constraint over the features. In response, we designed a novel architecture where cross-attention layers are used in place of de-normalization ones for conditioning the image generation. Our model inherits the advantages of both solutions, retaining state-of-the-art reconstruction quality, as well as improved global and local style transfer. Code and models available at https://github.com/TFonta/CA2SIS.